PALM E
0.0.4

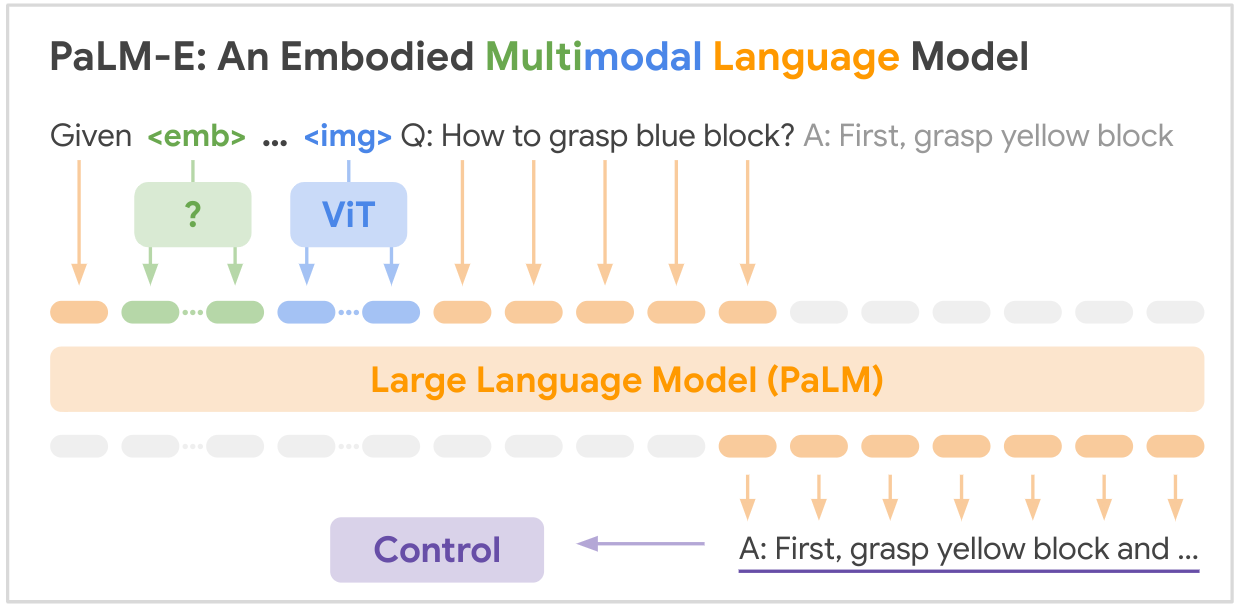
This is the open source implementation of the SOTA multi-modality foundation model "PALM-E: An Embodied Multimodal Language Model" from Google, PALM-E is a single large embodied multimodal model, that can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains.
PAPER LINK: PaLM-E: An Embodied Multimodal Language Model
pip install palmeimport torch
from palme.model import PalmE
#usage
img = torch.randn(1, 3, 256, 256)
caption = torch.randint(0, 20000, (1, 1024))
model = PalmE()
output = model(img, caption)
print(output.shape) # (1, 1024, 20000)
Here is a summary table of the key datasets mentioned in the paper:
| Dataset | Tasks | Size | Link |
|---|---|---|---|
| TAMP | Robotic manipulation planning, VQA | 96,000 scenes | Custom dataset |
| Language Table | Robotic manipulation planning | Custom dataset | Link |
| Mobile Manipulation | Robotic navigation and manipulation planning, VQA | 2912 sequences | Based on SayCan dataset |
| WebLI | Image-text retrieval | 66M image-caption pairs | Link |
| VQAv2 | Visual question answering | 1.1M questions on COCO images | Link |
| OK-VQA | Visual question answering requiring external knowledge | 14,031 questions on COCO images | Link |
| COCO | Image captioning | 330K images with captions | Link |
| Wikipedia | Text corpus | N/A | Link |
The key robotics datasets were collected specifically for this work, while the larger vision-language datasets (WebLI, VQAv2, OK-VQA, COCO) are standard benchmarks in that field. The datasets range from tens of thousands of examples for the robotics domains to tens of millions for the internet-scale vision-language data.
Your brilliance is needed! Join us, and together, let's make PALM-E even more awe-inspiring:
? Fixes, ? enhancements, docs, or ideas – all are welcome! Let's shape the future of AI, hand in hand.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

