glory admin
1.0.0
GloryAdmin is a background framework based on springboot2.1.9.RELEASE and vue-admin-template;
GloryAdmin uses role-based permission management. The role tree is a tree with "System Administrator" as the root node, and the permission tree is composed of multiple sub-permission trees. "System administrator" has all permissions; non-system administrator roles can view the information of the current role and the directly subordinate roles, but can only add, delete and modify the information of the directly subordinate roles (direct subordinates: A is the direct subordinate of B, then A must is the child node of B).
Glory-Admin
| project | technology |
|---|---|
| Backend project | springboot |
| Front-end project | Element UI & Vue.js |
| database | MySQL |
| cache | Redis |

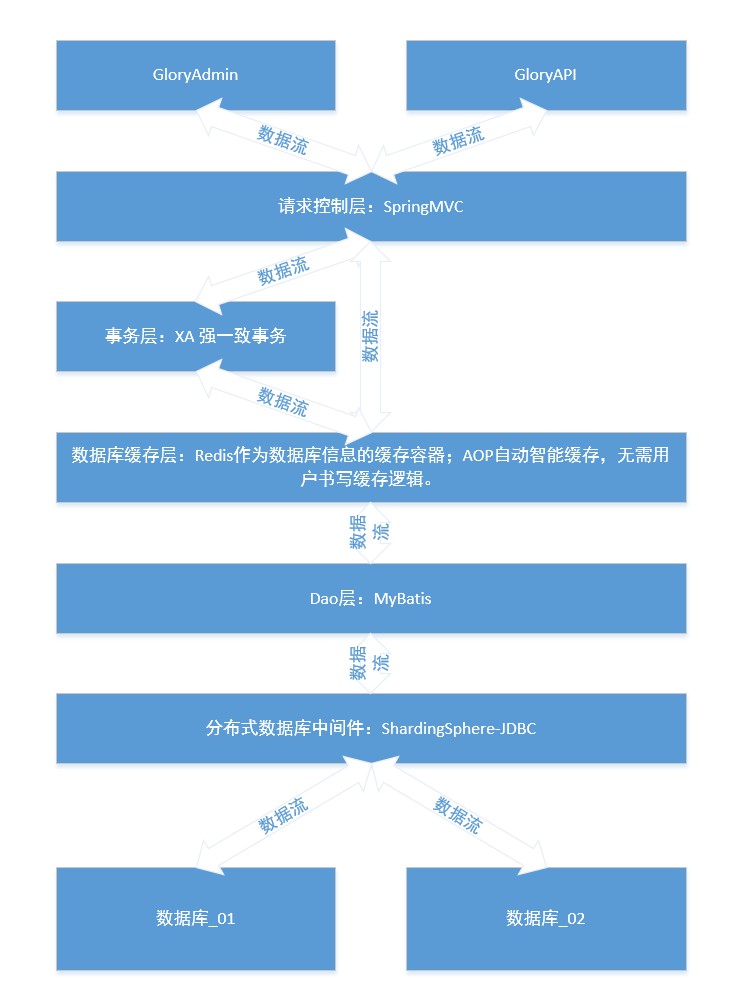
This project uses mysql database, you can use the database script to create 2 databases multi_module_db multi_module_db_01
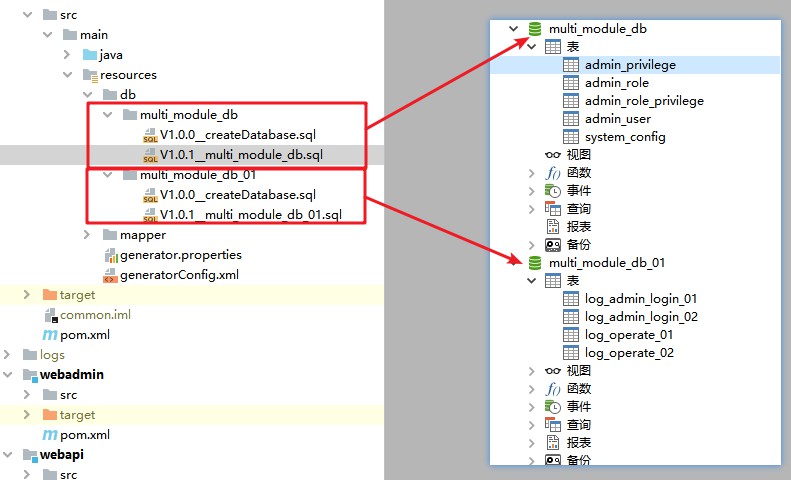
Start in the background and use port 28081
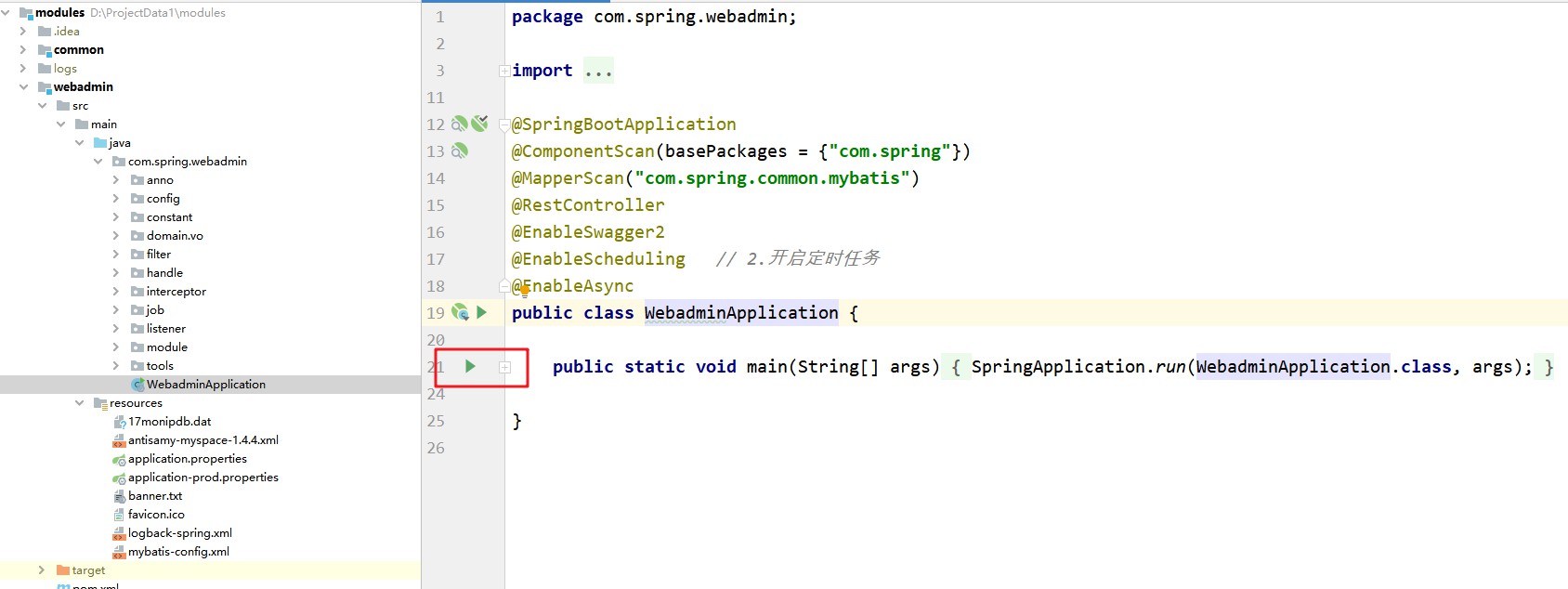
Start the front end and use port 9523
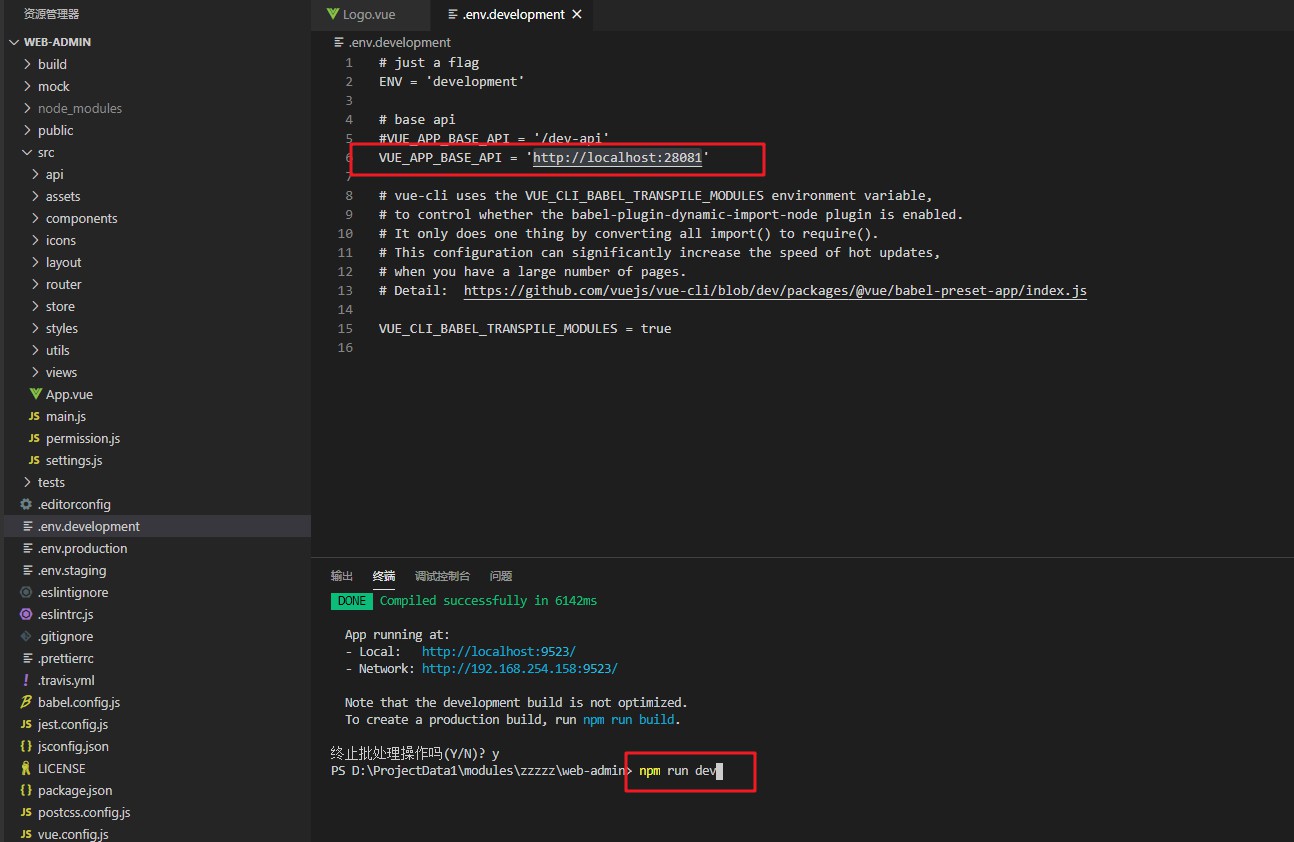
Open the browser and visit http://localhost:9523 admin a123456
The essence of sharding or sharding is the failure of Moore's Law. The solution of centrally storing data on a single data node has been difficult to meet the massive data scenarios of the Internet in terms of performance, availability, and operation and maintenance costs.
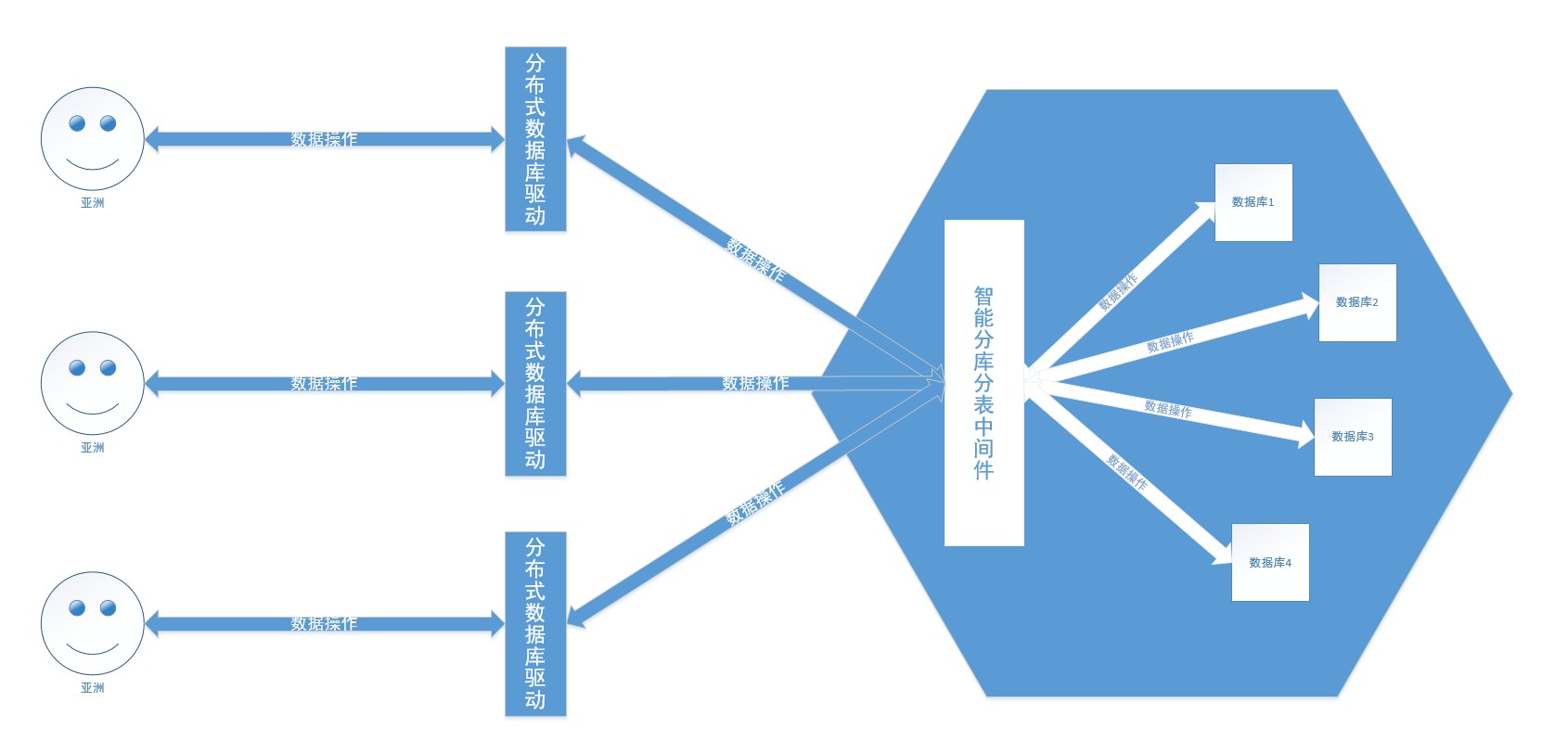
A single database cannot support existing businesses, so sub-databases and tables have emerged, and multiple databases are used for data storage. The simple understanding of sub-database and sub-table is that the contents of a basket are limited, which affects the search efficiency and capacity. The contents of the basket are divided into N parts and placed in different baskets. This breaks capacity constraints and improves query efficiency.
Then let’s talk about distributed databases. The more popular ones in China include Tencent’s TDSQL, Alibaba’s OceanBase, PolarDB, Huawei’s GaussDB, etc. Basically, they are independently developed, with strong consistency and high availability, global deployment architecture, distributed unlimited horizontal expansion, high performance, hundreds of billions of records, and cross-row and cross-table transactions on hundreds of TB of data (like for the motherland) . The distributed database hides the strategy of database sharding and table sharding, intelligently shards data into databases and tables, and uses it just like operating a database.
Since memory operations and disk operations are not of the same order of magnitude at all, large projects require a memory-type buffer layer for disk-type databases to cache disk data into memory. The data caching layer is used to cache the data of the entire data layer to speed up site access. This project uses AOP technology and Redis in-memory database as the data cache layer. Please check the code com/spring/common/aop/CacheDaoAspect.java for details.
This project uses sharding JDBC to process the database and tables of the database. Split the data yourself according to business scenarios.
Usually projects only have one database, and Alibaba Cloud's druid is used more frequently in China as the database connection pool. This project uses mysql, druid, and sharding JDBC. The principle of data sharding is to maintain multiple database connection pools in the program, and each database connection pool corresponds to a database. The sharded database and sharded tables use two-phase transaction processing based on the XA protocol . Configuration path com.spring.common.config.shardingJDBC
Vertical splitting: The method of business splitting is called vertical sharding, also known as vertical splitting. Distribute tables to different databases according to business, thereby distributing pressure to different databases.
Horizontal split: It does not care about business logic classification, but disperses data into multiple libraries or tables according to certain rules through a certain field (or several fields) of a certain table. The rules here and the algorithm involved are called sharding algorithms .
( The following content is taken from the shardingJDBC documentation )
Corresponds to PreciseShardingAlgorithm, used to handle the scenario of = and IN sharding using a single key as the sharding key. Need to be used with StandardShardingStrategy.
Corresponds to the RangeShardingAlgorithm, which is used to handle sharding scenarios using BETWEEN AND , > , < , >= , and <= using a single key as the sharding key. Need to be used with StandardShardingStrategy.
Corresponds to the ComplexKeysShardingAlgorithm, which is used to handle scenarios where multiple keys are used as sharding keys for sharding. The logic containing multiple sharding keys is complex, and application developers need to handle the complexity themselves. Need to be used with ComplexShardingStrategy.
Corresponds to HintShardingAlgorithm, used to handle scenarios where Hint row sharding is used. Need to be used with HintShardingStrategy.
The user logs in to obtain the token and store it locally (adminLogin)
The user sends a token to obtain user information and permission information, and stores them in the store. Since F5 will cause the store to be lost, an interceptor is added to the front-end request. If there is no user information and permission information, user information and permissions will be re-obtained (getAdminInfo)
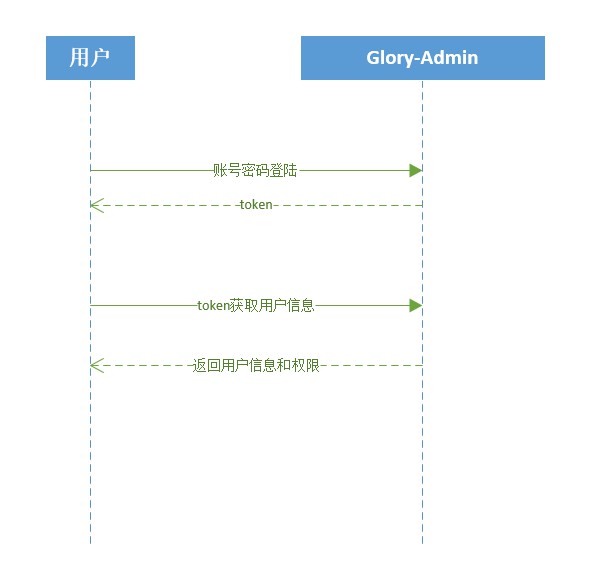
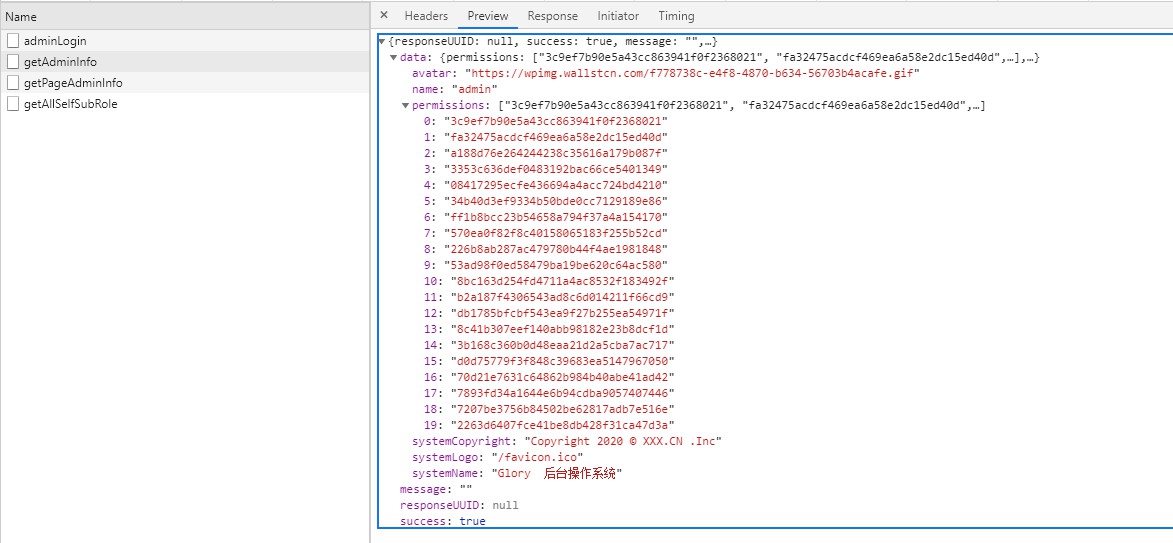
What is returned here is all the permissions of the user instead of the role. The user dynamically generates front-end routes.
asyncRoutes is a dynamically generated permission. If the user's permission corresponds to the route's permission, it will be displayed;
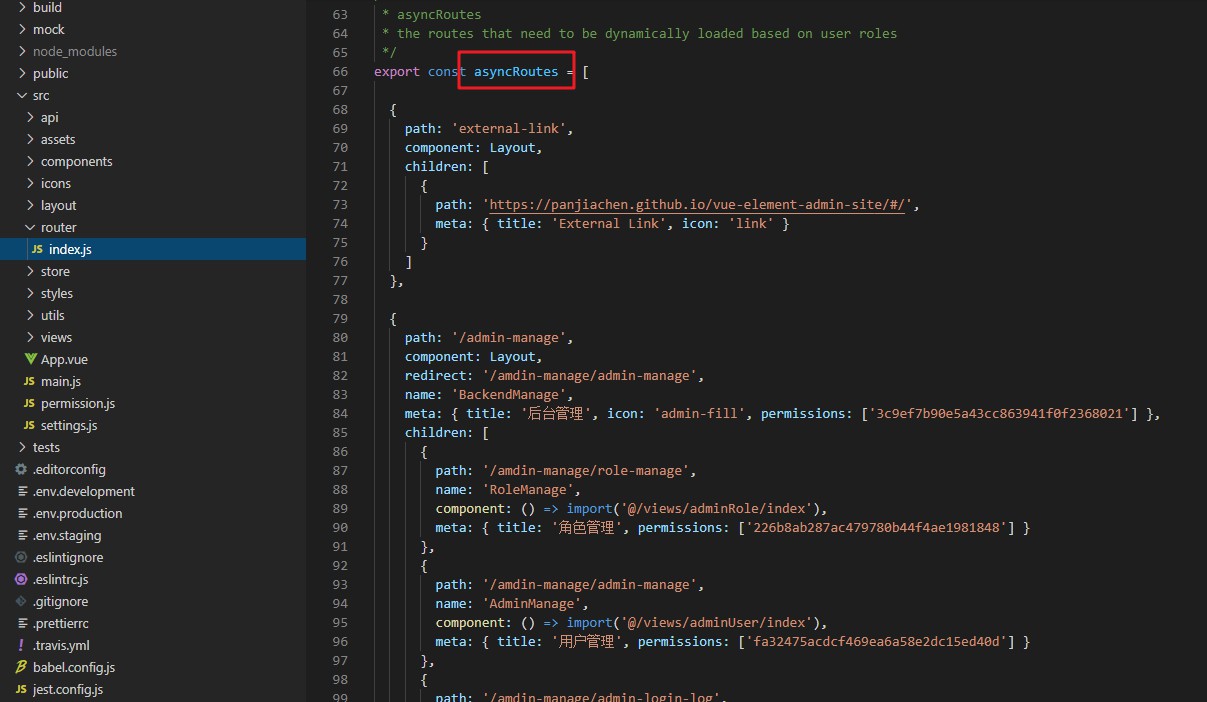
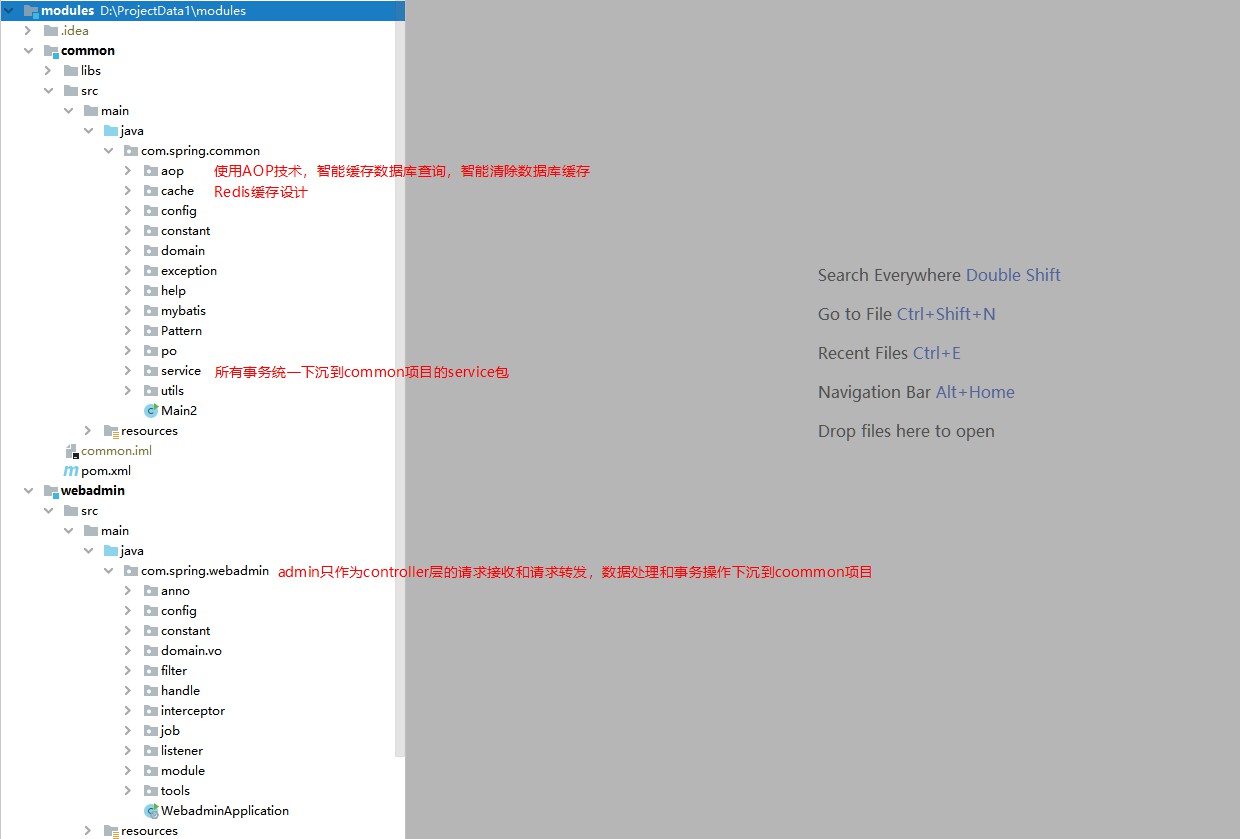
common: data operations, data caching, transaction operations
The admin only serves as the controller, which is used to handle forwarding between user requests and back-end business. (Why is it designed like this?) Because some middleware systems need to use the RPC framework for request forwarding, and because some confidential systems disdain to use springMVC and choose vertx to independently develop the request layer.
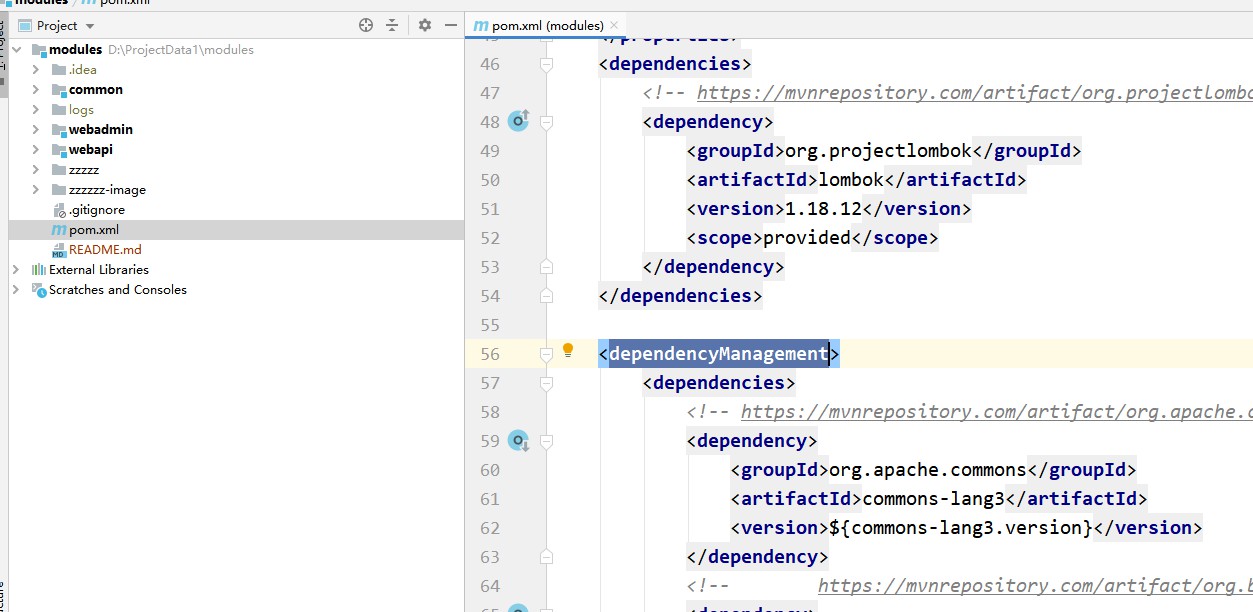
Use Maven inheritance to manage project dependencies. In Modules, dependencies are introduced through dependencyManagement and the versions are specified. Subprojects inherit Modules and there is no need to specify versions when introducing dependencies.
Global log processing
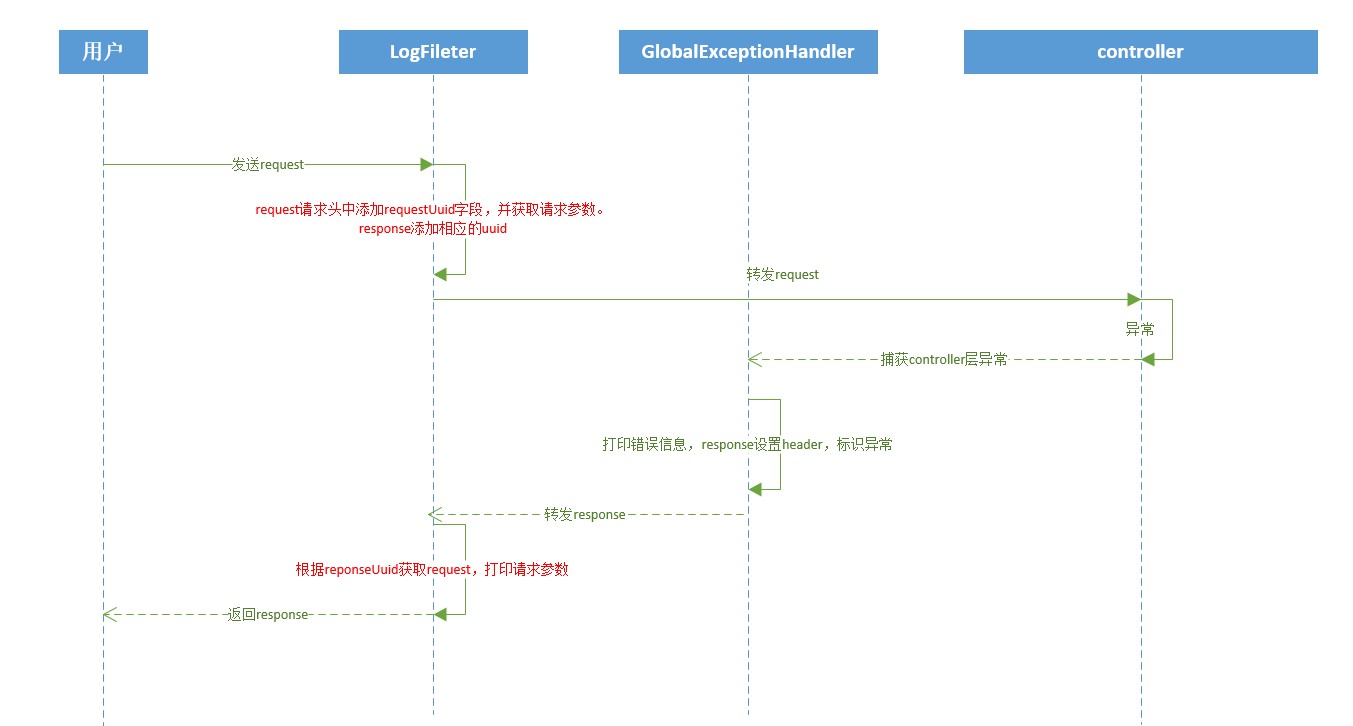
User operation logs use annotation methods. If this method needs to record operation logs, just add the **@OperateLog** annotation above the method name.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

