lumiere pytorch
0.0.24
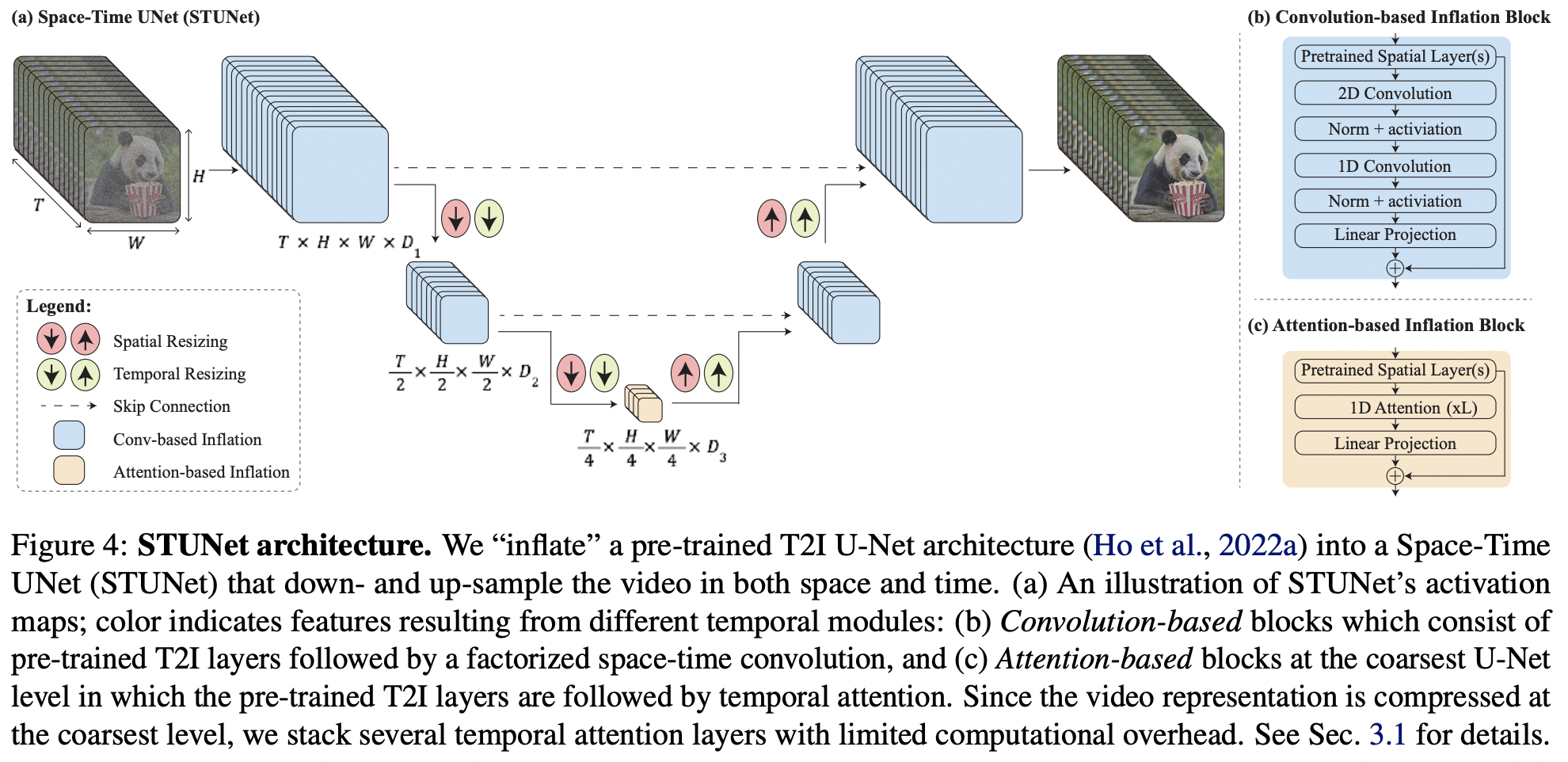
Implementation of Lumiere, SOTA text-to-video generation from Google Deepmind, in Pytorch
Yannic's paper review
Since this paper is mostly just a few key ideas on top of text-to-image model, will take it a step further and extend the new Karras U-net to video within this repository.
$ pip install lumiere-pytorchimport torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet(
image_size = 256,
dim = 8,
channels = 3,
dim_max = 768,
)
lumiere = MPLumiere(
karras_unet,
image_size = 256,
unet_time_kwarg = 'time',
conv_module_names = [
'downs.1',
'ups.1',
'downs.2',
'ups.2',
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2',
'ups.1',
],
downsample_module_names = [
'downs.1',
'downs.2'
]
)
noised_video = torch.randn(2, 3, 8, 256, 256)
time = torch.ones(2,)
denoised_video = lumiere(noised_video, time = time)
assert noised_video.shape == denoised_video.shapeadd all temporal layers
expose only temporal parameters for learning, freeze everything else
figure out the best way to deal with the time conditioning after temporal downsampling - instead of pytree transform at the beginning, probably will need to hook into all the modules and inspect the batch sizes
handle middle modules that may have output shape as (batch, seq, dim)
following the conclusions of Tero Karras, improvise a variant of the 4 modules with magnitude preservation
test out on imagen-pytorch
look into multi-diffusion and see if it can turned into some simple wrapper
@inproceedings{BarTal2024LumiereAS,
title = {Lumiere: A Space-Time Diffusion Model for Video Generation},
author = {Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri},
year = {2024},
url = {https://api.semanticscholar.org/CorpusID:267095113}
}@article{Karras2023AnalyzingAI,
title = {Analyzing and Improving the Training Dynamics of Diffusion Models},
author = {Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine},
journal = {ArXiv},
year = {2023},
volume = {abs/2312.02696},
url = {https://api.semanticscholar.org/CorpusID:265659032}
}

