wechat feeds
1.0.0
Generate RSS feed for WeChat public account
List page https://wechat.privacyhide.com/
As we all know, WeChat public accounts are relatively closed, and there is a certain threshold for crawling, which is very unfriendly to heavy RSS users. In addition, the push of subscription accounts is also in an out-of-order timeline. As a company struggling under the heavy pressure of recommendation algorithms, Member, I hope to use Github to provide limited subscription services for fellow enthusiasts.
The public accounts included are all submitted by netizens or collected from public lists, and do not represent any position; all contents are manually transcribed, and no reverse engineering has been performed.
The feeds are hosted on github, so I can't get any information about users who subscribe to these feeds
2020/10/5: GA has been added to the list page, just to count the usage of the list page. If you mind, you can use a browser plug-in to block it or use list.csv to manually search for splicing links to replace the list page.
2021/03/07: The implementation of #895 icon will request a server. The code is shown in favicon, which is capable of obtaining the IP address of the subscriber. I promise that I do not record the data, but I feel that even if I am trusted, this is just The method based on trust in individuals is unhealthy and has privacy risks . If you have any good ideas, please issue and communicate with me.
If you need a real-time notification, you can click Subscribe on the corresponding page.
This guide is only for friends who are not very familiar with github. It is convenient for everyone to submit PR directly on the web page. Veterans can ignore it~
First you need to have a github account: Register | Login
Open list.csv in the browser, first search to see if there is the official account you need, and if it is not found, click the edit button indicated by the arrow to start editing.
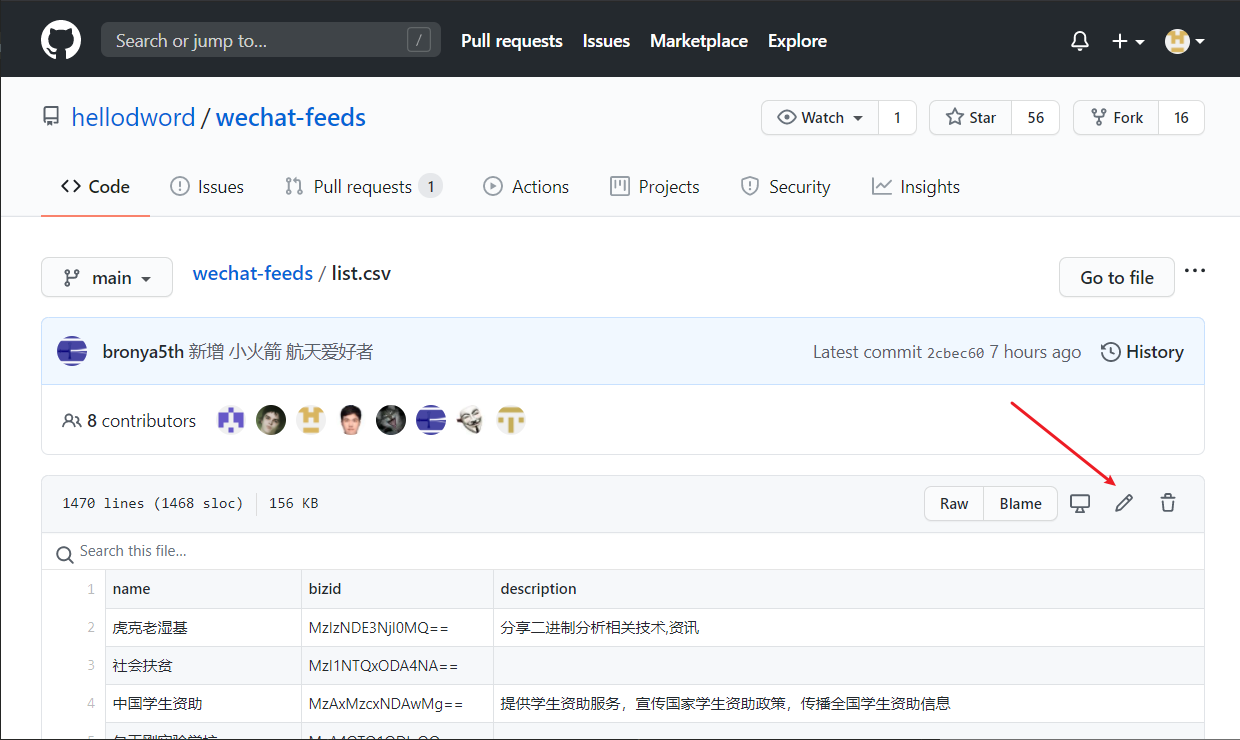
Propose changes (arrow 3). Note that arrow 2 is filled in according to the following format:新增: note that the colon is a half-width character ; Separate the public accounts, and there is no space at the end. Note that there is also a space after新增: :新增: 火绒安全实验室Security Laboratory,新增: 火绒安全实验室人民日报; Separate, no spaces at the end, for example新增: 火绒安全实验室人民日报等,新增: 36个游戏资讯公众号. 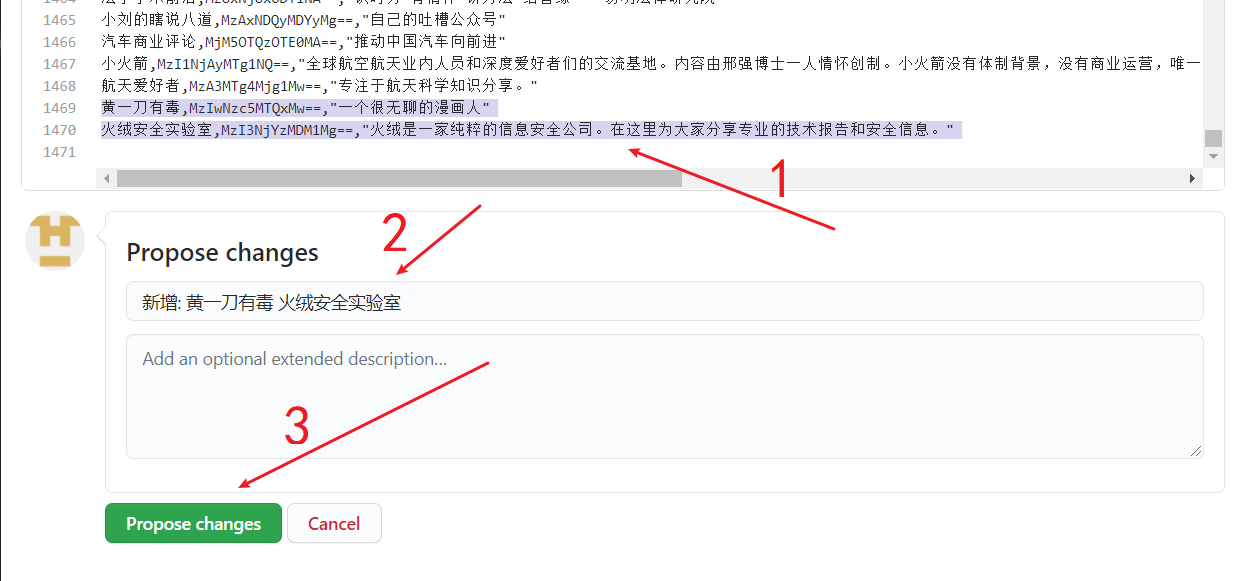
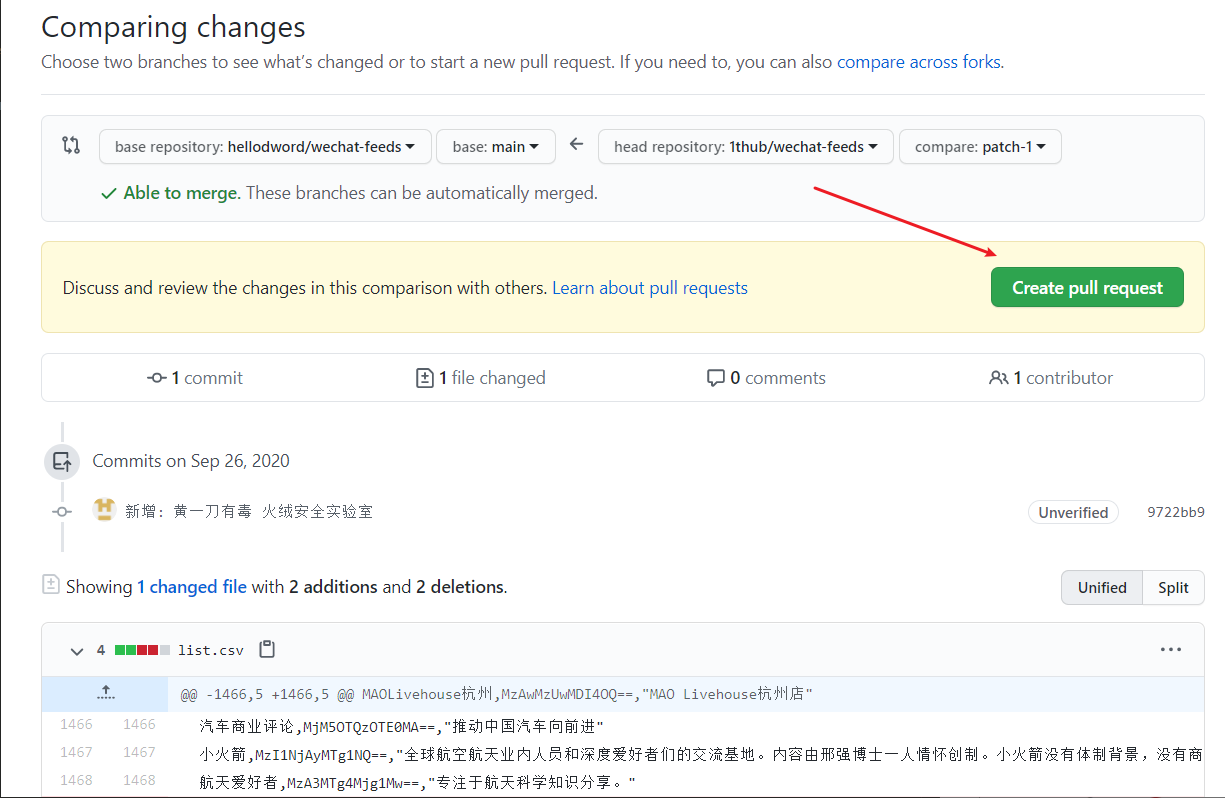
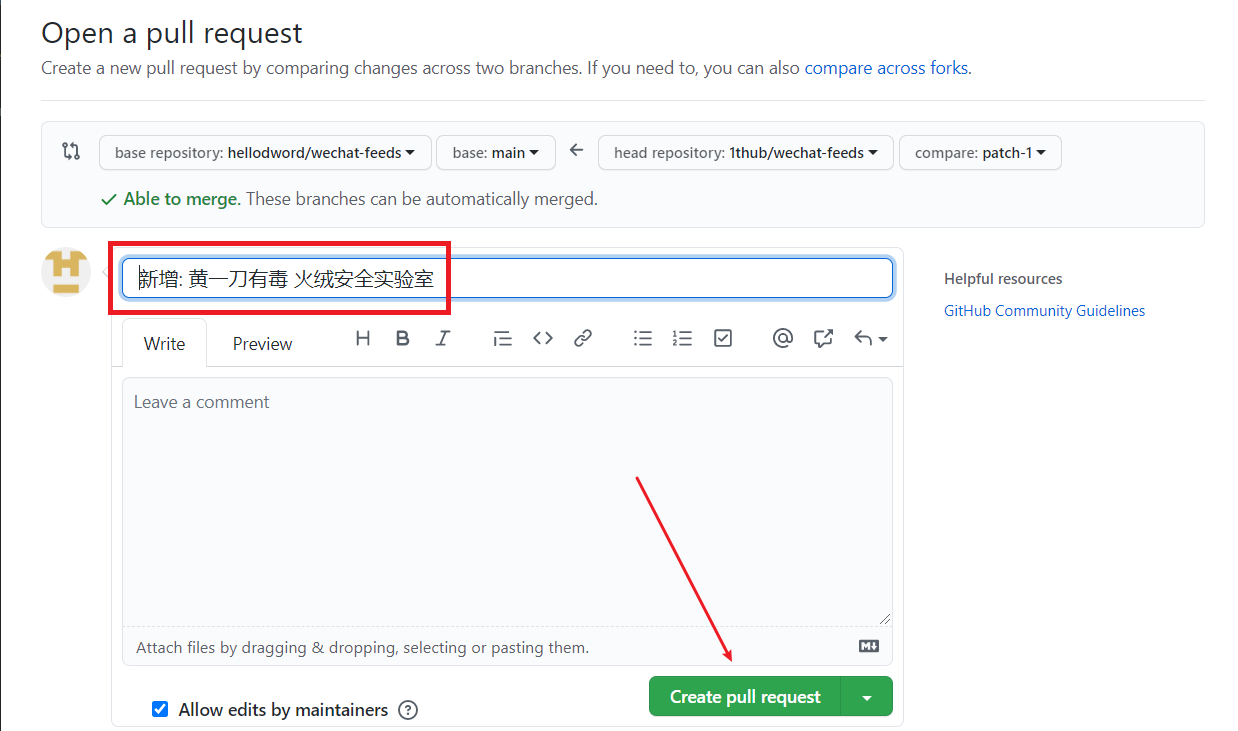
bizid , see how to get bizidname and bizid are required, description can be left blank. If there are half-width double quotes, line breaks, or commas in description , they need to be escaped. See csv escaping method. 

var biz , you can find var biz = ""||"MzI1NTQxODA4NA=="; then MzI1NTQxODA4NA== is the required bizidI can’t guarantee it at all, sorry (the particularity of the project means that anyone who says it’s absolutely stable is overconfident)
Approximate time point:
07,11,13,16,20,23
If you have a better timing design, please let me know, because there are very few updates pushed during the early morning hours, and crawling is a bit wasteful.
Due to account restrictions, we only plan to provide services for 20,000 public accounts for the time being, and only retain a maximum of 20 articles for each feed.
Truth: I transcribed everything manually and regularly, one by one. I can transcribe the contents of up to 20,000 public accounts in one hour.
First make sure your input method switches to half-width symbol state
If there are half-width double quotes in the content, you need to add another half -width double quote before each half-width double quote to escape, and then wrap the content with a pair of half-width double quotes:
Assume that the content that needs to be escaped is:
它说:"你好"
then change to:
"它说:""你好"""
If there are half-width commas in the content, wrap the content in a pair of half-width double quotes:
Assume that the content that needs to be escaped is:
你好,世界
then change to:
"你好,世界"
If there are line breaks in the content, wrap the entire content in a pair of half-width double quotes:
It is not recommended to include line breaks
Assume that the content that needs to be escaped is:
它说:"你好世界"
它说:"知道了"
then change to:
"它说:""你好世界""
它说:""知道了"""
See issue 390
I took a look at this official account, and its push time is 8:30 am every day, so I guess it is published at a scheduled time, and the time displayed in the feeds is the time when the WeChat server received this article.
For example, in this article, the 1607733000 corresponding to 8:30 can be seen in its web page source code, so in fact, this may be the same category of problem as crawling the full text.
The publicly available parts can be found in the source code of each branch. Those with programming skills can reverse it and build their own icon servers to eliminate privacy risks and MIME issues. Apart from this, there are currently no open source plans. Besides, I copied it manually.
I have checked the ToS for a long time. I think it does not count for this project. You are welcome to discuss this with me.
First recommended issues
If you have any questions or suggestions that require frequent communication, you can communicate here. Of course, it is recommended to read this document before doing so.


