ChatGPT_WeChat
ChatGPT_WeChat_VoiceChat
Introduction:
Uncertified WeChat public account is connected to chatgpt, new voice chat (English conversation) is added, based on Flask, personal WeChat public account [without authentication] is connected to ChatGPT
--Update instructions:
V1.1.0: (2023.04.13)
-Added streaming response (stream) to alleviate the request timeout problem to a certain extent. You need to install the python package: sseclient-py==1.7.2;
After the streaming response is enabled, a connection (myrequest) will be established first, and then (SSEClient) will be used to obtain the generated text character by character, and finally the obtained text list will be spliced into the reply text. The time to establish a connection will still be affected by max_tokens, so it is not recommended to set max_tokens too large. The key to alleviating request timeouts is that the time consumption of establishing a connection is less than the time consumption of one-time return. Therefore, as long as the connection is successfully established within a given time, the content can basically be returned. The length of the returned content will be affected by the connection time. .
-Delete the most recent messages sent by the user after the request fails or times out to avoid errors in the next reply.
V1.0.1:
- Added option to enable IP detection (to prevent doss attacks);
-Note: If any of wechat-ip_detection and azure-trans_to_voice is true, both appid and secret need to be filled in.
V1.0:
-New voice chat function, access to Microsoft cloud text-to-speech service (free access), to achieve voice conversations (Chinese and English);
-Built-in English learning templates, you can have English-themed conversations by replying to template messages;
- Added WeChat background whitelist IP detection to prevent doss attacks, etc.;
- Added user message frequency limit to prevent malicious message spamming;
- Automatically clean up temporary voice files;
- Automatically clean up temporary voice materials uploaded in the WeChat background;
-Optimize performance and fix bugs.
background:
I recently saw that ChatGPT provides an API interface. I happen to have a server and a public account, so I want to write a chatbot? Give it a try. However, there is only one uncertified personal official account (resources are limited?). The limitations of this official account are:
1. It can only passively reply to user messages. The user sends a message to the official account. The server can only reply to one message for this request and cannot reply to additional messages (customer service messages);
2. Each message must be replied within 15 seconds. After the official account platform sends a request to the server, if it does not receive a reply within 5 seconds, it will send another request and wait for 5 seconds. If the request is still not received, it will send a final request. Therefore, the server must process the complete message within 15 seconds.
See the code for specific processing methods. This is a newbie project, please include any shortcomings and welcome corrections, thank you~
need:
A server (needs to be able to access the openai interface, may need to be overseas~)
If you need to enable the text-to-speech service, you need to register Azure's text-to-speech service. Registration and use of this service are free. Please refer to the website for details: AZURE
WeChat public account: Personal type is enough
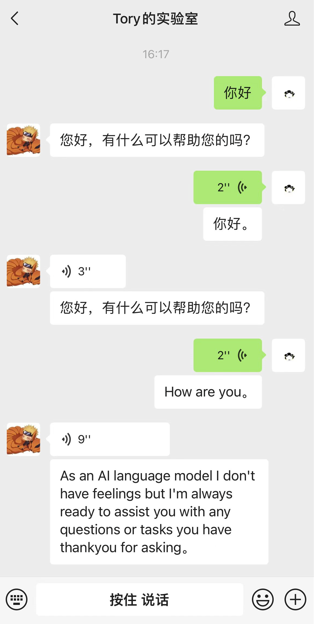
Demo:
Public account: Tory's laboratory, follow and send messages to experience it.
Introduction to public account tweets:
1. Introduction to getting started: ChatGPT has been connected
2. Introduction to the use of voice service: The voice service has been connected
How to use:
Set the config.yml parameters in config:
# 微信相关设置
wechat :
token : " **** "
# 是否获取微信公众平台的ip白名单(用于防止doss检测)
ip_detection : false
# 如果上面的选项为true,下面两项内容必填;如要开启后面文本转语音服务,下面两项内容必填
appid : " **** "
secret : " **** "
# openai相关设置
openai :
#填写openai的api_keys时,要注意前面要加上:Bearer, 可以填写多个,因为单个账号有速率的限制
api_keys :
- " Bearer sk-**** "
# - "Bearer sk-****"
# - "Bearer sk-****"
# 单条消息的长度,这个参数对回复速度有非常大的影响,请不要填太大~
max_tokens : 120
# 模型
model : " gpt-3.5-turbo-0301 "
# temperature,越大随机性越强
temperature : 0.8
# 有时候文本长度超过150,用该参数限制长度避免超过微信能发送的最长消息
rsize : 500
# 对话的保存历史
save_history : 21
# azure文本转语音设置
azure :
# 是否开启文本转语音服务
trans_to_voice : false
# 如上面的选项为false,下面的内容不用填写
# 新定义文本长度,开启后增加处理时间,避免文本太长,处理时间过久,超过15s
max_token : 80
# 是否开启流式响应
stream_response : true
# 密钥
subscription : " **** "
region : " koreacentral "
# 中文语音模型
zh_model : " zh-CN-XiaoyanNeural "
# 英文语音模型
en_model : " en-US-AriaNeural "Start flask
export FLASK_APP=myflask
flask run --host=0.0.0.0 --port=80
# 或者
nohup flask run --host=0.0.0.0 --port=80 >> /home/jupyter/flask/log/wechat.log 2>&1 &Notice:
1. When filling in openai’s api_keys, be sure to add: Bearer in front. You can fill in multiple api_keys because a single account has a rate limit;
2.max_tokens has a great impact on the reply speed, please do not fill it in too large.


