py spider for wechat
1.0.0
Secondary development and PR submission are welcome?
Use Python to build a crawler to crawl historical articles and content of designated public accounts, and support filtering articles using keywords.
F12 to open the following interface, and switch to [Network] 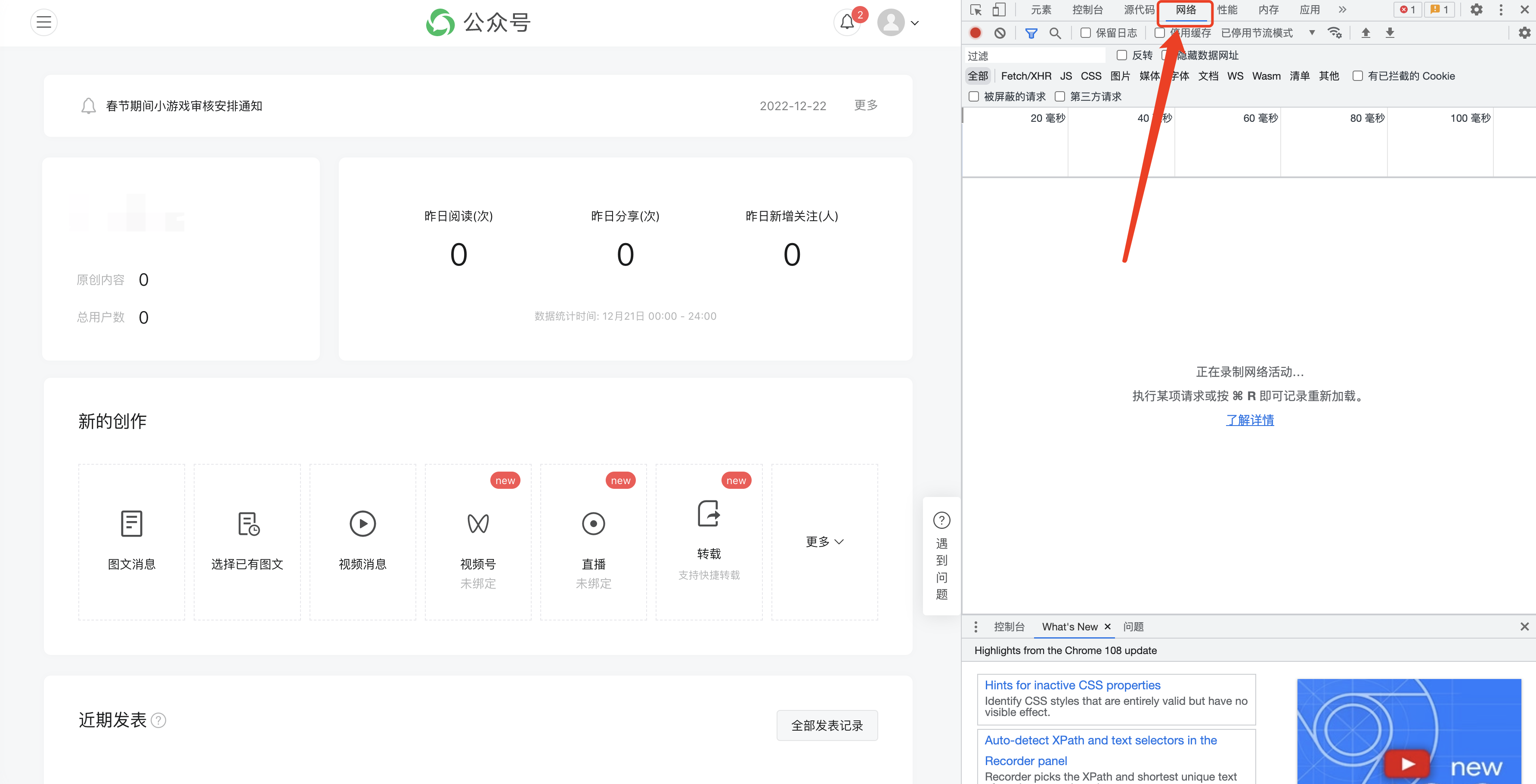
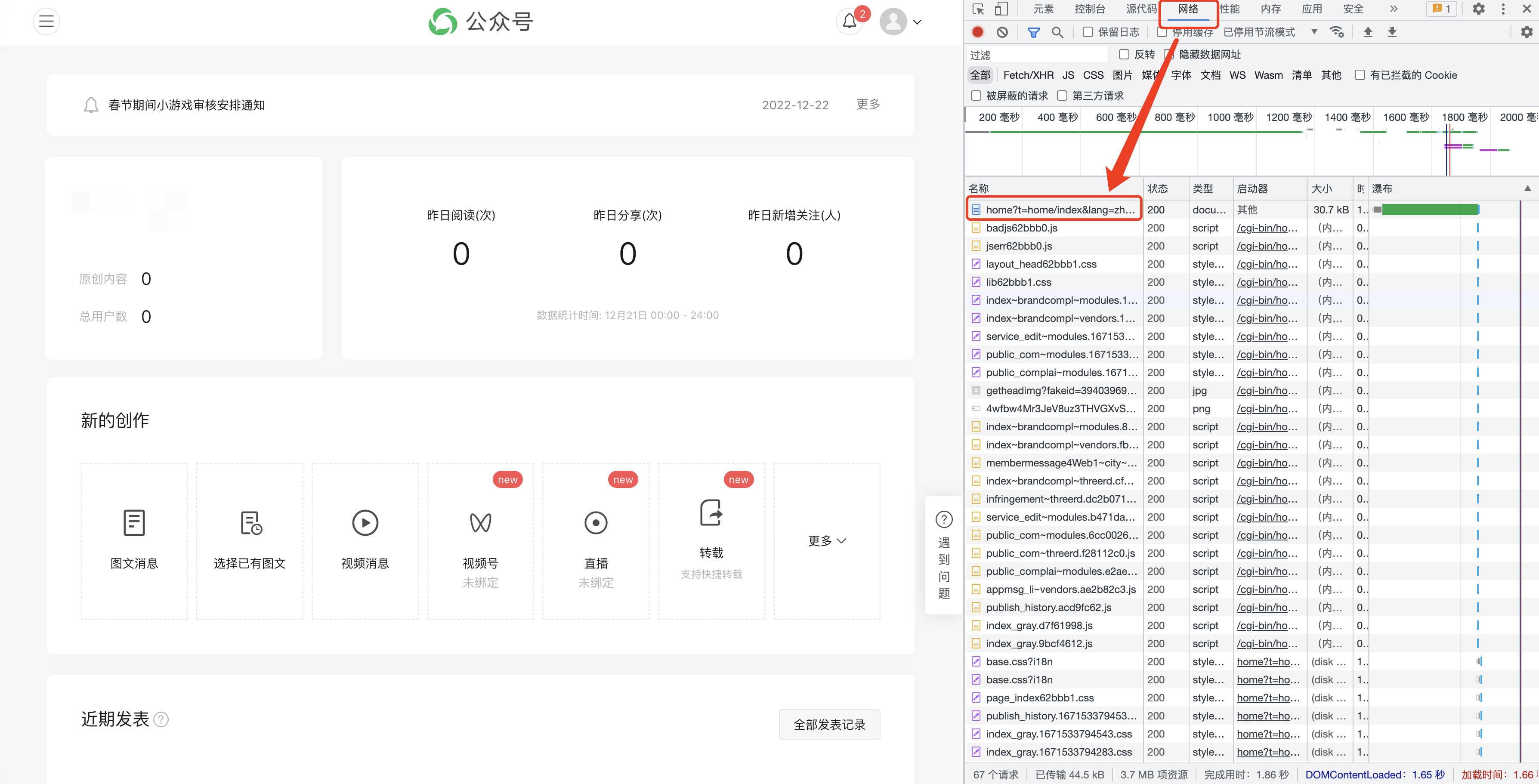
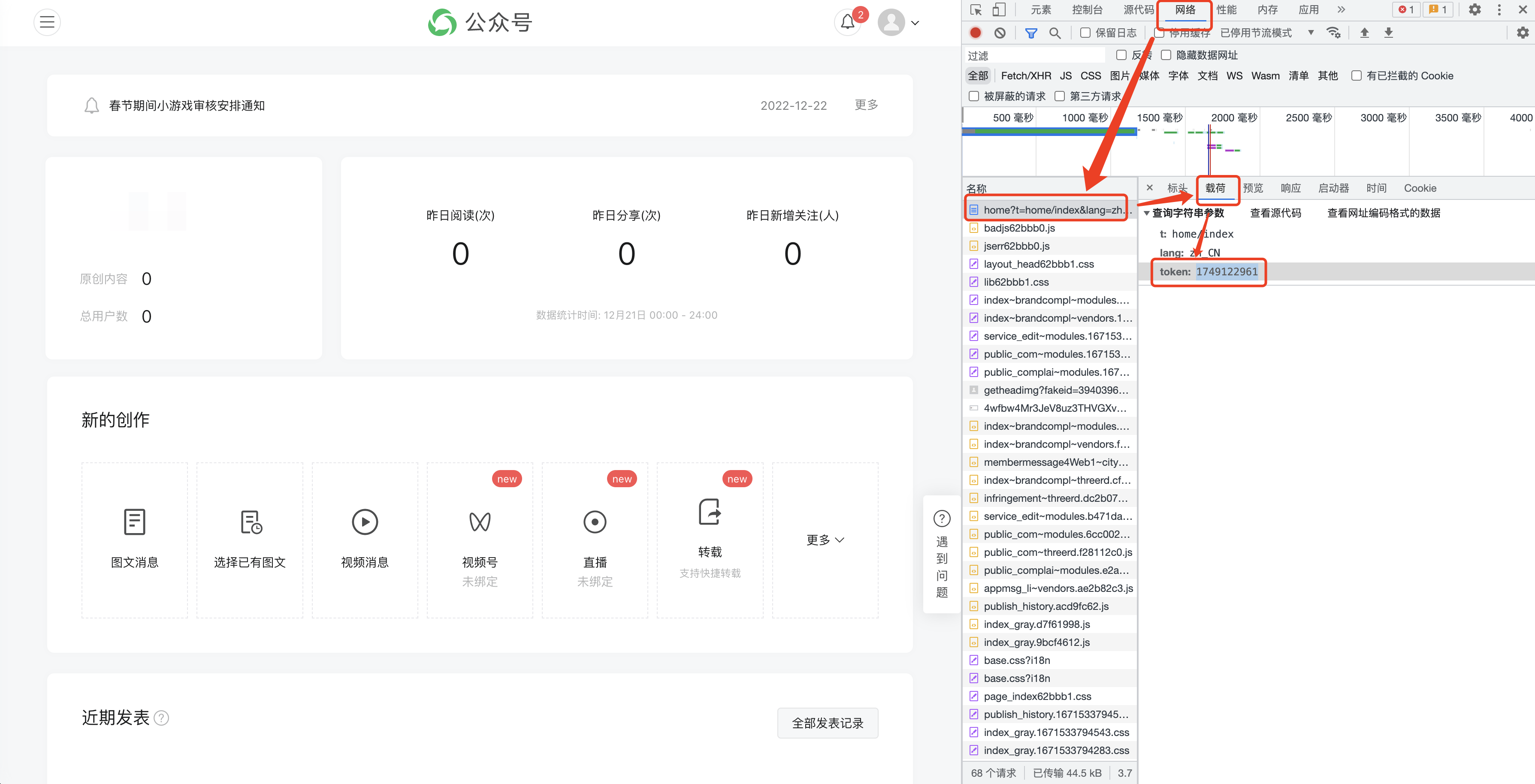
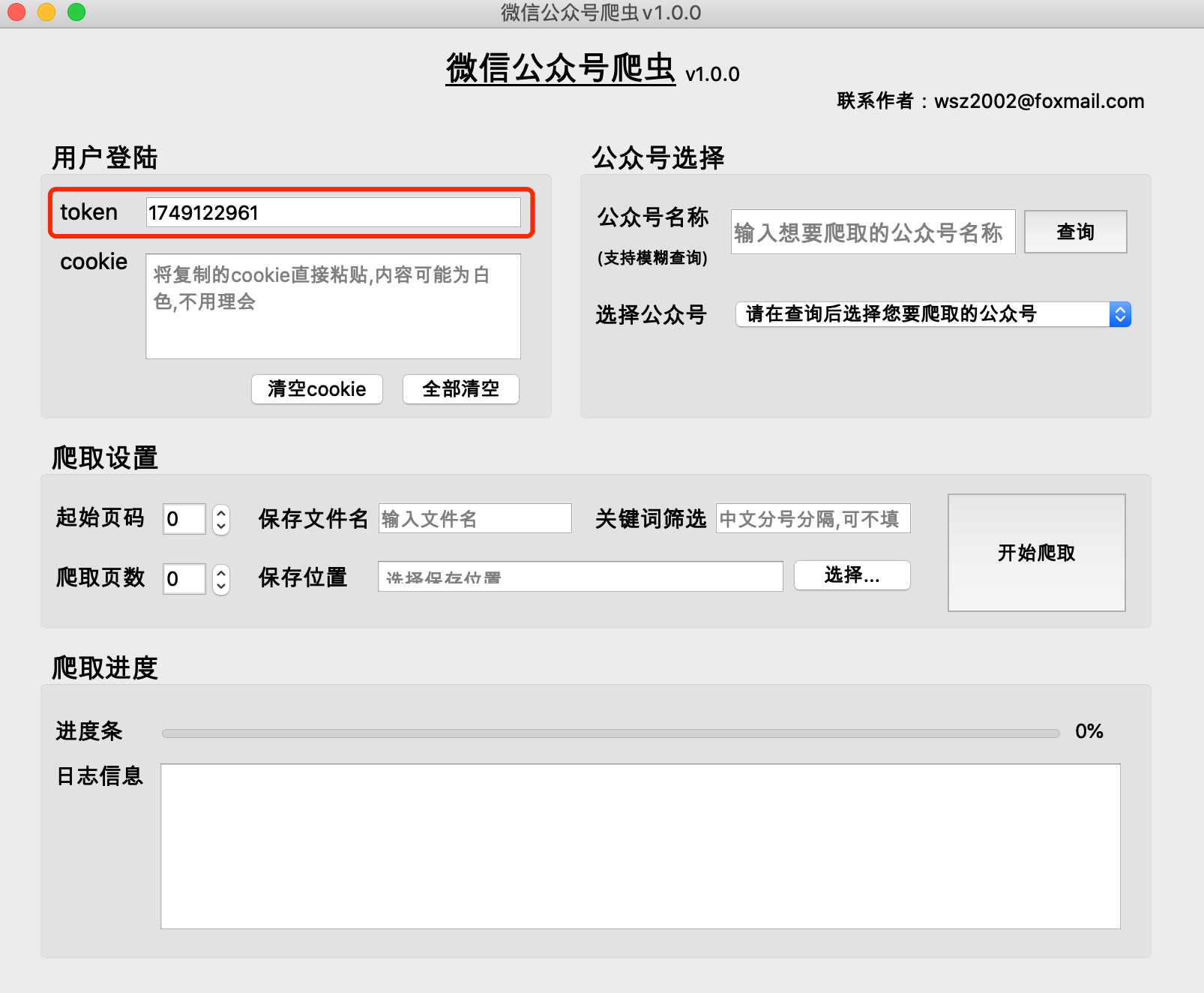
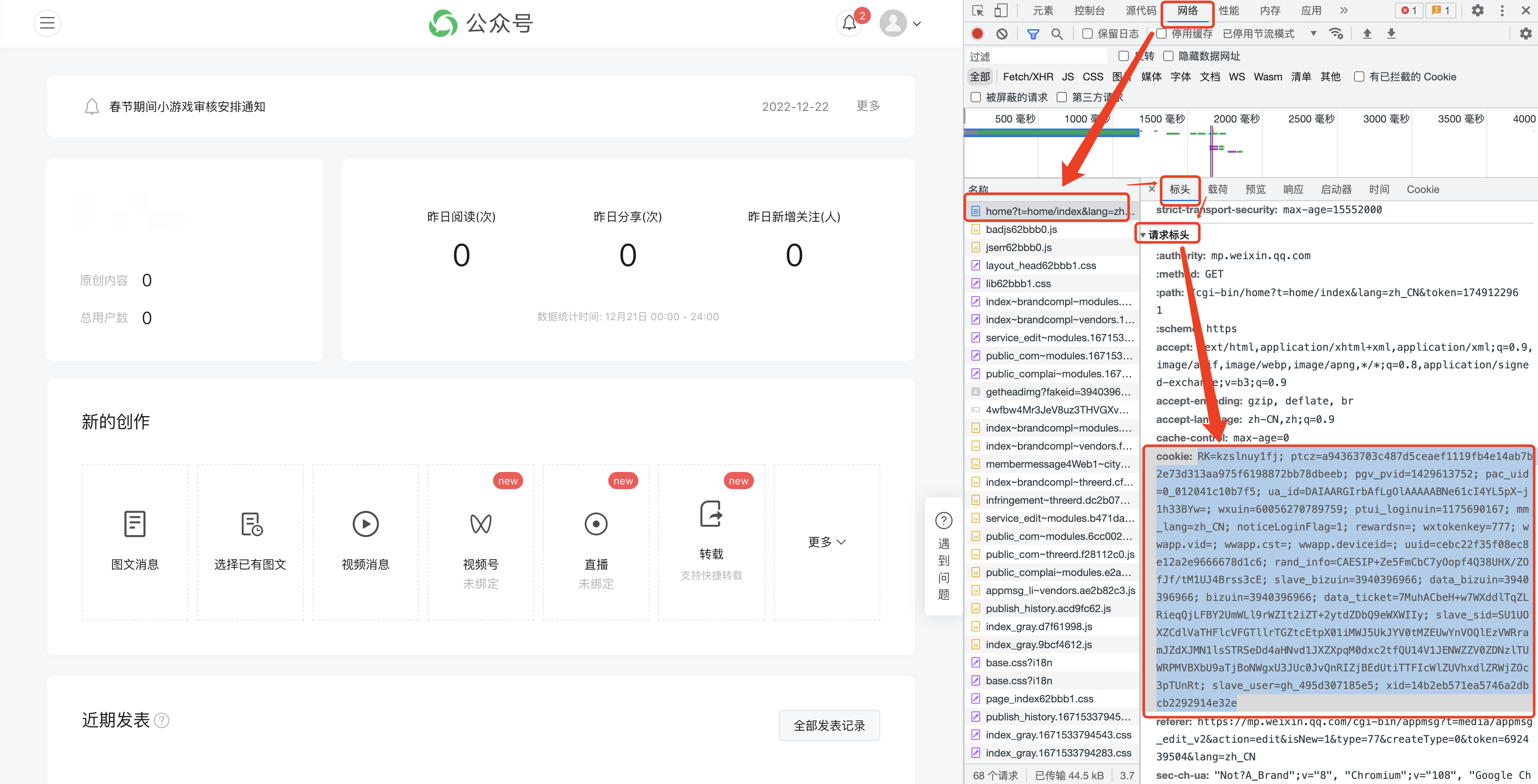
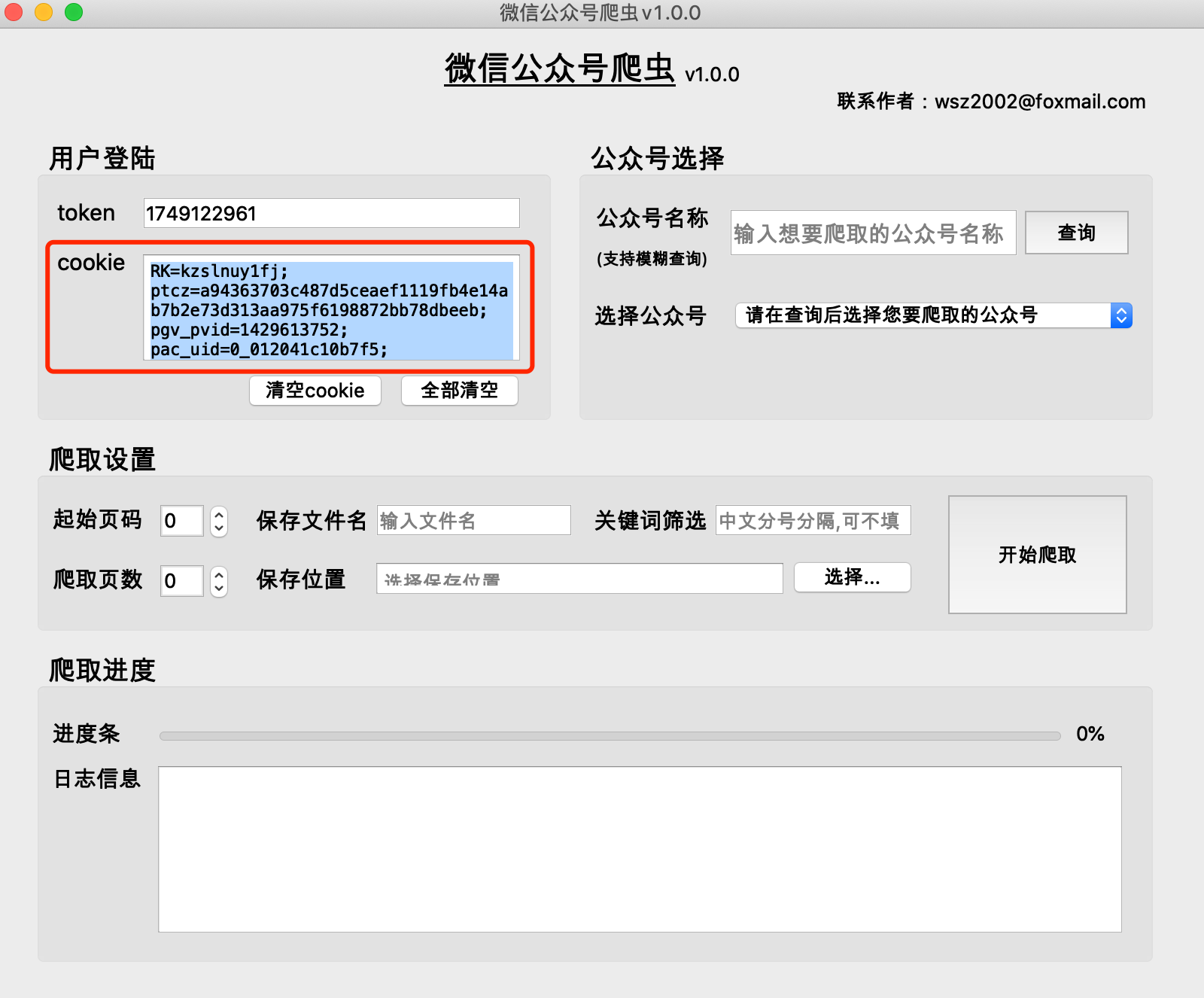
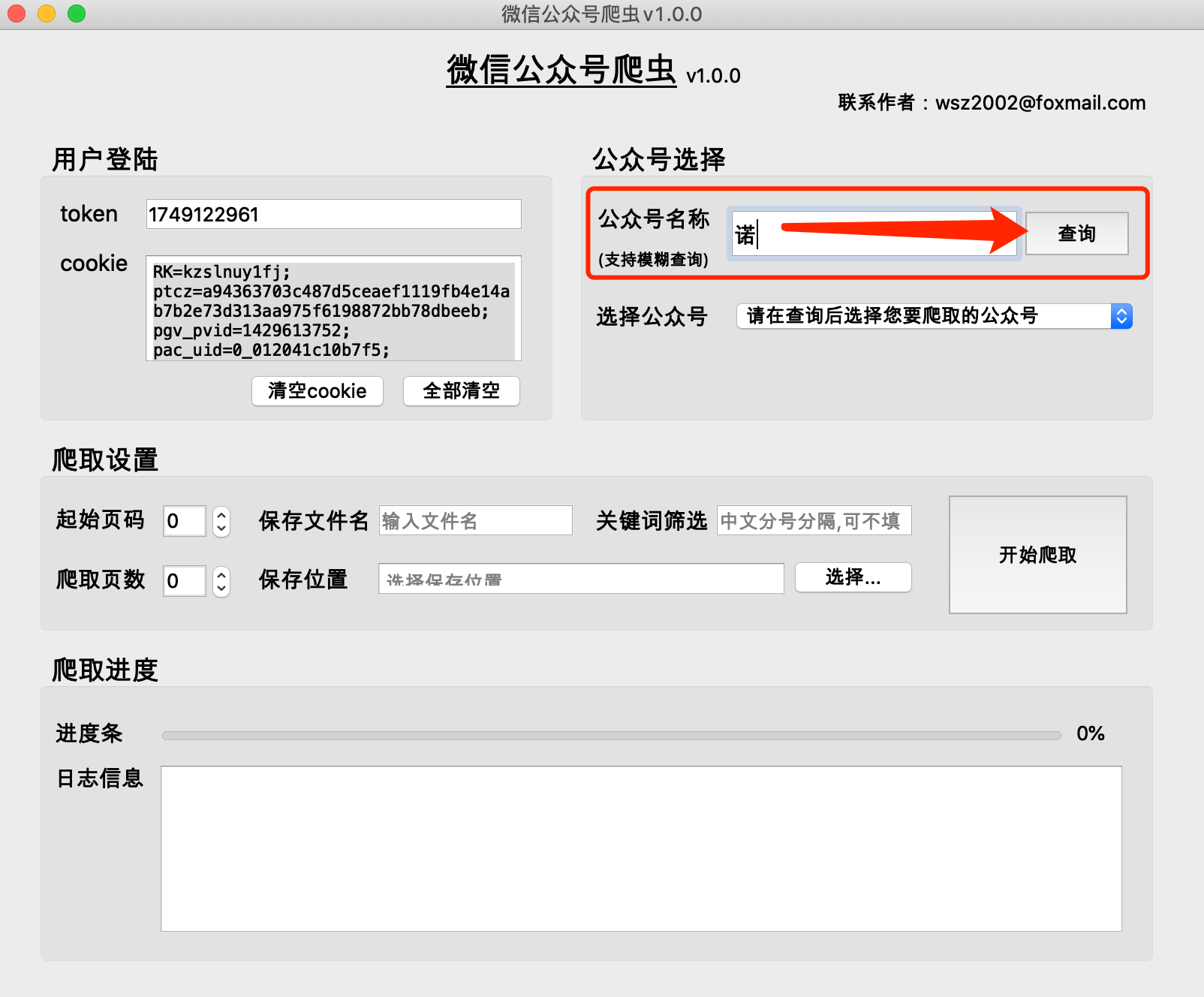
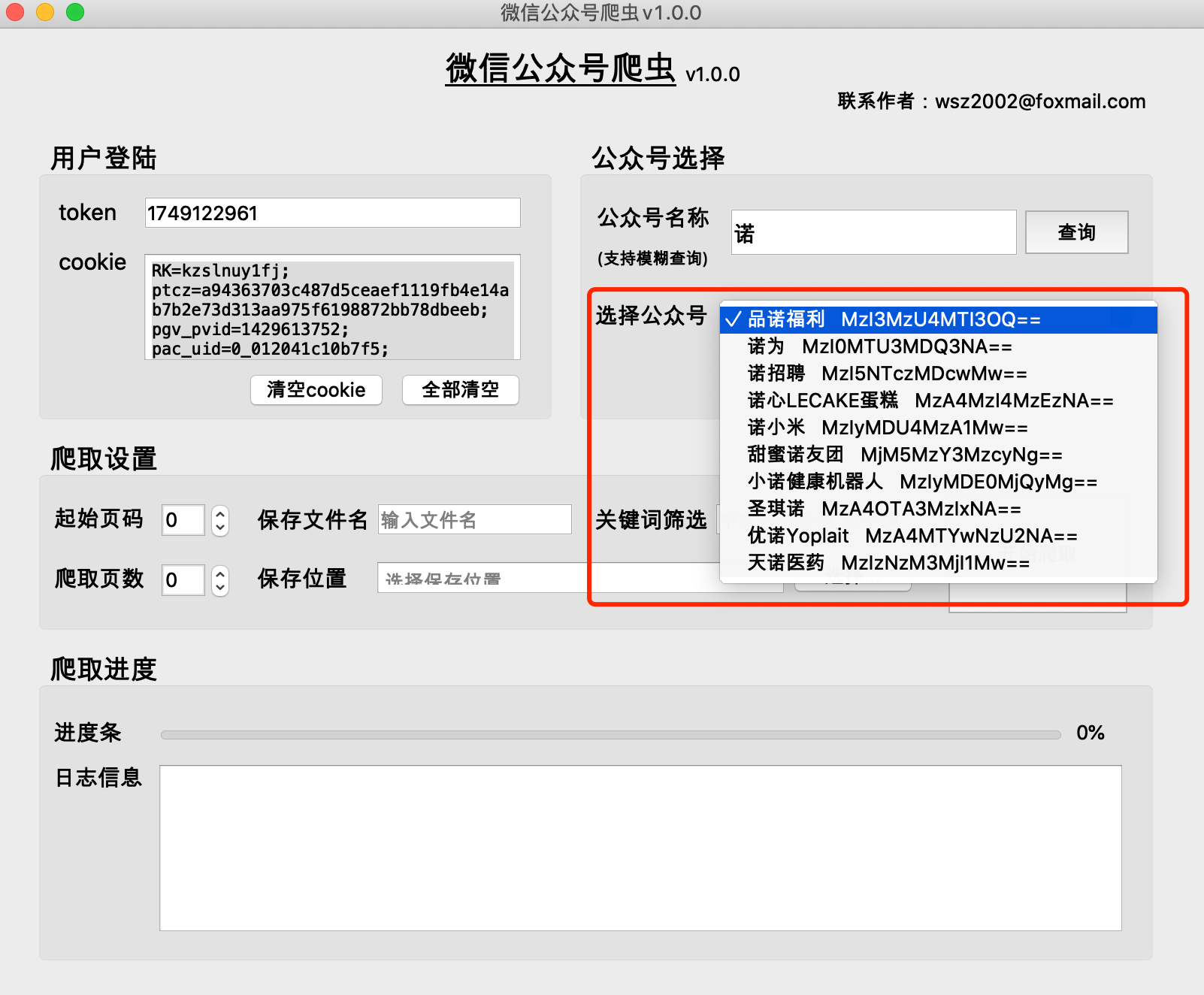
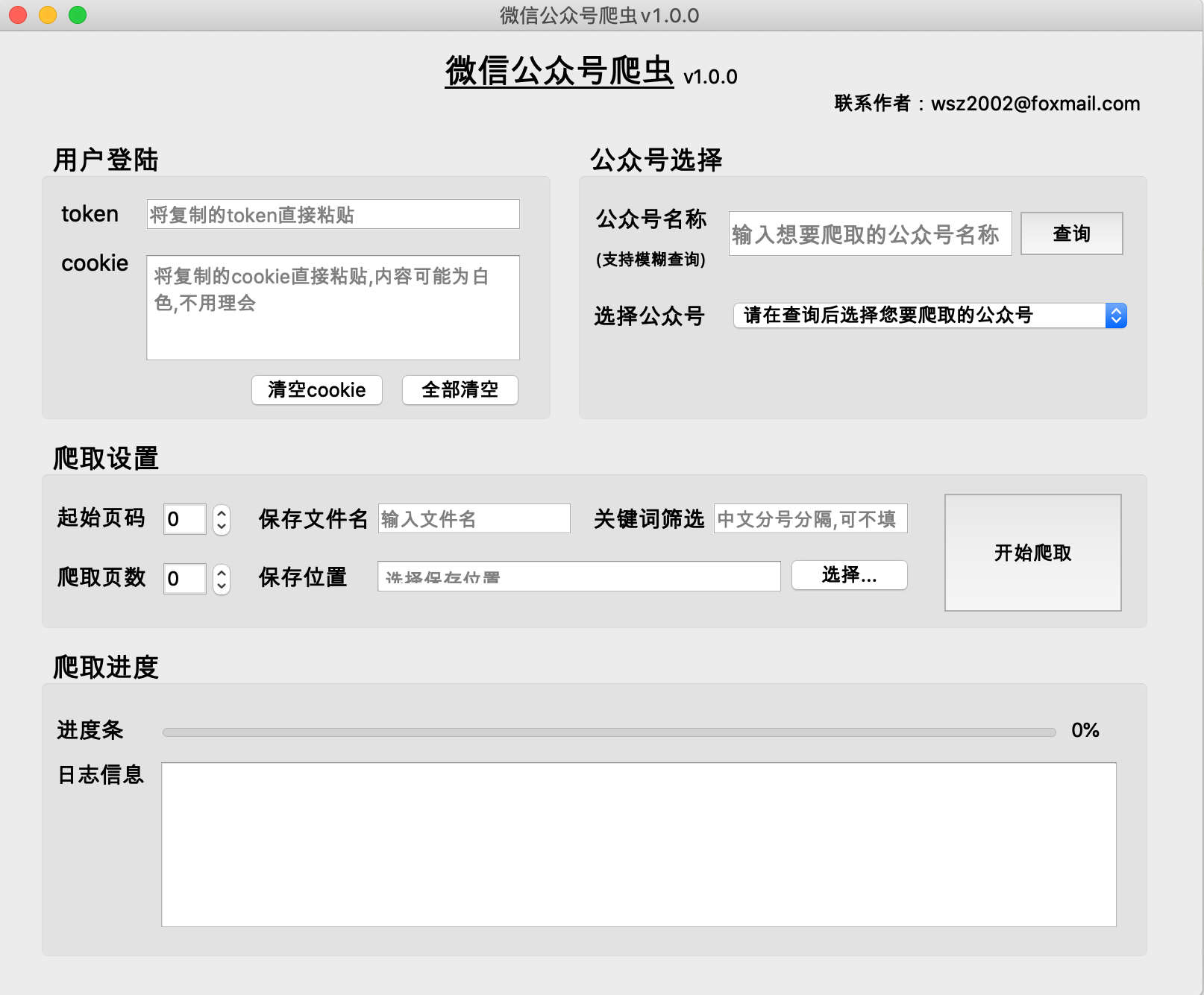
(1) The historical articles of public accounts are obtained in pages. Generally, there are 5-10 articles on one page.
(2) The smaller the page number of the public account’s historical articles, the more recent the time. Page 0 stores the latest articles.
(3) It is recommended that the starting page number starts from 0
(4) The number of crawled pages cannot be 0, otherwise the crawling results will be empty
Enter the correct file name and select the file location.
(1) Function: Used to filter articles based on keywords and obtain articles containing keywords in the article title. If not filled in, all articles will be retrieved.
(2) Format:关键词1;关键词2;关键词3
Separate with [Chinese semicolon], no semicolon after the last keyword
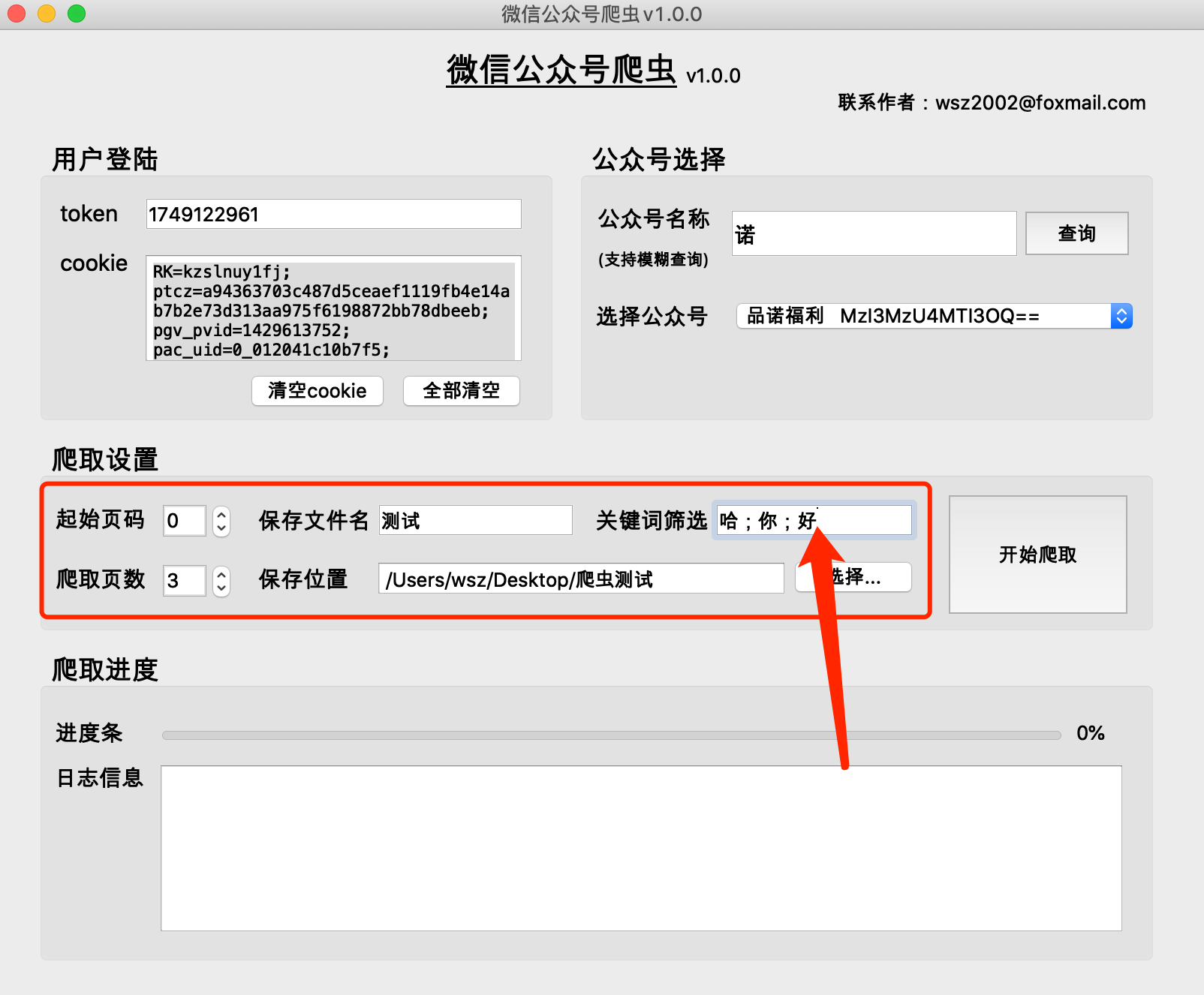
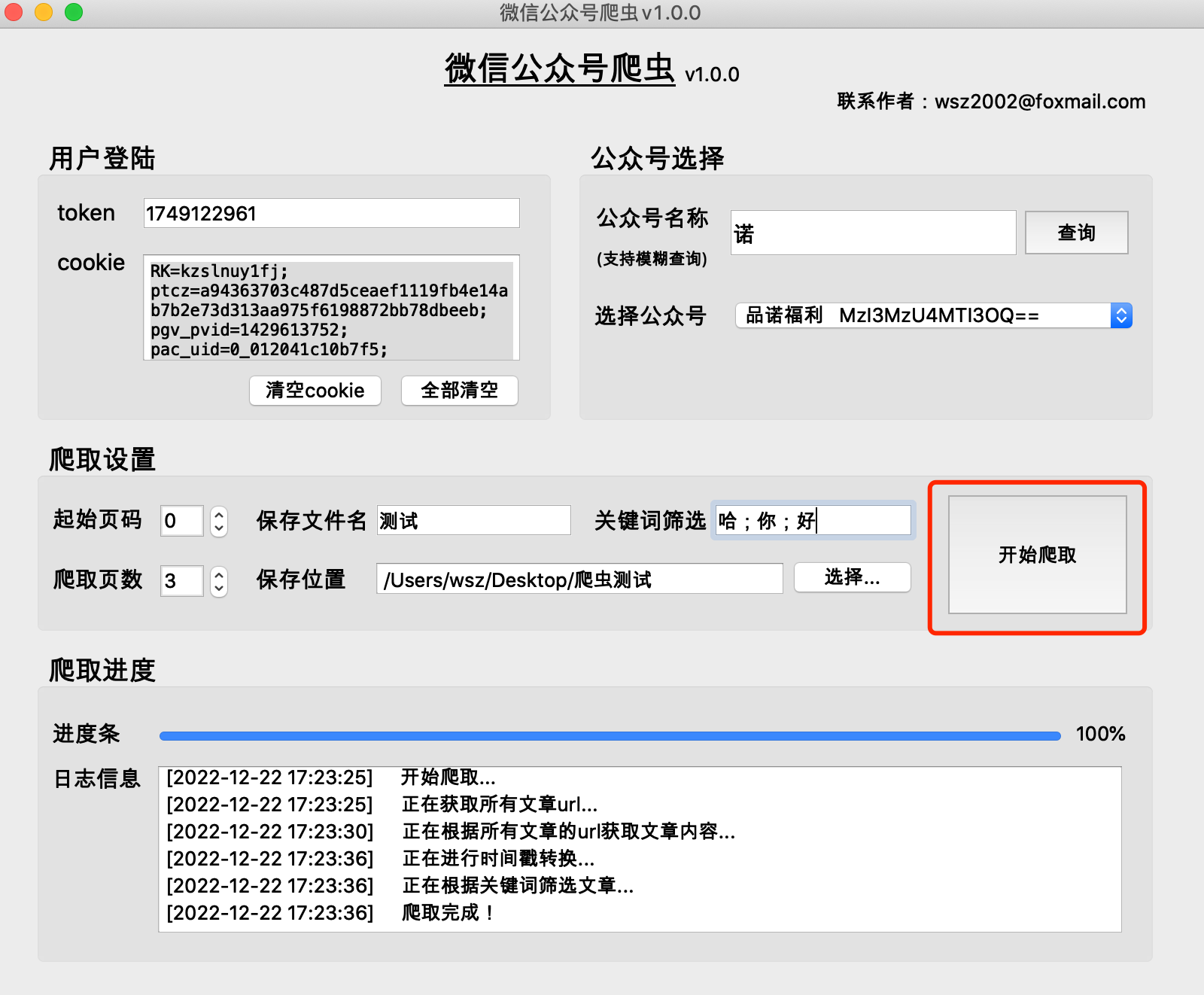
(1) The program will generate a folder with保存文件名_当日日期in the selected file storage location directory, and save the crawled content in this folder
(2) The contents of the raw folder are cache files generated during the crawling process and can be deleted.