AI Job Info
1.0.0
Last updated: 2019/10/25
2019/08/21 - Updated catalog
2019/09/05 - Added 9 units
2019/09/21 - Update author information
2019/10/11 - Updated 10 plus face sutras
2019/10/25 - Update of Alibaba Damo Academy
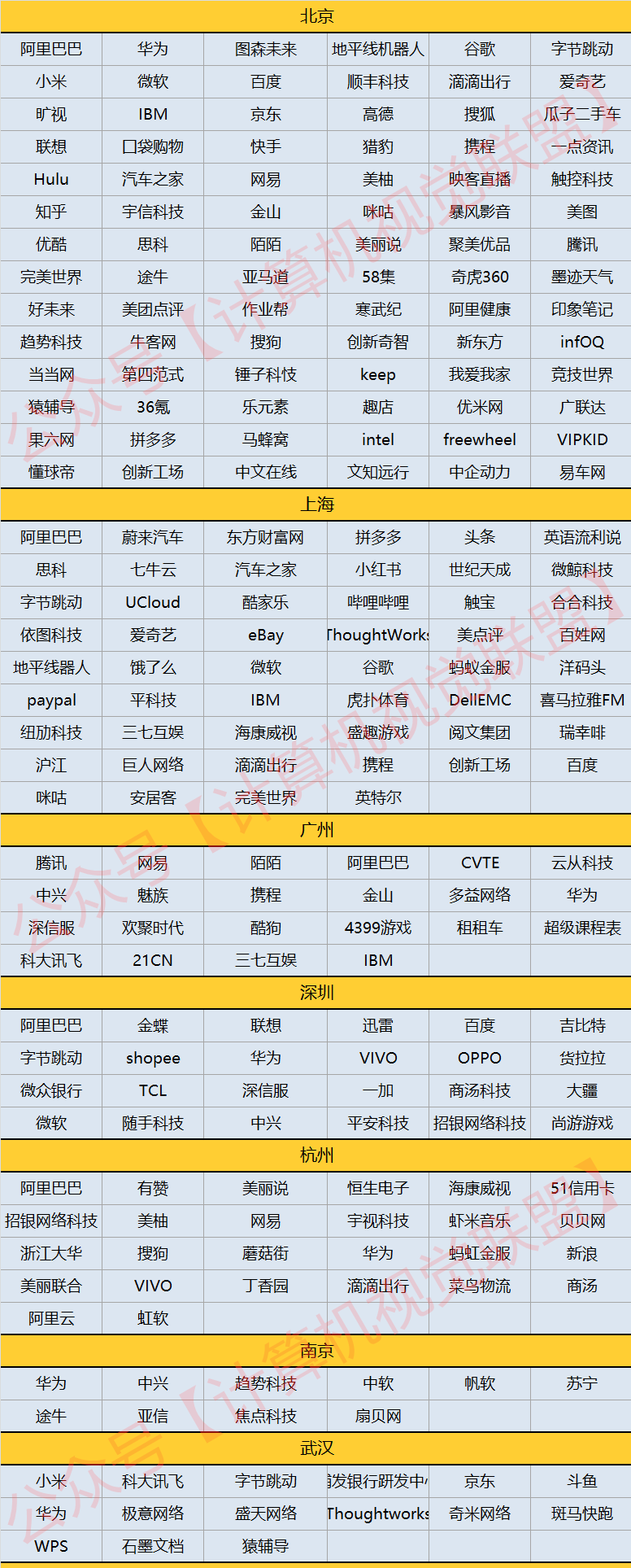
1. Overall overview of Huawei, DJI, Toutiao, Alibaba, Baidu, Alibaba, Tencent, JD.com, and Xiaomi
2. 2020 Tencent Computer Vision Algorithm Internship Interview for Bachelor’s and Master’s 985 Non-major Master’s Degrees
3. Baidu Computer Vision Summer Internship Interview
4. JD Computer Vision Internship Interview
5. Oppo approves C++ job interviews in advance
6. Midea approves Python data mining engineers in advance
7. Image algorithm intern at Momo Technology
8. Three aspects of Baidu’s front-end
9. Cambrian: Deep Learning Engineer
10. Home Page 2019.7.24
11. Baidu
12. Tencent
13. Pinduoduo2019.8.13
14. Mogu Street 2019.8.14
15. NetEase Interactive Entertainment game development
16. 360 Search (Ranking)-Machine Learning Engineer
17. NetEase Internet: Deep Learning Engineer
18. SF Express sp and ihandy special sales for cattle customers
19. Didi Niuke sp special session
20. Kuaishou Niuke sp special session
21. Yitu
22. Tencent
23. Vision
24. Baidu
25. Sogou
26. OPPO
27. 58 in the same city
28. Huawei
29. Alibaba Damo Academy
Notes
I have a bachelor's degree and a master's degree of 985 (the school has a lower ranking). I have average grades. I am not from a computer background and have done related CV projects. I feel a little guilty, but the boss has led several competitions.
Tencent Computer Vision Algorithm Jobs
Overall recall of the interview content, no matter which interview was held
No matter which interview it is, you will always introduce yourself first, describe your strengths for one minute, and sometimes briefly mention your views on the shortcomings.
Have you participated in relevant internships, what projects have you done, how many games have you played, and what positions have you played? Focusing on a game that I am familiar with, I will explain in detail the principles of the algorithm and the analysis of the game results. If I play the game again next time, how to improve my ranking. What is the gain from playing the game? What do you think is the difference between industry and scientific research?
Ordinary 985 master's degree, but without any internal recommendation, I got Baidu CV summer internship offer
It’s not too difficult, the interviewers are very nice, there are three rounds of interviews, resume-based projects, and then we start to expand.
Summary: My brother suggests focusing on the research of some underlying algorithms, data structures, decision trees, and implementation methods of common image processing algorithms.
Summary: Basically all the questions on both sides are about the project, and the other questions are to focus more on your ideas for solving problems and analyzing errors in your project.
Summary: The interviewers are relatively professional and have no airs. Don’t pretend to understand. If you don’t know, just say no.
Author: forward this beyond sister
Author: Shui Yi Shui
1. Self-introduction answer: A wave of routine operations, basic information + technical ability + soft power.
2. Tell us about the competitions or projects you participated in? Answer: The poster talked about a competition.
3. What are generally used for image models? Answer: The poster said that he mainly uses deep neural networks and talked about a project.
4. What models do you know about deep learning or machine learning? Answer: The original poster mentioned resnet in the project through deep learning. In machine learning, competitions generally use lgb and xgb, and some also use LR. I also used lsmt, rnn and the like in a previous competition. This kind of competition is suitable for this kind of competition. Natural language works better.
5. What databases have you used? Answer: I don’t use it much. I have used the RDS database of AWS, but I have learned all the SQL statements.
6. Now there is a table that allows you to insert and update. How to use SQL to implement it? Answer: insert and update.
7. What you just said are two statements. How to implement it with one statement? Answer: I was blank for a while and really didn’t think about it. The interviewer said that maybe you don't use it often. I said yes, the database is usually not large, and the requirement for the number of statements is not very strict.
8.What language do you mainly speak? python? Answer: Well, I use Python more recently, but the project I just enrolled in was actually done in C++.
9.What python packages do you mainly use? Answer: Sklern, numpy, pandas, and matplotlib for drawing pictures. I felt sluggish for a while and couldn’t think of anything else.
10.What is the index of pandas used for? Answer: The data is adjusted, which is somewhat similar to the primary key of the database (I don’t think I answered this well, I don’t know if the interviewer noticed it...)
11. What questions do you have for me? Answer: Does this position require high engineering skills? Or does it require high algorithmic capabilities? The interviewer said that you don't have to follow me. I was just arranged for an interview by the group. The author felt a little embarrassed. Then the interviewer said that the algorithm needs to be implemented anyway. Then the poster asked another question, that is, when applying for a position, I found that there are two departments, a group IT department and a Meiyun Intelligent Data. Is there a big difference between doing this position in these two departments? The interviewer answered for a while. . .
Author: EternityY
Author: Xiaoan, run! !
(1) The difference between WeChat Mini Program and Vue (because there is a project to make WeChat Mini Program)
(2) vuex principle of communication between Vue components
(3) Commonly used new features of ES6
(4) map and set structures
(5) Asynchronous request Promise and Async await
(6) Drawing a triangle using the principle of equipartition
(7) Draw a fan shape
(8) Animation implementation animation and requestAnimationFrame
(9) Do you know about pre-request Options fetch request? Cross domain
(10) web security
(11) How big are physical pixels and logical pixels such as 1px on the screen?
(12) box-sizing attribute
(13) The difference between TCP and UDP
(14) Do you understand binary tree traversal? How to traverse with preorder traversal. . .
(1) Introducing the project, Balabala asked a lot about the difficulties encountered (the solution used setTimeout, so the following Promise and Async/await were extended)
(2) Some features of ES6 and a difference between ES6 array methods
(3) What does the key value of the Set structure look like (unclear)
(4) Is there any other way to deduplicate arrays besides Set?
(5) What are asynchronous operations? Promise and Async/await
(6) Use Promise to encapsulate Ajax requests by calling this method to obtain the requested data through .then()
(7) What are the methods for sending requests? Such as Ajax
(8) Cross-domain: Why is there cross-domain? What is the same origin policy? How to solve cross-domain problem? Can resources be shared between parent domain and subdomain?
(9) Have you ever done a mobile terminal project? (I’ve done it but forgot about it) How to adapt to the mobile terminal
(10) Mobile terminal swiper and animation (I dug a hole for myself. I originally wanted to talk about it casually, but it turned out that they mainly work on mobile terminals) How to achieve the effect of sliding up to display the next page without using the swiper plug-in? What events are available on mobile?
(11) How to obtain page url parameters
(12) Event delegation mechanism
In fact, the second interview mainly asks questions based on what you have done on your resume and the knowledge points involved in your answers.
(1) Introduce a project in terms of project background, implementation reasons, implementation effects and problems encountered. After talking for a long time, I felt like I was running out of words and couldn't explain clearly, so I changed the topic.
(2) When did you start learning front-end, and why do you always stick to the front-end direction.
(3) What other things did you do during your internship at Huawei?
(4) What did you learn from your internship at Huawei? What improvements have you made to your own abilities?
(5) Why learn front-end and an understanding of front-end.
(6) What is the transition from school to company internship?
(7) What new things are you learning now? (No, I am looking at basic knowledge) Then let me give examples of what knowledge and application scenarios.
(8) Why are there three major front-end frameworks? What problem do they solve?
(9) What pressures have you encountered and how did you release them?
(10) What difficulties were encountered and how were they solved? ? (Ask for advice from colleagues) How to communicate and ask for advice?
(11) What shortcomings do you think you have? I'm talking about lack of practical experience (it doesn't seem to be a good thing)
(12) What new content have you learned while laying the foundation? ES6 syntax, web security. . . Then I talked about web security in detail. Asked again: XSS attacks are difficult to detect. How do we detect this problem? .
(13) Future career plans
(14) What background languages have you been exposed to?
(15) Have you met with other companies before?
(16) Are you taking any other offers now?
(17) How do you usually learn front-end knowledge?
(18) Do you have time for internship? No time, I have to write a final essay
(1) What do you think the future development prospects of the front-end are?
(2) Asked about the department, business, and technology stack.
Link: https://www.nowcoder.com/discuss/231656
2019.7.16: The phone interview interrupted the buff throughout the whole process
1.Introduce yourself
2. The difference between Python and C++ (answered many python features)
3. Why is Python slow?
Answer: Because I don’t know the data type, I need to make a judgment when getting the data.
(1. Python is a dynamic interpreted language; values in Python are not stored in the cache but are scattered in objects.
2. Python is an interpreter language. Different from C++ and Java, C++ and Java are both compiled languages. That is to say, after writing a Java program, you must first compile the source program and generate an executable file and a class file. After writing the program in Python , submitted to the interpreter, the interpreter will immediately translate the first line of code into machine code, then hand this line of code to the CPU for execution, and then proceed to the next line, translate the second line of code, and then hand it to the CPU for execution. Therefore, Python executes slower than those compiled languages)
3. What books have you read (answer: python high-performance programming)
4. What is a memory leak? When does a memory leak occur?
Not deleted.
(The dynamically applied memory space is not released normally, but cannot continue to be used. The memory is not released)
5. What is the term for closing a program?
have no idea!
(It may be to close the process, not sure)
6. Pointers and references? When to use pointers and when to use references?
(The pointer does not need to be initialized, but the reference must be initialized and cannot be changed after binding; the difference between passing a pointer to a function and passing a reference to the pointer:
When passing a pointer, the pointer will be copied first. The copied pointer is used inside the function. This pointer points to the same address as the original pointer. If the copied pointer points to another new object inside the function, then it will not Will affect the original pointer;
For passing pointer references, if the passed pointer points to a new object, then the original pointer will also point to the new object, which will cause a memory leak, because the place pointed by the original pointer can no longer be referenced, even if there is no Point the passed pointer to the new object, but release the pointer when the function ends. Then the original pointer can no longer be used outside the function because the original memory has been released)
7. Do you know those data structures?
Answer: Heap array list stack
8. What is a heap?
Answer: Usually, we only use arrays to simulate heaps. We don’t know the real structure. We think it is a data structure in the state of parent node-child node (ultra-high frequency problem, which is generally allocated and released by the programmer. If the programmer does not release it, it may be reclaimed by the OS (operating system) when the program ends. The allocation method is similar to the upward growth of the linked list. The stack is divided and opened while the program is running, and the kernel finds a large enough space along the linked list to give it to the program. , if not found, destruct the useless memory and search again. For more details, please summarize it yourself and review it frequently. The differences include application methods, system responses, etc.)
9. The difference between heap and stack
The stack is a space for storing things. It is stored in the innermost part and comes out from the outermost part (ultra-high frequency problem, allocated when the function is running and released when the function ends. It is automatically allocated and released by the compiler to store local variables allocated for running the function. Function parameters, return data, return address, etc. are opened downwards, and the speed is very fast. If the local performance is good, it will interact with the register and save the PC pointer. If there are many function parameters, it will also form a stack frame and be stored in the stack)
10. Processes and threads
(Ultra-high frequency problem, I read the summary after in-depth understanding of the computer system: 1. A process is a living program. A program is just some text. A running program is a process, which is the basic unit of resource scheduling and allocation in the system. Master it. Resources, including memory, etc. Threads are lightweight processes and are the basic unit of CPU scheduling and dispatch. 2. Because the process occupies resources, stack pushing and popping are slow. Therefore, switching is not flexible, and threads do not occupy resources, but only necessary resources (recursion requires pushing on the stack, so there are some resources), so threads are easy to communicate -> communicate directly in the memory allocated by the process, easy to concurrency -> flexible switching, the same The thread switching speed of the process is very fast, so the thread overhead is small 3. Address space, process independence, threads of the same process share resources, and are independent of threads of other processes)
Summary after the event: Obviously I failed, I was very happy. It made me understand a problem. Those who work on algorithms should also know some back-end things. Engineers in the field of algorithms are required to become competent.
homework help
90 minutes per side
Do two questions first:
1. Find three numbers from the array, and the difference between the sum of the three numbers and the value is the smallest.
Requires time O(n2) space O(1)
My writing method is sorting + double pointers. It's the original question on leecode. I haven't brushed leecode much, but fortunately the solution is the same.
Request sorting using quick sort
2. Strings A, B, and B occupy the shortest subsequence of A (the shortest subsequence of A includes B)
The interviewer and I both laughed, because the Python slice + in operator ended in four lines, and the interviewer also laughed, so we agreed to write the function ourselves for the in step.
Violence solves all the bells and whistles
1. Introduction to Kaggle competition (from EDA to the end)
2. Is the basic tree such as ID3C4.5 a binary tree or a multi-tree? Will the features that have been cut be cut again?
Discrete features (number of discretes > 2) are multi-branch classifications, and continuous is binary splitting. Continuous can be cut, but discrete cannot. To implement, first make a collection, traverse the features, and save The maximum information gain position, and then segment the feature. After segmentation, delete this feature from the set, so the discrete feature is no longer cut after cutting it. Fortunately, I have reacted. The continuous feature can be cut again. For details, go to Take a look at the source code of other people's ID3 trees and other trees)
3. Introduction to BN
(There are many ultra-high frequency questions that can be introduced. The essence of machine learning is to learn distribution, especially logloss loss, which is equivalent to optimizing cross entropy, and cross entropy is used to measure the consistency of distribution. 1. Pre-whitening, fast training, small saturation gradients at both ends of the sigmoid, BN can be scaled to the linear region 2. Distribution learning, the distribution of each layer will shift when the NN is deeper, and the BN compressed distribution makes the distribution of each layer close to the same 3 , BN can be regarded as a certain degree of data expansion, and the data is jittered. Note that during the BN training process, remember that the current batch is normalized and the entire data is used for prediction, and the BN layer has two hyperparameters to be optimized) 4. Which tree is deeper, GBDT or RF?
RF deep. I talked about the ideas of boosting and bagging. Boost uses a low-variance learner to fit the deviation, so XBG and LGB have parameter settings for tree depth. RF is the fitting variance. It cuts samples and features to construct a diverse sample set, and each tree is not even pruned.
5. How is the importance of XGB features judged?
Answer: Not sure, but it’s used a lot. I guess it’s based on the number of split points (the number of occurrences in all trees). That’s all I said.
(gain Gain means the relative contribution of the corresponding feature to the model calculated by taking the contribution of each feature for each tree in the model. A higher value of this measure compared to other features means that it is important for generating Forecasting is more important.
cover The coverage metric refers to the relative number of observations relevant to this feature. For example, if you have 100 observations, 4 features and 3 trees, and let's say feature 1 is used to decide the leaf nodes for 10, 5 and 2 observations in tree 1, tree 2 and tree 3 respectively; then This metric will calculate the coverage of this function as 10 5 2 = 17 observations. This will be calculated for all 4 features and will represent the coverage metric for all features as a percentage of 17.
freq frequency (frequency) is a percentage representing the relative number of times a particular feature occurs in the model tree. In the above example, if feature1 occurs in 2 splits, 1 split and 3 splits in each tree 1, tree 2 and tree 3; then the weight of feature 1 will be 2 1 3 = 6. The frequency of feature 1 is calculated as its percentage weight over the weights of all features. )
6. XGB is easy to understand its regression and binary classification. How to understand multi-classification?
While chatting and laughing, I answered the label encode at the beginning, using onehot+softmax, but how to fit each tree one step before softmax. I really didn’t know this. The interviewer prompted me to talk about three categories, whether to construct 100 trees or 300 trees. I realized it and answered that I thought it was 100 trees.
The interviewer said to construct 300 trees, fit three categories, and then softmax.
(After onehot, the input label is a vector, and a group of trees is integrated for each prediction point in the vector)
55 minutes for both sides
1. Let me first ask if you are majoring in NLP.
No, in the direction of algorithms, we talk about laboratory projects and use the NN algorithm of many images.
2. Three questions
Question 1: The Kth largest number
Three methods were discussed
Method 1: The complexity of heap sort analysis is O(Nlogk) (the analysis is correct)
Method 2: The complexity of quick sort binary analysis is O(N)
Method 3: Sorting lookup table analysis complexity (NLogN)
The requirement is O(N), so I used quick sorting for two points. The interviewer said that quick sorting can solve this problem? But quick sort is the fastest (that I know of) and is exactly the required O(N) complexity.
(After searching on Baidu, quick sorting and hashing are the fastest, while the rest are not fast)
I wrote python code by hand, but I didn’t know what went wrong in compilation. The IDE didn’t prompt me, and the interviewer was also very embarrassed. He said that those who used Niuke before could report the error in compilation, so I said that the following questions should be written in C++ (this The problem is very serious. I couldn’t find any bugs during the interview, so I have to be careful about python and make sure it is bug free, otherwise I will always use C++)
Second question:
Floor n 3, planks 1 3, several arrangements
dp[n]=dp[n-1]+dp[n-3]
Question 3:
Equal probability 1-7
Create equal probability 1-10, analyze the expected number of calls 1-7
7 base, call twice to generate 0-48, then truncate 40 and above 40 and then //4 1
The expectation is not easy to calculate. It is a sum of proportional series, and then I calculated the approximate value 2.5n orally.
Thinking about it, maybe the interviewer was under pressure, so I questioned the quick sorting. I analyzed why it was O(N) instead of O(NlogN) as the interviewer said, and then explained to him why partial sorting can solve this problem. There should be no problem with the interviewer's level (PS: Don't think that the interviewer's ability is not good, most of the interviewers are good at it) Thank you, Homework Helper
Very efficient, I had an interview one day after submitting my resume.
The first interview went very smoothly, and the second interview lasted a hundred minutes. I learned a lot from the communication with the interviewer.
One side: It was so smooth that I didn’t record anything in my notebook. The other side was so smooth that my answers were fluent, so I didn’t record anything in my Q&A record. The first question LIS: I didn’t even act. After asking all the requirements of this question, I just wrote down the optimal situation silently, and then explained to the interviewer why this result is correct, and then I wrote down the O(n^2) way of writing. I forgot the second question, so I ended the two sides in one minute: They are all open questions, there is no standard answer, the duration is 100 minutes, and the content is mainly about actual recommendation scenarios and competitions? From beginning to end, I talked about my work at each stage, and my work at each stage. thinking, my mental journey at various stages. (That’s right, what the interviewer wants to hear is probably my work at various stages, the problems I encountered, my thinking and solutions to the problems) How do you think you measure user satisfaction with search results? South. I'm too southern. But I talked about TCP connection timing, filtering timing noise according to the scene, such as video scenes using the percentile timing of the video length, the effectiveness of seconds back, etc. The interviewer can be satisfied with this. Then I racked my brains and couldn't think of another good feature, so I just used weak features, such as the correlation of quary and so on. The interviewer is dissatisfied because these things mainly indicate the user's interest rather than satisfaction. How do you think we can solve the problem of pushing new search results? Answer: The new search results must have a push history of 0 and there is no reference, but we don’t know what their quality is. So he randomly pushed it to a small number of users for promotion. When promoting, pay attention to the phenomenon of increasing click-through rates, filter it, blah blah blah. The interviewer was very satisfied. What do you think of the scenes and models? I personally pay great attention to the scene, starting from my own scientific research experience, talking about the introduction of the Watermelon book, and telling my complete mental journey. The interviewer can be satisfied. I forgot some of the questions, there were so many that I lost my voice after talking about them, but the interviewer’s guidance was really informative. He didn’t ask about some things about the model, but asked about actual projects. I was questioned and doubted about life. After the interview, it was over. , the interviewer said that he would report it to his supervisor and just wait for the news. When the interviewer criticized me like this, I wanted to go to Baidu because he conquered me.
There is no internal recommendation, and the resume written directly on the official website seems to be interviewed in 1 or 2 days, but. . It was originally my favorite company, but now it is no longer. Tencent school recruitment
Intended department TEG call directly: Research post
Introduce yourself and talk about the project
Are you interested in our section: Department Log Detection Security Field
understand each other
We have a meeting, let’s continue chatting next time
10 o'clock: Continue talking about what we talked about last time
The whole process was relatively relaxed and enjoyable
The second meeting is over, but the status is still that the second meeting is to be arranged. . .
Discuss with the interviewer how to use machine learning methods to handle dangerous log detection. Reviewing the major knowledge learned from the beginning is also considered self-reflection. The more prominent experience that can be gained here is that many departments still focus on rule learning and have strong interpretability requirements for machine learning classification situations. Therefore, models with good interpretability such as tree models and LR are very popular. But in the end the interviewer "thanked" me, probably implying that I failed, Sang Xin
I was told that I got A's on 3 and a half of the five questions in the written exam, and my score was okay, but the department locked my resume. . .
I notified both sides, and after a few minutes, they chatted casually and said they would continue to meet in September.
The current process is over and I feel comfortable. Logically speaking, it should have been over a long time ago. There are no machine learning positions in this department, but I want to find an algorithm engineer to open up the business. I asked me how many people I need to recruit emm~
Pinduoduoduo thank you letter
one side:
introduce yourself
Introduction to scientific research projects
Kaggle competition introduction
Tencent competition introduction
Have you ever used RNN? Used it: Project Kaggle
Have you used LR? Used: Kaggle’s two-classification detection
The difference between XGB and LGB:
I only think of three points, feature sorting, feature segmentation, histograms and full sorting.
He said that they have more in common and made a small mention. He also mentioned GBDT, XGB and LGB, and then talked about the actual experience of using these two models, and then said that he only remembered three differences. The actual effect of XGB is not inferior to LGB, but the adjustment Ginseng is not easy to handle, and LGB is very fast
(
1) Faster training speed and higher efficiency: LightGBM uses a histogram-based algorithm.
2) Histogram difference acceleration: The histogram of a child node can be obtained by subtracting the histogram of the sibling node from the histogram of the parent node, thereby accelerating the calculation.
3) Lower memory usage: Using discrete bins to save and replace continuous values results in less memory usage.
4) Higher accuracy (compared to any other improvement algorithm): It uses the leaf-wise splitting method (selecting the node with the largest split profit among all current leaf nodes for splitting, and so on recursively. It is obvious that leaf-wise This method is easy to overfit, because it is easy to fall into a relatively high depth, so it is necessary to measure the maximum depth. (to avoid overfitting), which produces indiscriminate splitting on all nodes in each layer. The gain of some nodes may be very small and has little impact on the results, but xgboost also performs splitting. , bringing the necessary overhead) more complex trees, which is the main factor in achieving higher accuracy. However, it sometimes may lead to overfitting, but we can prevent overfitting by setting the |max-depth| parameter.
5) Big data processing capabilities: Compared with XGBoost, due to its reduction in training time, it can also have the ability to process big data.
6) Support parallel learning.
7) Local sampling: retain samples with large gradients (large errors), and sample samples with small gradients, thereby reducing the number of samples and increasing the computing speed.
)
For code-related questions, just ask the interviewer to choose C++ or Python. The interviewer (it seems that all interviewers responded the same way) "Just choose."
My choice is python. It writes quickly.
There are chess pieces on the chessboard. You can only go from top left to bottom right, right or down. How many chess pieces can you pass at most?
dp[i][j]=max(dp[i-1][j],dp[i][j-1])
if chess[i][j]=='chess piece':
dp[i][j] =1
Ermian: I guess it’s cool, not a good answer.
Another interviewer with a built-in interruption buff is messing with my train of thought. Isn’t it okay if I don’t go?
1. gbdt and xgb
(gbdt, xgb, and lgb must be mastered in all projects mentioned)
2. BN, Dropout
(Dropout can be used as an alternative trick for training deep neural networks. In each training batch, by ignoring half of the feature detectors (let half of the hidden layer nodes have values 0, of course this "half" is a hyperparameter, Setting it yourself) can significantly reduce the overfitting phenomenon. This method can reduce the interaction between feature detectors (hidden layer nodes). Detector interaction means that some detectors rely on other detectors to function.
Dropout simply means: during forward propagation, we let the activation value of a certain neuron stop working with a certain probability p. This can make the model more generalizable because it will not rely too much on certain local characteristics.
In fact, it is a Bagging strategy to construct a subnet combination. )
3. Why don’t you use LR first (why use LR so easily?) Using LR for two classifications and stacking is quite good, but LR always feels that its expressiveness is not enough, and the effect may be average if the features are thicker. 4. How to discrete the characteristics of the Tencent competition, the continuity characteristics can also be crossed. Why not cross -discretely is a data split barrel. I will explain it with the interviewer for a long time. The percentage is the percentage of data sorting, not the percentage of the interval. After the continuity features cross, after the continuity feature is mapped into discrete features, it can be sent to the embedded layer with the continuity features. 5. AUC knows, how to calculate AUC
I don’t know how to calculate, there is no check at all .. Is it wrong? I actually want to say how to calculate the AUC that logic returns
(Return without AUC, say this)
6. Which of the stacks and stacks is fast
MMP was completely reversed, and it took a long time to respond. It is said that it is allocated when compiling, so you don't need to open up the expansion and shrink, the stack should be stretched, so it is slow (see the previous answer, this answer is wrong)
7. Reproduce and rewrite
(Note that the rewriting is the rewriting of the virtual function. I answered wrong at the time. The so -called heavy load is the function parameter table of the same name. When compiling, the function will be changed. In fact, they are no longer the same name. The virtual function rewritten, the sub -classy non -deficiency function of the parent class is called repeating or hiding, it is not rewriting anyway, the rewriting is the rewriting of the virtual function)
8. How to do the most 100 things to buy big data to buy things
Build a beh table small top pile
9. How to do the bottom layer of the map
I said I haven't read the bottom code yet. (In other words, I never know that there are things like MAP, they are all hand -to -hand beh watches.
(Red and black trees under the bottom, a search insertion and deleting data structure of O (log (n))
The index complexity I said, log (n) suddenly realized that the index is a binary tree
10. Is there O (1)? I realized that I wiped me there was a beach table.
What should I do if I conflict?
Answer the zipper Chong Hash Current 1
(The same high frequency problem, zipper: linked list, one conflict is one behind the linked list; detection: linear detection, second detection, for the current value 1; then hash: multiple hash functions)
Actually I don't know STL, I like hand. I don't like to use STL library functions, which makes me STL not very good. Wait for a wave of STL source code analysis.
mogujie
The interview experience is particularly good, one or two sides are smooth, and then HR is particularly good. I feel that the HR surface has passed. The interface, there is an interview time, editing box, determined button, and abandoning button. The prompt is written: if you click OK, the time will not be changed. I didn't dare to give up again, called HR, and said that the time to write the time was giving up. During the second interview, the prompt of this box became. If you click OK, the time will not be changed. If the time is not suitable, please write the right time and cancel it. I felt that the HR thief was good, so I expressed my satisfaction, support and appreciation of HR work on both sides, and said that my praise would be fed back to HR drops. So I feel that the HR face has passed, so I have a bad face.
But I am talking about the truth, and I really like their HR.
Self -introduction, two questions
The first way:
The maximum element within 1000
Speaking of Python can O (1) Space implementation vegetarian generator and screening method, but the screening method, but if it is not written, it is not written if there is no request.
Analyze the complexity, how to reduce the complexity? From top to bottom, search from 999, searches, stop, each time -2. BOOL judges that from 2 to root X, the model is full, and the non -0 jumps out of FALSE. But it seems that the interviewer will not Python? So switch to C ++ next question
The second channel:
It is simple to implement the method without removing the method
Note that in my writing, ABS (a negative number) in C ++ may overflow, but it does not matter that the speed A is more important during the interview. You should pay attention to these details, and Python will not overflow
Just prepare for binary optimization when the written test is the next topic. I wrote it during the interview.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
#include <iostream>
using namespace std;
int jianfa(int num1,int num2)
{
int re = 0;
bool fuhao = false;
if ((num1<0 && num2<0) || (num1>0 && num2>0))
{
fuhao = true;
}
num1 = abs(num1);//小心溢出
num2 = abs(num2);//小心溢出
if(num2==0)
{
cout<<"div zero error"<<endl;
return 0x3f3f3f3f;
}
if(num1<num2)
return 0;
int tmp=1;
while(num1>num2)
{
tmp*=2;
num2*=2;
}
num2/=2;
tmp/=2;
while(num2)
{
if(num1>=num2)
{
num1-=num2;
re =tmp;
}
num2/=2;
tmp/=2;
}
if(fuhao)
return re;
else
return -re;
}
int main() {
int num1,num2;
cin>>num1>>num2;
cout<<jianfa(num1,num2);
return 0;
}
I asked a lot:
I can't remember amnesia. .
1. Why do you have no internship experience?
The first point does not let the teacher find a job. (This is the truth. Today, the teacher said to another classmate, did you find a job? You find a job but you can't finish your job.
Secondly, in order to be able to get in touch with actual projects, in addition to scientific research, he participated in the competition and Barabala. The interviewer can be satisfied.
2. Have LR used?
necessary
3. What is LGB better than XGB?
Different from the two
4. L1, L2 different? Why can L1 be sparse?
From the mathematical distribution, one is the distribution of Rapras is a Gaussian distribution; the illustration is sparse, one circle and one diamond -shaped, and it is easy to intersect on the axis. In terms of project, the approximation of L1 is optimized by 0 interval. Then L2 is relatively simple to ask for direct directors.
5. Which learning device is pretty?
LR SIGMOID LOGLOSS. Linear regression, minimum daily multiplication bump. SVM bumpy. NN is definitely not good, because it often converges to the saddle point. There are countless academic solutions in PCA, but the use of feature values will obtain the optimal solution
(Note that SIGMOID's square loss is not a convex optimization)
6. What are the importance of characteristics, such as feature combination and deletion, how do you adjust your ginseng?
Answer: The characteristic combination is intemcted with onehoting. If you combine it, it depends on the actual distribution. It talks about a combination of a combination of linear relationship between the label, saying that you use the method of traversal, construct new features with two mathematical relationships, and see the linear relationship with tags.
The feature deletion has thought of the feature screening step of a kaggle big man, and I also learned a lot from his Kernel.
Tune:
The first step ancestor parameter. For example, the depth, sampling frequency, etc. of the tree model, this is mainly experience
The second part of the tuning, such as trying new features, the characteristics of the feature sampling should be set to 1, this detail
7. Know how many activation functions?
I said that the simplest Sigmoid Tanh Relu, I won't mention it. When I talked about a certain game, I used Leakrelu, and then the Swish function in Google's paper introduced this paper casually.
8. What is the saddle?
I said what I said, and then I said it, but it is definitely not a local optimal point. It is really forgotten to see the emoji interviewer. In fact, I really forgot.
(It is better to understand the image of the saddle point. Pay attention to one direction rising, so it is easy to slide from the slide to the saddle point. The other direction is decreased, so you can sit down with the decline. It, so optimization is easy to trap here. A few more steps in front are slippery ladders but he has no way to go. Point) In the differential division equation, it is stable along a certain direction, and the other direction is an unstable strange point, called saddling point.
The critical point is called the saddle point. In the matrix, a number is the maximum value in the line, and the minimum value in the column is called the saddle point. It should be widely physically. It means that in one direction is a maximum value, and the other direction is a point with a minimal value.
In a broad sense, a smooth function (curve, curve, curve, curve, or ultra -curved surface) of the saddle point neighboring domain, curves, curves, or super curved surfaces are located on the different edges of this cut line. )
First ask the use of RNN, I haven't used RNN
Answer: The RNN effect of the project, the analysis of RNN is not good in the project, and the early effect of the RNN in the game (the best early effect)
Have you ever used GRU, why can LSTM remember when he is long.
Answer: GRU has been used once, where is it used. The memory door used to ensure long -term memory transmission.
9. What are the Attention?
Answer: I have said that I have used attention before, and I have only used it. I do n’t know the principle.
(As a golfer, try all kinds of networks, but I still don't understand the essence of Attention, Attention is all you need?)
10. Why does Dropout prevent fitting?
From the perspective of Bagging, NN is a learning device with a differential small square meter. It is suitable for using Bagging to construct a combination of the constructor network at prediction, which is equivalent to constructing the diversity of learning and realizing Bagging.
11. Coordinated filtering:
Speaking of understanding but not writing code
(Coordinated filtering, it is difficult to get in touch if a student is mainly engaged in scientific research. If you are interested, you can understand it, especially the product recommendation engineer of the product e -commerce company.
12. CTR estimation, what do you use?
I said LR and FM, the code has been written, FM is mainly NFM, the other FM knows theory but did not write the code
13. Why are you making Mushroom Street?
Answer: Selling clothes drip. So he introduced Mushroom Street is mainly e -commerce and live broadcast. (I almost laughed when I heard the live broadcast. I couldn't hold it anymore, and I was inexplicably very happy. Then he couldn't help it.
Successfully, there is no code, because the time is not enough for half an hour, and the comment on one side is that the code ability is particularly good, so I don’t write the code.
There is a complete software in my project. The main part of my responsibility exceeds 10,000 lines of code. It may be that this makes the interviewer feel that I don't need to thank the code.
In fact, most of the normal hands 撸 code can (except that the string is my weakness).
I introduced the project to the project details
The characteristics and combinations in the project in the project are different or or in the field of coding, so using RELU BN to mention features, BN is really a huge improvement
Talk about BN principles, formulas, implementation
(You can see the BN source code, not long)
Why use BN compression or post -mapping positive parts instead of nothing (not heard clearly)?
I mentioned that the BN layer has also been counted as data expansion, and the BN layer transforms the coding of only 0,1 to make the gradient change, and the optimization is better. Just optimize)
Why use CNN? Then face the interviewer to introduce another thing in the recommendation field (Embedding). This embedding reflects the hidden vector. Do you think is CNN crossing?
Answer: (Actually, I know Embedding, because the friends who participated in the competition handed NFM, the first layer was this embedded layer.) My answer is biased towards the scene, one characteristic in the encoding field: only partial correlation, the time is unchanged. So using CNN to do global related Embedding is not good. The recommendation in the recommendation is sparse after discrete, and the features may have high -level interaction information itself, so the effect of mapping into a hidden vector will be better. If it is recommended, I recommend using hidden vector instead of CNN. In fact, this is determined by the scene. It is the characteristics of the data that determines what learning device and what network to use. (I also introduced why the image is better, but in the encoding of my two layers of limited tuning network performance exceeds the residual network, in fact, it is determined by the scene)
The interviewer is a big man!
Introduce myself, will you come to Mushroom Street? Mushroom Street is good. I lick it, but what I say is my heart. The answer to the answer is mainly because I introduced my own game, from the beginning to the end, the background of the game, the journey of the middle of the middle, and the final process. It was so smooth on one or two sides, and the front of the cross surface was smooth. It lost in a water question that would do, so angry. Otherwise, my mushroom street is stable, it was not like words, hey
Given parentheses flow, find a continuous number of continuous matching in the string 1 s = '(()) (()) (()) (() () ()' The output is 3, my DP seems to be the most one more 0? I may not be able to do it and then I feel that it should be made by stacks and greedy. Dynamic planning can be done, this is my strength. None of the empty. = '()' I thought it was input, and the actual s read should be empty. Two 0. 12 13 14 15 16 17 18 19 20 22 23 24 26 27 28 29 30 31
#s = input()
s = '(())(()()()'
#s = '(())(()'
re = []
dp = [0]
for i in s:
if not re:
re.append(i)
dp.append(0)
else:
if i=='(':
re.append(i)
dp.append(0)
else:
if re[-1]=='(':
re.pop()
dp.append(dp.pop()+1)
else:
re.append(')')
dp.append(0)
print(re)
print(dp)
m = 0
cur = 0
for i in dp:
if i!=0:
cur+=i
m = max(cur,m)
else:
cur = 0
print(m)
输出:
['(']
[0, 0, 2, 0, 1, 1, 1]
3
When I asked the question in the end, the interviewer was very good. Regarding the recall ranking, he added some of the practices in the industry. In general, as long as we sort, as long as the order is partial, but in the situation of some bidding advertisements, we must give an accurate estimation value so that we can divide the money. For example, the clicks CTR is still other combination, and finally calculate the income based on this sorting. In addition, in the recommendation search, the big brothers also introduced some related things. That is, the recalled things may be too high, or they need to be filtered out (such as that children are not suitable, everyone is crazy, not too good), so how to make filtration. And if it is recommended for someone, one is to send it in the crowd without any features, because push for someone, this person is equivalent to all advertisements or other recommendations, so it is sufficient to interact with this person. In the end, I asked the company's average age, because I personally care about this. One of the annoying Internet companies is that the crowd is particularly liquid. I want to squat in the pit after occupying the pit. The interviewer said to me not to have a burden in my heart. After two years, you have made your own contribution. He can go to other companies. He has been to two companies himself, one is more than 4 years, and the other is more than 5 years. (The interviewer looked at such a young and shocked), and then his little girls were 10 years younger than him, and he was embarrassed to ask the actual age (it turned out to be a leader ... strong, handsome, handsome, strong strength)) He was more supported by me after two years. Moreover, he said that Mushroom Street is a large platform and has unique benefits. It pays more attention to the cultivation of people than BAT, and the big data stream of the platform may not be as large as BAT. This large data flow can be used in many models. Unlike Baidu (I didn't mention Baidu all the way ...) Some open source packages of data flow companies may not work. You can only use the wheels made by your own company to come to Mushroom Street. You can show yourself better. I received a notice from the HR surface and asked the interviewer to come to school or go directly to the company for interviews. Choose the latter to prepare to experience the customs and customs of Mushroom Street.
1. Self -introduction
There is nothing to get a hand. I am mainly algorithm engineer, and the actual scientific research project is either professional (the programming algorithms are not stained), or the algorithm
Speaking of the scientific research software I wrote, the code volume is more than 1w or more, I wrote a bunch of reports of other simple mention
When I introduce myself, I mentioned that I like to play games (I used to play piracy, now playing genuine, Steam 50 or higher, and the game is almost 100)
(The back -end development is a bit self -taught, and it is not python for Mutual Entertainment)
2. What games do you usually like to play?
Recently, scientific research has not played games. I used to like to play Zelda, Black Soul, Monster Hunter, etc.
3. Have NetEase's game played?
Yin Yang Shi and Hearthstone
4. Talk about Hearthstone?
I used to like to play Hearthstone, mainly because I like to open the bag (the interviewer laughs), and I spend a lot of money for Hearthstone, because I like a game and I am willing to support him. The advantage of Hearthstone is that it is competitive and is also a game of playing cards, so it is interesting, and it is random in each game, so the experience of each sentence is different. Another point is that the gold coins are opened. The gold coins are updated after opening the bag, which can have a new construction and new experience. In this way, I will experience a new experience every time to retain users. I also like to open the bags that are nervous and exciting.
5. Three questions, relatively simple, write test cases
Hand tearing is successful, writing code is still relatively fast
Two points in the first question
Python's compilation and error, Niuke.com can't find any fault, I quickly re -write a rewrite one
Discuss the four boundary conditions of two points
Return St, EN two corresponding two corresponding backward search boundaries, data [mid] <value and <= value, two corresponding two -point upper and lower bounds
There are four types in total, and then the four cases correspond to the corresponding range. Each value range is returned to ST, and the return range is 0 to the length of the array. When the return of EN, the meaning of -1 to the array length-1 ST and EN are different. This is best to write and understand it by yourself (updated the understanding of the LOWER_BOUND, explain why the return value range is 0 to Len (DATA) PS: The standard library returns the iterator position, it is a pointer, I am here from the position of the element. Overview. The first position of the return array is greater than the value of value. If all elements in the array are smaller than the value, and return to the tail iterator Len (DATA). The element is greater than equal to Value, then returns 0) From the definition, it is impossible to return to negative 1. Upper_bound returns the first position greater than Value. Backing ST situation -1 LOWER_BOUND: Returns the first position greater than the value of value.
Upper_bound: Return to the first position greater than value, upper_bound_en: Back to the first position of less than equal value 1 2 3 4 5 6 8 9 10 12 13 14 15 16 18 22 23 26 27 28 29 29 29 29 29 29 29 29 30 31 32 33 34 35 36 37 38 39 40 41 43 44 Def Lower_bound (data, value): ST = 0 EN = Len (DATA) -1 MID = ST+((EN-S) >> 1) WHILE (ST <= EN): If Data [MID] <Value: ST = MID 1 ELSE: EN = MID -1 MID = ST+((EN -S) >> 1) Return ST Def LOWER_BOUND_EN (data, value): ST = 0 EN = Len (Data) -1 MID = ST+((EN-S) >> 1) While (ST <= EN): If Data [MID] <Value: ST = MID 1 ELSE: EN = MID-1 MID = ST+((EN-S) >> 1) Return EN DEF UPPER_BOUND (Data, Value): ST = 0 EN = Len (DATA) -1 MID = ST+(EN-ST ) >> 1) While (ST <= EN): If Data [MID] <= Value: ST = MID 1 ELSE: EN = MID -1 MID = ST+((EN -S) >> 1) Return ST DEFPER_BOUND_EN (Data, Value) : ST = 0 EN = Len (Data) -1 MID = ST+((EN-S) >> 1) While (ST <= EN): If Data [MID] <= Value: ST = MID 1 ELSE: EN = MID -1 MID = ST+(EN-S) >> 1) Return EN
The number of contrast was changed to 1.
) Then I said which two forms of the C ++ algorithm standard library (LOWER_BOUND and Upper_bound): the two types of attention C ++ standard library returned to the ST is the depth of the binary tree.
Python torn, reported an error, and then did not check the bugs. It was okay to find it. Print was very good. For python, if print ("xxx") did not output, it means that the line did not run.
When defining the tree class, it is written .next, dizzy, should be .let and .Right
The third question is the array rotation
Left rotation, confident waves of analytical writing are right rotation, a look of aggressive face, how to look at the left rotation run, the right rotation
Then try the trial modification i, j, and then output it for the second time, dizzy, better luck
Due to the constant limit of cycle, it is required to be changed to the scope of the array. Note that Python Len (data) is Len (data [0]) as a column
Normally constructing a large NEW array like Data is first listed and then line [[0 for _ in range (len (data [0])] for _ in range (len (data)]
Then the loop is first and then (so that the locality is better, fast running speed, and it is easier to cache the hit. Of course, the interviewer did not ask me or mentioned it)
The writing should be right, but I dare not change to the situation where the ranks are not equal. In case of wrong .PS: It should be wrong to think about it, because I opened the new array as Data, and it should be opened in turn. If the follow -up structure is first, it just corresponds to the situation after the rotation. Fortunately, it is not considered, but this bug is easy to change. Print () Dafa print will come out
Ask the question: I hope he asked me to ask me for the stuff of machine learning so that I can pretend, but
6. Static memory and dynamic memory?
It is said that static and stacks are static. When compiling, the size is determined. Dynamic memory can be opened freely-> I don't know if it is right. .
(Come back and ask another harvesting big brother, it should be this)
7. What is the heap?
Speaking of the upward development, the speed is slow, the operation is changed, and then the development process is opened. The linked list has the next position and whether it is used in this piece. Earlier answers)
8. What is the stack?
It is said that it is opened down, fast, allocated during compilation, mainly PC pointer, and then the function entry parameters make more stack frames and wait for recovery
9. Malloc and New distinguishing free and delete?
1. One is the function (the interviewer did not ask, but I consciously, the honest answers have forgotten which file is it. Afterwards, I checked the stdlib. I wiped me every day.
2. Malloc should be counted as the size, return VOID*(then then mentioned void*to XX*), use the type after the rotation after the rotation, and the size of the size; , And then open 100 directly, he automatically calculates the int length in
3. Malloc is piled again, and New is in the free storage area (then answered to forget where the free storage area is), telling about forgetting free and delete
(Free storage area and heap seem to be conceptual differences? I lost, and I understand the computer foundation in depth. I know what is the difference between the free storage area of C ++ and C. Malloc is implemented, so shouldn't they open in the same area? C ++ defaults to open the space required for new NEW on the heap, so New comes from free storage areas and piles.
The answer to the online search:
The free storage area is the abstract concept of dynamic allocation and release objects through the New and Delete in C ++. Heap is the term of the C language and operating system, and it is a dynamic allocation memory maintained by the operating system.
The memory area applied for by New is called a free storage area in C ++. With the free storage achieved by the heap, it can be said that the memory area applied for by New is on the heap.
There is still a difference between the heap and the free storage area, and they are not equivalent.
)
10. Do you know the smart pointer?
From the perspective of Python's memory management perspective, I talked about the counting method of the counting method, which is consistent with the principle of the intelligent pointer. But I consciously said honestly that I haven't used the smart pointer before
11. How does python solve the cycle reference?
Do you want to ask me the cycle reference solution of my smart pointer? I forgot, I just said that Python itself cannot solve the problem of cycle reference (this truth is true, it really cannot be solved, python is not a god, the cycle reference must be dependent on its own structure. For python, the process of cycle reference even the program is a program. It is still there), but Python has a library function to find the circulating reference position, and then call the garbage collector to analyze it (in fact, the positioning of the memory leak, and then the GC kills it)
12. Do you know how to understand? The difference between computer network TCP and UDP?
Answer self -learning. I answered a lot, it's very detailed
(UDP is mainly used for communications or broadcast communications that have higher requirements for high -speed transmission and real -time.
TCP is used to achieve reliability transmission in the transmission layer
1. TCP facing connection (such as calling to establish a connection first); UDP is no connection, that is, no connection is required before sending data
2. TCP provides reliable services. In other words, the data transmitted through the TCP connection is free of errors, no loss, no repeated, and reached in order; UDP does the maximum effort to deliver
3. TCP faces byte flow, in fact, TCP regards data as a series of unstructured byte flow; UDP is a message -oriented; UDP does not have a congestion control, so the Internet congestion will not reduce the delivery rate of the source host ( It is very useful for real -time applications, such as IP phone, real -time video conference, etc.)
4. Each TCP connection can only be points; UDP supports one -to -one, one -to -many, more to one and more interactive communication
5. TCP's first cost of 20 bytes; UDP's first cost is small, only 8 bytes
It is recommended that the first setting of the first setting is not the same, let alone the details.
6. The logical communication channel of TCP is a reliable channel for a full -duplex, and UDP is an unreliable channel
)
13. Long transmission and short transmission?
have no idea
(Is it the long connection and short connection of HTTP? HTTP1.1 stipulates the default maintenance (HTTP) default (HTTP), and the data transmission is continuously kept on the TCP connection (no RST bag, no four handshake), waiting in the same domain name Continue to transmit data with this channel; on the contrary, short connections.)
14. What about the operating system?
Answer my own in -depth understanding of the computer system.
15. Process and thread?
The program is only a text, and it is the process to run. A meal talk, the resource/dispatch unit, the shared memory, and the concurrency xxxxxx
(See the previous answer)
16. What else do you ask me?
Ask two questions
Ask: Can you understand the information of other interviewers, and then boast the bytes behind the seats behind my teaching and research room (because he particularly wants to go to interaction to play games). At the beginning, the interviewer thought that this person had hung up I want to make a hand, and when I hear me at the same time, I can easily say that since I can pass the interview, then I suddenly think that it seems that I can imply a wave. I really want to be a colleague with him (strong hint)
Second question: I said that I am an algorithm engineer, and the machine learning is particularly powerful. What is the content of the work? Do I use the part of machine learning?
Ask Mutual Entertainment to give a lottery opportunity, the coach I want to play games ~ (If Baidu forgot me), you dare to let me pass by, but you can be caught by me
The department responsible for the 360 search has a good interview experience.
I forgot part of the interview, because 4 consecutive sides, including 360 technical places, 1 NetEase Internet, 1 HR face, very tired.
1. Introduce yourself
2. Introduce the scientific research software that you realize
What language: C ++
What writing interface: Qt
3. The difference between LGB and XGB
At first I heard that it was LSTM. I was still thinking about the difference between LSTM and XGB. How to say, let's introduce XGB first, and then talk about XGB reacted. The interviewer does not let me say LGB. . That's how to say, say a meal.
(Answer before)
4. Introduce how CNN and convolutional layer can achieve non -linearity
Using the activation layer, otherwise it is a linear transformation. I started a meal from the cat's visual cone cell. It should be very detailed. The non -degeneration of CNN is really suitable for signal processing. It is said that it is unchanged and the local rights are shared, saying that CNN is a special case of DNN.
(
Convoiced: For the image (a set of fixed weights) for the image (different data windows data) and the filter matrix (a set of fixed weights).
The important physical significance of convolution is: one function (such as: unit response) The weighted superposition on the other function (such as: input signal).
The convolutional neural network CNN is a variant of a multi -layer perceived machine (MLP). In the 1960s, Hubel and et al. When studying the cat's dermis layer, he found that its unique network structure could effectively reduce the complexity of feedback neural networks, and then proposed CNN.
CNN: The method of local connection and sharing value reduces the amount of weight value that makes the network easily optimize, and on the other hand, it reduces the risk of overfitting. The input of this advantage is more obvious when multi -dimensional images, so that the image can be directly used as the input of the network, avoiding the complex feature extraction and data reconstruction process in the traditional identification algorithm. There are many advantages in two -dimensional image processing.
CNN has the advantages of some traditional technologies: good fault tolerance, parallel processing ability, and self -learning ability, which can handle the complicated environmental information, the background knowledge is unclear, the reasoning rules are unclear , Distortion, fast running speed, good adaptive performance, high resolution. It is a multi -layer perceived function through structural reorganization and reduction of weight to blend features, and omit the complex image feature extraction process before identifying.
CNN's generalization ability is significantly better than other methods. Convolutional neural networks have been applied to pattern classification, object detection and object recognition. Use convolutional neural networks to establish mode classifiers, and use convolutional neural networks as universal mode classifiers, directly used for grayscale images.
)
5. How to put the convolution layer Pooling layer? Where is the best way to put the activation layer and what is the difference?
I didn't understand, shouldn't it be a activation layer in the middle? Is the interviewer's pooling really difficult to say? I always thought it was the final full -connected FC layer. I thought this was not replaced by global pooling? Can't talk nonsense? Because when I am also changing the Internet, I often try to exchange layers. Which of me is easy to use? When I said, I thought of the pre -excitement in He Kaiming's thesis, and then exaggerated the role of pre -excitement and convolutional layer on ResNet. Are there any big guys? Please talk about me privately. . .
Two questions
1, 10 in -action transition K in advance -based transformation
Given a decimal number m, and the number of inlet namids that needs to be converted. Input the decimal number m into N input number input description into one line, M (32 -bit integer), n (2 ≤ n ≤ 16), separate in space. The output description is the number of each test instance output, and each output takes one line. If n is greater than 9, the corresponding digital rules refer to the hexadecimal (such as, 10 use A, etc.). This is very simple. Send your own way of writing. There may be problems with individual borders, but try to pursue speed during the interview. During the interview of Niuke, pay attention to running all the cases, you can see the situation of AC. Why do you say that? Because your input interviewers are invisible (what he said), he can only give you a look at how many examples have . Such water questions must be written fast.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
//map<int,char>table;
//table[0]='0';
//table[10]='A';
#include<stdio.h>
#include<iostream>
#include<string>
#include<vector>
using namespace std;
void reverse(vector<int>&a)
{
int l = a.size();
for(int i=0;i<l/2; i)
{
int tmp = a[i];
a[i] = a[l-i-1];
a[l-i-1] = tmp;
}
}
string get(int M,int K)
{
bool ju = false;
if(M<0)
{
ju = true;
}
//注意负数转正数溢出
M=abs(M);
vector<int>data;
while(M)
{
data.push_back(M%K);
M/=K;
}
reverse(data);
string res = "";
if(ju)
res ='-';
for(int i=0;i<data.size();i )
{
if(data[i]<=9)
res ='0' data[i];
else
res ='A'-10 data[i];
}
return res;
}
int main()
{
int M=7,K=2;
cin>>M>>K;
string s = get(M,K);
cout<<s<<endl;
}
2. A-> B, B-> C, A-> C, C-> A has a pair of chain A-> C, C-> A asking how many pairs of chains are used in the sequence?
Requirements: The sequence is very long, just look at it directly, A-> B-> C-> A is not considered ABC interconnection.
Talking about the simple D [i] [j] = (bool) structure, the time and space complexity of O (n^2)
Talking about the time complexity of the time of O (n^2), O (1) space complexity
Finally, I said several arrays + linked lists. In extreme cases, the time complexity is also high, but what I think is that the sorting of the linked list is not slow. Two -point search, time and space are ok, but I am stupid and think of it in my heart. There is no linked list sorting on the mouth.
In the end there are the big guys who teach me. .
Good experience, one question, the first two questions that have been pumped, one is a puppet sorting, and the other is the preface to reconstruct the tree in the preface.
They all refer to the original OFFER title. The interviewer saw me smoothly and asked me if I had done it.
I said that I had done a sword to the original OFFER. The first two questions were not handwritten.
The first puppet sort requires stable sorting, thinking 1 is merger and sorting, and it is greater than before. Thoughts 2 Double Poor Two -point Two Display
The second way to find a root node, two points, no more
I haven't done it in the third way, but it is also simple. Ask the interviewer if I can use Python. If I can, I will end this question in two minutes.
This side is mainly to dig deep projects and dig deep!
In the case of the interview, the interviewer guided me crazy. It was good. Here I summarized a part of the remembrance:
I talked about some questions recommended by search. The first I asked was the requirements of 360 on programming capabilities. The interviewer's answer is that all algorithm engineers must have a strong programming ability.
The second is the problem in the recommendation list. I said that I got on the rankings. The reading volume is crazy increase. As soon as the increase, it will stay on the ranking. What should I do? The interviewer answered that this is a positive feedback question. I said a lot of dry goods. If you are interested in making recommendations, you can see the relevant content.
I asked the question of the cold start, and I said that for the first time, how can I recommend him for the first time when the new page appeared. Without any exposure? Here I asked me, and I answered my thoughts. First, I tried it in a small batch and then promoted.
The interviewer began to talk about the difference between recommendation and search sorting, and search sorting problems was more complicated. The so -called sorting is the web interface that obtains big data, and then the user's query gives the most likely result (LGB available). Sorting the things), the sorting here must be correlated, the query must ensure the diversity and diversity of the output results, and also involve the tightness, operation and similarity of words between words and words.
In addition, there are many difficulties in sorting. First of all, the amount of data is greater and the information is more information, but the more the indexes are, the better, because there are duplicate (plagiarism web pages) and a low -quality web page. In addition, for Learning To RANK, we don't need to get an accurate regression value like returning, as long as he gets his partial order. For example, A <b, we calculate the value A: 80, B: 79 and A: 80 B: 77, the partial order is the same, as long as the sort is correct. And to test our sorting well, it is based on the feedback to test the advantages and disadvantages of the model. For example, we put A in front of B, but users do not click A, and users can change the Quary word or pages. . These problems may be solved with a probability diagram these three times. Sorting technology is difficult, and the technology required at the bottom is also relatively high. In addition, the user's inquiry and our results may have a certain GAP. For example, the user searches the price of a car, and the search result we give is the transaction price of a car, which has Gap.
最后我问了这么一个问题,就是我在做学习强国的时候,查询一个答案, 结果第一个是付费的,第二是是免费的,有限的时间里查到的第一个结果让我付费观看,我就很生气。这个怎么看待?面试官的回答也是很棒呀,所谓的搜索排序最终就是给用户满意的结果,结果可能是多样的,有的排版好内容丰富,有的排版差内容差,我们做的就是把最好的结果展示给用户。对于搜索排序,可能产业化的结果分两个,第一种是满足需求的免费内容,特别用户预期的结果。第二种可能是竞价排序的结果,可能付费观看,大部分用户没有付费的欲望觉得不好,少部分付费用户可能也会特别喜欢,但无论如何,前者肯定也会在搜索结果前列。
啊,面到最后没时间了,面试官让我问问题,我就随便问了两个,然后不得不回360电话了,就说我有点事把视频关了,本来面得挺好的,哭
其他的忘了,就记得两道题
第一道n的二进制表示中有1的个数
1 2 3 4 5 6 int re = 0; while(n) { re; n = n&(n-1); } 然后分析复杂度,最后提示下分析出来了log(1+n)
然后分析平均复杂度,我以为从1 到int_max的所有复杂度求平均。所以怎么都分析不对。
最后才知道是每个的复杂度,晕,面试官告诉我是log前面的系数是0.5。
第二道:
1、建个链表
2、打印链表
3、反转链表
反转链表写的不好,左右边界各判断了一次,正常情况下只判断一次就好,但面试官说也OK,多做一次时间影响不大,结果正确就好。
4、排序链表
做的是真难受,臭牛客,哼哼。写错个变量都指不出来,改bug改到头秃。
排序链表写的是链表快排,最后发现复杂度不是nlog(n),因为我L部分的尾部没有指向mid(base),导致我最后写了个找L部分的尾部,把这一步优化了就没问题了,但是面试官说也行吧排序的结果不会错。
最后问问题的时候,我一边问一边调试,最后终于把链表快排调对了。然后和面试官说我调出来了,就匆匆结束了这次面试,很难过。因为马上360就是二面,我总不能为一面放弃二面把,这里我情商不够处理的不好,哎,难受。面试官人都挺好的,都是我的问题。
面试经验肯定是面的越多越丰富的,从最初乐鑫的笔试挂,到字节跳动笔试不会写输入流(第一道题我本地1分钟就A了,然后不会写输入流,试了15分钟,然后写了第4题,结果本地能过线上报编译错误,我就很生气了,何况这个输入流更复杂我就直接放弃了)笔试直接挂,到现在面试一点也不紧张,可以和面试官愉快吹牛逼了,所以说多点经历也是挺好的(补充,这次字节笔试3.6/4,还可以)
##部分已挂的公司,吐槽一下: OPPO 简历挂?显示简历过,没有通知面试,可能原因是没填内推码,身边的字节大佬也和我一样简历挂。 . .问了去面试的算法同学面试题目婴儿难度。 还有提前批没过,但是简历状态还有,是已处理,不能再次投递。 . . VIVO 笔试挂。 .我真没想到笔试还能挂,不过VIVO SP给的还不错,问的问题也不能说难?没中奖呀难受很气,想想要不要投步步高?三顾茅庐了要阿里内推挂(本来在池子里,然后部门的那个人发邮件给你内推,内推完刷新界面挂,可能原因是我扫了内推连接,但是我一般是不选择内推,想一想阿里内推人也不容易,互相体谅吧) 还有一个不知道哪里的公司挂了我简历,原因是简历是牛客上创建的,都不知道什么时候创建的,简历上面很clean. .
18-28 作者:工大菜鸡链接:(https://www.nowcoder.com/discuss/295287)
18. 顺丰sp和ihandy牛客专场:
开篇就是吐槽,我为什么写这个?不是因为顺丰面试有多难,而是顺丰答应给我的二面,到现在都没给。 . .从8月1号顺丰给了我人生中第一次公司面试到9月28号我结束秋招,在这期间顺丰不断推迟二面时间,现在又给我推到了10月中旬,不得不说,顺丰的hr还真是佛系呢。 ihandy这货更狠,给我答应的一面到现在都没兑现,每次打电话过去问hr,都是同一个回答:马上帮您安排,然后我就继续傻傻的等一两个星期,循环往复。
1.自我介绍,为什么转行,你原来实验室干的什么?:因为喜欢算(qian)法(duo),原来实验室干的导航制导与控制;
2.介绍比赛,做了哪些数据的清洗,数据增强的处理?作了哪些特征?怎样提取特征的,为什么会想到这个特征呢?:balabala如实说,还说目前进入了复赛,正在复赛准备阶段XXXXX啥的;
3.我看你比赛用到了xgboost和lightGBM,那说下XGboost原理吧:额……不会;
4.那说下LightGBM吧:咳咳,也不会;
4.额那说下GBDT总行了吧:额……还是不会;
5.那你会啥?我:LR。(面试官快哭了TT);
6.那好吧那你说说LR吧:balabala;
7.你听过CATboost吗? Me: No. (面试官再一次哭了);
8.说说LSTM的原理:balabala还口述了输入门,更新门,输出门的公式;
9.你有什么想了解顺丰的吗?我:X$Y*&^%(&%@1!2¥……;
我知道我答的很菜,但我还是厚着脸皮问了面试官我的表现咋样,能否就我的面试情况和简历提点建议?后面每一次我视频面试我都会向面试官问这个问题,他们也都会热心的给我提出建议,帮我修改简历,收获很多。
结果:没想到一面给我过了,但是二面迟迟不到。
19. 滴滴牛客sp专场(二面挂):
惭愧,当时在面试的时候还以为滴滴是小公司,问面试官问题的时候,我居然问了滴滴的业务存活情况……
1.自我介绍,转行之类的问题;
2.了解那种算法挑一种介绍下:我说了LR,刚说到交叉熵这儿,面试官打断:那你说说LR为什么用交叉熵作为loss函数。我:因为lr从概率密度函数推导出来的对数极大似然函数就是交叉熵函数。面试官说:不全对,其实mse是万能的loss函数,每个模型都可以用mse作为loss函数的,那为什么lr不用mse呢?我:不几道。面试完了才想明白,mse的导数里面有sigmoid函数的导数,而交叉熵导数里面没有sigmoid函数的导数,sigmoid的导数的最大值为0.25,更新数据时太慢了;
3.说说XGB:在上次顺丰面完后,我仔细学习了一遍xgb,这一次大致回答上了面试官的问题,我说了GBDT,再从XGB是如何改进GBDT的角度引入了XGB的一些概念,比如预排序什么的,引入正则项和二阶泰勒展开什么的;
4.介绍比赛,介绍如何分工的,如何构建特征的,如何选择这些特征的;
5.说下常见的处理过拟合手段有哪些?我说了l1,l2,神经网络里的dropout,增加数据量等等,面试官问还有吗?我:不知道了。其实后来才知道bagging和boosting也是降低过拟合的手段,以前还以为仅仅是种特殊的模型。
同样向面试官问了我的表现情况以及如何改进,面试官也热心的提出了建议。
1.自我介绍,大致介绍项目。
2.聊比赛,聊人生。 . . . .大概聊了30多分钟。
3.问你会不会什么操作系统,数据库啥的,c++会不会。答:都不会
二面很自然的就挂了,从滴滴的面试可以看出,其实国内的很多公司都挺看中开发能力的,只会python和跑跑模型应该达不到绝大多数公司的要求。
20.快手牛客sp专场(二面挂)
1.基础问题都是老生常谈,问题和回答略了
2.算法题:求最长回文子串,leetcode原题,动态规划求解最好,但我当时不会,用的是中心展开法,勉强做了出来。
1.上来一道leetcode上的hard算法题:求最小编辑距离。不会,直接gg
2.其他闲聊,聊人生
大概等了10多天,官网上给我挂了
21.依图(一面挂)
是我最惨的一次面试,面试官笑眯眯的,也没让我自我介绍,上来四到算法题,一道一道来的那种,题目都忘了,只记得每道都把我摁在地上摩擦,差不多情况就是这样:
面试官:出道算法题吧,第一道:XXXX。
我思索10分钟:不会;
面试官:那我们做第二道吧:XXXX。
我又思索10分钟:不会……;
面试官:那再来一道:XXXX。
我寻思我都这么惨了放过我让我走吧求你了,于是思索了两分钟说:还是不会……;
面试官:那再来一道:XXXX。
我:gun!
后来视频面试结束的时候,我专门去查了这几道题目,他们都有一个统一的解法,那就是动态规划,抱歉我之前真没听过动态规划啊啊啊啊啊,我从此下定决心,进行dp的专项练习。
22.腾讯(一面挂,好后悔没有抓住唯一一次进鹅厂的机会)
其实面试官问的问题都很简单,但是当时比赛刚做完,非常疲惫,不想学习,没有学习新的东西,也没复习旧的东西,就这样躺尸了两天,然后腾讯的技术面试官晚上打来电话面试:
1.自我介绍,介绍比赛
2.看你用到了朴素贝叶斯,说下原理吧。我心想这还不简单,刚要张嘴,才发现坏了,啥叫朴素贝叶斯来着?我给忘了!我就支支吾吾的说:用了贝叶斯公式,然后加上了观测独立假设,面试官无语……
3.说下xgb,lgb和gbdt吧。这个我会,由于前面问了很多了,不用复习也能张口就来。
4.我看你的另一个比赛用了bert和CRF,说说CRF的原理吧。我:……不会(后悔没看)
5.那说下bert的原理吧。我:……还是不会(好后悔啊,太懒了,还是没看)
后面balabala的问了一堆,我都回答上了,但是前面这几个没回答上的太伤了,一面挂
23.远景(四面挂,boss面挂的,真是挂的莫名其妙……)
都是随便介绍项目,问一些基础的问题,没啥难的,印象深刻的是二面面试官问到最后突然让我用英文介绍下比赛里面是如何选择特征的,我用我的工地散装英语一顿乱说,结束时面试官说嗯很不错,我内心:靠,你压根就没听吧!
四面是boss面,现场面的,聊人生,跟我聊了一个半小时,全程也穿插问些问题,我都回答上了,跟boss聊得非常好,然后就给我莫名其妙的挂了……,我想原因应该是boss临走前给我说了一句:你需要多注重工程能力。他可能嫌我工程项目很少吧。
24.百度(一面挂)
百度的笔试就令人印象深刻:
选择题啥都考,很杂,操作系统,数据库,c++,python,机器学习,深度学习啥都考
两道问答题,其中有一问印象深刻:说说针对中文,BERT有什么可以改进的地方。我心想:你丫不就是想吹自己的ERNIE嘛,我就写了ERNIE针对BERT做出的改进,基于知识的mask训练方式,基于知识图谱的改进等等
一道设计题,让你设计一个系统:可以写出春联,必须满足他的要求,平仄音节都要对上,我直接BERT+CRF+GPT一顿乱写。
编程题:RGB括号,我猜应该是道dp题吧,链接:https://www.nowcoder.com/discuss/254095
想看的童鞋可以看一看,无视我的答案就好,我到现在都不知道我的答案对不对。
1.红黑树的几个特点。只答上两个,其实我根本不会
2.python的装饰器@的用法。 Won't
3.编程,写一个函数,实现python的继承,数据的交换,类中的全局变量等等。写上了一半。
4.快排(不能用简单粗暴的那种,要空间复杂度最低的)和堆排序(必须用最小堆实现)。不是让你写代码,而是给你一个数组,直接让你用快排和堆排的思想直接一个元素一个元素的演示给他看,这个我答上了,幸好之前自己实现过弄懂了。
5.算法题dp两道:最长公共子串,最长公共子列,都是dp题,幸好专门看了九章算法,专项学习了dp,简单或者中等的dp题还是可以一战的,这两道也是lintcode上的原题,有兴趣的童鞋可以查查。
6.介绍xgb,我说到“xgb的预排序是相对于暴力求解的加速”这儿,面试官打断了我,反问我:那具体是为什么加速了呢?一个特征下的数据,没有预排序和预排序了,不都得遍历一遍才能求解出最优分裂点吗?
这个问题给我干蒙了,其实这个问题我之前思考过,但是太懒了,心里不断麻醉自己面试官不会问得这么细,就直接忽略了,没再去想。百度面试完以后我看了原论文的伪代码才明白为什么。所以再次建议尽量能读一读原paper。
7.介绍下xgb是如何调参的,哪一个先调,哪一个后调,为什么?哪几个单独调,哪几个放在一组调,为什么?哪些是处理过拟合的,哪些是增加模型复杂程度的,为什么?我寻思你十万个为什么呢?总之就是被为什么问的头昏脑涨,出了门我就知道肯定挂了。
25.搜狗(面试流程结束)
1.lr为什么用sigmoid函数作为概率函数。我:lr是基于伯努利分布为假设的,伯努利分布的指数形式就是sigmoid函数,而且sigmoid函数可以将数据压缩到0-1内,以便表示概率。
2.介绍下word2vec,说说word2vec和fasttext的区别。我:balabalabala,说的貌似还行,面试官点头
3.印象深刻的推导:
推导下word2vec里面的一个模型CBOW吧。后悔没看,哭了,我说不会。
那推导下SVM吧。这个我会,推出来了,但是到对偶条件这里,面试官问为什么能用对偶条件,我没答上来,还是太菜。
那再推下lr吧。这次顺利的推了出来,面试官问的问题也回答了上来。顺利通过了。
4.算法题:求最长回文子串,没错,和前面快手一面问的笔试题一样,答上了。
5.概率题,严格来说,这道题不是我遇见的,是我同学面搜狗的时候被问到的,我觉得很有意思,而且我们都不知道答案,请大佬解答:
一共54张扑克牌,我抽了几张牌(大于2张),有两种场景: 1.我说我有小王; 2.我说我有大王; 这两种情况,哪种有双王的概率更高?
这题我是一脸懵逼的,求各位大佬解答!
2.搜狗二面:
1.xgb的loss函数的推导(mse以及非mse形式),以及求解推导。
推出来了;
2.求最大连续子列和,要求时间空间复杂度最小。
Very simple;
3.xgb是如何实现并行的。
保存预排序的block,用进程间的通信并行寻找最优分裂点。
4.lgb的直方图优化算法说说。
随便说了说,面试官也没深问。
5.讲比赛,讲项目。
balabalabal总之二面持续了差不多一小时
没啥好讲的,聊人生,聊转行,hr说需要综合各地的信息来筛选,让我回去等消息。
26.OPPO(offer)
我整个秋招所经历的所有面试官里面,一共面了三个非常有水平的面试官(我个人觉得):一个是远景的那个boss,微软亚研院呆了四年,百度呆了六年,google呆了六年。和我聊现在的行业形势以及各种模型的应用,很多问题都会直击要害,一语中的。和我的聊天中看出了我工程能力不足,跟我聊了一个半小时,为我未来提出了一些建议和规划,我很感谢那位大叔;第二个是百度的一面面试官,他好像就是住在我肚子里的蛔虫一样,总能在我的回答中揪出我不会的致命知识点,给我痛击,真的是怕啥他考啥,他的基础非常扎实,而且反应和判断非常迅速;第三个就是这个oppo的一面面试官,根本不问固定知识点,就问一些模型、手段、措施背后的本质并且举例说明,在你运用的实际场景中有没有见过。
刚开始都没让我自我介绍,直接让我说比赛。我:balabala,我介绍到CRF的时候,面试官打断我说:“你说CRF说了一大堆,那他它本质是个啥东西,我不要听那些定义,你给我说本质”。我:……支支吾吾……,说它应该是个函数,balabalaba一顿编。
然后他也没说对错,继续问:说下attention吧,我:又是一顿balabala,讲到注意力那儿的时候他问:你能举个case吗,用了attention和没用attention时候的对应的隐状态在哪些地方有区别你有去观察过吗?我:又是一顿瞎bala,他又没说对还是错。
又问我看你这里用到bilstm它和lstm的区别在哪?举例说明,用了和没用的效果。我心想:哎呦终于有个会的了,结果回答完他还是那副样子,又是啥也没说,我心想对还是错你倒是给个准信啊。
又问到了ELMo,让我说明ELMo是如何做到动态词向量的。我:把每个词输入模型,得到的隐状态相加就能得到不同的词向量;
面试官:那说下ELMo的缺点。我说:第一就是多层bilstm天生的缺点:“自己看到自己”的现象,然后举了个例子,balabala……。第二就是无法并行训练,以上两个毛病都可以用bert去改进它;
他又问其实我们可以用加入位置嵌入的方式来改进这个无法并行的问题那为什么非得用bert呢?我一想确实facebook貌似在之前就提出了位置嵌入+textcnn的方式来并行训练。完了,给自己挖坑了。于是乎我就扯了一堆bert里面self-attention的优点,哈哈哈我真是机智。
然后他依旧啥也没说,又让我介绍bert,并且问了multi-head的好处,又问我它的实际物理意义是什么?为什么能这么想?举个case说明下。我用尽了我毕生瞎编的本事,凭借着我自己的一点理解硬是说了10分钟,然后结束了是对是错他还是啥也没说……………………
又让我写LSTM的公式,勉强写上了
又问了我一个实际场景问题:用一个模型去分类一堆数据,在training阶段就无法收敛,反复震荡,有可能是什么原因,你有没有在实际场景中遇见过?
我:可能数据是标注错误的或者是随机数据,面试官补刀:假设数据没问题,那是什么原因?
我:那就是模型无法拟合这个数据或者不适合做这类数据的分类,面试官再补刀:假设模型也没问题,足够复杂。
我:那有可能是优化过程陷入了局部最优,而且一直无法跳出,面试官再次补刀:假如优化过程没问题。
我:那就是正负样本极其不均,网络没法学习到东西?面试官:我没说一定是神经网络模型,而且那再假如样本正负分布是均匀的……
我:……那我真没遇见过这样的……
面试官当时貌似不太满意,跟我聊完居然把我的简历给对折了起来!我第一次见这种场面……,心想:哎呦我去凉了,可能一出门面试官就会把我的简历扔垃圾桶里了吧……。面试官让我回去等,晚上如果收到消息就是过了,没收到就是挂了。晚上感觉想哭,毕竟OPPO是我蛮喜欢的一个公司,结果快睡着了突然来了一个短信提醒,说我OPPO面试过了……,得,这下倒好,睡不着了……
1.聊项目比赛,一路下来没问啥知识点,没啥大问题
2.画出ESIM这个模型的结构,并作介绍
3.面试官看我航天二院的项目跟导弹拦截有关系,是用GRNN预报弹道的,就让我介绍下GRNN的网络结构以及原理,还问预报精度怎么样。我说这个题目现在是我的毕设,还没做完呢……
面试官:哦……那你给我说说你要拦截的这个HTV-2是个啥?
我说:是一种美国的临近空间高超声速飞行器,可用于导弹上,对我国国防安全造成威胁,balabalabala……
面试官好像突然来了兴趣,一直问我导弹的事,跟个好奇宝宝一样:这个HTV-2很厉害吗?
我:点头,嗯嗯嗯
面试官:这个HTV-2有啥特点?你们用经典的方法一般是咋拦截的?balabala……
我:额……这些都是保密的……
面试官:哦,那没事了。
4.聊到后面问我有没有了解过一些其他的搜索排序算法,比如list-wise的,pair-wise的,然后给你一堆非常大的大数据,如何实现全数据的搜索排序,我凭借我的理解大致回答了一些,面试官说还不错,让我等下一面
我拿起我的oppo find x给hr一顿瞎BB,意向书成功到手,虽然是白菜价,但是OPPO是我很想去的一家公司,尤其是近几年开始搞些奇奇怪怪的手机出来以后越想去了- . -。
我原以为一面二面回答的不太好的情况下OPPO也愿意要我,而且hr说今年OPPO机器学习投递的简历,光筛选后的985计算机科班硕士的就多的吓人,所以我感觉OPPO今年应该在机器学习这个岗位上招人需求有很多。没想到签约会时候问hr才得知整个哈尔滨加吉林地区,机器学习的offer只有两个……,瞬间脊背发凉……
27.58同城(口头意向,拒了)
其实能面试58我是非常意外的,因为58的笔试编程题我一道都没做出来,选择题差不多一半都是瞎猜的,甚至面试的时候,面试官还把我做错的选择题拿出来又问了我一遍,并且我还是答错了……囧,而且三个面试官都问了我:为什么编程题一道都没做? ………好尴尬,太奇怪了! ? 58怎么会给我面试呢?不过面试时我表现的还不错,最后也拿到了口头意向,但已经签了OPPO就给拒了。
1.还是各种介绍,自我介绍,比赛,项目,为什么转行啥的。
2.我看你用了ESIM这个模型,把模型结构画一下,并且告诉我为什么有用。 Very simple.
3.算法题:一个数组中和为k的所有二元组,要求时间复杂度为O(n)。这个也很简单。
4.介绍下BERT以及CRF。老生常谈了,他也没深问。
5.算法题:最小编辑距离,没错又一次被问到了,dp常规思路,只不过需要多考虑边界条件。完美解决。
6.算法题:一块钱一瓶水,三个瓶盖能换一瓶水,问20块最多能买多少瓶水?(用编程方法解决。)面试官午饭没吃,饿的等不及了,我刚想了一分钟还没写出来,面试官说一面就到这儿吧,我以为他要把我挂了,赶快急急地说了思路,面试官说没事你一面过了,走去吃饭吧,噗.......
2.58二面:
二面大多数时候都是我在问面试官,一时间搞不清楚谁才是真面试官……问了些58的业务,以及业务中需要的模型,算法等等的。聊得很开心,当然也有些坑,面试官会穿插着问些技术问题,比如在谈到58的软件内搜索业务的时候,面试官问如何在少量数据的情况下对用户的输入进行快速的意图识别。我说了几条:可以用信息熵来确定用户输入主体,用聚类来做些简单的意图识别等等。
3.58hr面:
一个很漂亮的大姐,很亲和,又是聊人生,结束后告诉我回去等通知。
28.华为(offer,拒了)
我申请的是华为消费者bg软件部的人工智能工程师,自然语言处理/语音处理方向。我听说今年很难进华为,想进消费者更是难上加难,但是我仍然没感觉到有多难进……可能华为比较看重课业成绩和学历吧,因为我感觉我只有这个优势… …
上来两到算法题,不过都是很简单的leetcode原题,题目我给忘了,但是都答上了。但是我感觉面试难度看脸,有同学就被甩了两道dp题没答上来一面就挂了。
问的问题都很基础,知识点都是前面的那些,没有什么印象深刻的问题。
算法题:求一个数组中和为k的最长连续数组,暴力法解决的,面试官说没有复杂度要求。
问了槽位的概念,这个我之前真没听过,哎,还是太菜了。
问了些其他的基础问题
聊人生,聊规划,圆满结束,offer到手,签约会的时候,hr说给我安排到北京了,我不太想去北京,而且薪资也不高(我听到的消费者的同学都一个均价,什么硬件研究院、智能车、无线的均价都比消费者高),而且最重要的是,他把我安排到了消费者软件部下的智慧城市这个三级部门,大概率是语音方向的,我不是特别喜欢,就给拒了。
约定电面晚上8点半(阿里是加班到9、10点的节奏?)
主要是商汤无人车实习的项目,问我比baseline提升15个点,怎么来的。
从数据迭代、backbone、模型修改几个层面上说了下。
挑一两个有意思的优化说说,说了cascade、hdcnn的结构,为什么用这种结构。
项目中出现什么情况,怎么解决的?主要就是说小目标检测的解决方案。
对caffe源码熟悉程度。(我扯了扯源码的底层设计模式,数据流怎么流的,如何添加新层、cuda代码的细节)
open question
给了一个情景,如何训练模型、调优。(题目很空,主要考察你对深度学习的理解)
根据需求(前向传播时间、模型大小),确定模型和基础网络,跑第一版模型。(举了个栗子) 判断模型是否出现过拟合的情况,来决定下一步的优化方向。 结果分析(confusionMatrix等),分析问题,将论文中的方法套上去,如果没有自己创造。(又举了个栗子)
softmax、多个logistic的各自的优势?1、类别数爆炸,2、推了下softmax反向传播的公式,来对比两者的优劣。
算法(走流程题) 字符串判断是否是ipv4,c++。(可能是时间不多了,大佬想下班了)
全程大多都是我在说,没有太多互动。后来经过源神@邢源建议,还是要故意给面试官漏点马脚让他们来怼我们,然后再怼回去,并说明不这么做的原因,不然不好拿高评分。(卧槽,真的是套路深啊~)
大佬貌似涉猎很广泛,对每一个领域都很熟悉,基本上简历中的很多细节,他都能找到点怼我。(聊了很久)
项目是从头怼到尾,主要考察对项目、深度学习的理解。
大佬对我的trickList很感兴趣,我猜想他现在做的工作和我的很相似。
Anchor大小、长宽比选取?我说了业界常用的方法(YOLO9000中的方法),并提了一个更优的方法。
为什么要深层、浅层featureMap concat?提了点细节和我踩的坑,需要数量级上的调整,不然深层的feature可能会被压制。
Cascade的思想? 说了下我的摸索的一个过程。改变样本分布,困难样本挖掘,能达到比较好的效果。
文字识别使用ctc loss的一些细节。
设计一个情景,倾斜字体检测,问我有什么好的想法?(我觉得应该是他现在遇到的问题)
数据增强,加入形变扰动。
非end-to-end版本:分别训练检测和分类,举了之前做过的一个文字识别的项目的实现。
end-to-end版本:加入仿射变换学习因子,学习字体倾斜的角度和形变。
在商汤发论文了吗?
没有,正在攒,项目比较重,但有一些work和insight,讲了下思路。(大佬听的很认真,貌似被我的故事打动了[捂脸])
为啥要换实习?日常吹水。
评价:大佬主动评价我对模型理解挺好的,工作做的挺深的,说等下一面吧。
体会:二面面试官说话很快,思维比较敏捷,觉得和这种人讨论问题很欢畅,如果一起工作会很赞。
以后面试说话语速应该快一些,让人觉得思维比较敏捷,这个可能会有加分项吧。
大佬应该是搞backbone模型优化的,问了我怎么迭代基础网络的版本的,日常扯论文,自己的实验结果和理解。
前两个卷积层通道数不用很多,主要是提取边缘、颜色信息,少量的卷积核足矣。
skip connection有什么好处?推了下反向传播公式,根据链式法则,梯度可以直接作用于浅层网络。
初始学习率怎么设?这个我真的没有总结过,只是说一般使用0.01~0.1。
mobileNet、shufflenet的原理?说了下原理。
为什么mobileNet在理论上速度很快,工程上并没有特别大的提升?先说了卷积源码上的实现,两个超大矩阵相乘,可能是group操作,是一些零散的卷积操作,速度会慢。
大佬觉得不满意,说应该从内存上去考虑。申请空间?确实不太清楚。
问我看过哪些前沿的论文?说了说最近两个月的优质的论文。
扯到了tripleLoss,大佬问样本怎么选择?随机,然后就被大佬嫌弃了。装逼失败,这块确实没怎么深入研究。
为什么用multiLoss?多loss权重如何选?训练普通的模型使其收敛,打印反向传播梯度的大小,这表示该task的难度,以此作为loss的权重,然后我补充说了下可以搞一个动态的loss权重,根据一段时间窗口来决定loss的权重。
凸优化了解吗?牛顿法、SGD、最小二乘法,各自的优势。
凸优化其他东西呢?我说只有一些零散的知识点的记忆,纯数学,没有很系统的研究。(面试官貌似数学功底很好,只能认怂)。
感觉有点虚,我尝试着往我会的地方引[捂脸]。 工程上如何对卷积操作进行优化?答:傅立叶模拟卷积。大佬不满意,说那是cudnn早就实现的,还有什么优化吗?(确实不知道,甩锅给工程组)
样本不均衡怎么处理?一个batch类别均等采样,修改loss对不同样本的权重。
三面面试官懂得不少,不过最后还是过了,有时间凸优化还是要系统整理下。
大佬应该不是做深度学习的,应该是机器学习那块的。交流中能感觉出来对这块不是很熟。挑他不会的玩命说,至少让他看到我的工作量。
SVM的KTT条件?说了说,说到SMO实在说不下去了。
GBDT和randomForest区别?原理角度,方差、偏差角度,过拟合角度,谈了谈之前打阿里天池的一些经验吧。
GBDT和xgboost区别?算法上工程上的优化,面试前专门看了,总结的不错,知乎,更多细节可以看看陈天奇的论文,我没看过[捂脸],做机器学习的小伙伴最好看看。
求和接近于target的连续子数组。(lintcode上有类似的题)
最后说让后面应该还有个hr面。


