Since the appearance of Large Language Model (LLM) represented by ChatGPT, due to its amazing ability of universal artificial intelligence (AGI), it has set off a wave of research and application in the field of natural language processing. Especially after the small -scale LLM open source that can run up with Chatglm, LLAMA and other civilian players can run, there are many cases of LLM -based minimally adjusted or applications based on LLM. This project aims to collect and sort out open source models, applications, data sets and tutorials related to Chinese LLM. The currently included resources have reached 100+!
If this project can bring you a little help, please let me a little bit ~
At the same time, you are also welcome to contribute to the unpopular open source models, applications, data sets, etc. of this project. Provide new warehouse information, please initiate PR, and provide related information such as warehouse links, numbers of stars, profiles, briefing and other related information according to the format of this project. Thank you ~
Common base model details overview:
Base
Include a model
Model parameter size
Trail token number
Maximum training
Whether to commercialize
Chatglm
Chatglm/2/3/4 Base & Chat
6B
1T/1.4
2K/32K
Commercial use
Llama
Llama/2/3 Base & Chat
7b/8B/13B/33B/70B
1T/2T
2K/4K
Partially commercialized
Baichuan
Baichuan/2 Base & Chat
7B/13B
1.2T/1.4T
4K
Commercial use
Qwen
Qwen/1.5/2/2.5 Base & Chat & VL
7B/14B/32B/72B/110B
2.2T/3T/18T
8K/32K
Commercial use
Bloom
Bloom
1B/7B/176B-MT
1.5T
2K
Commercial use
Aquila
Aquila/2 base/chat
7B/34B
-
2K
Commercial use
Internet
Internet
7B/20B
-
200K
Commercial use
Mixtrac
Base & Chat
8X7B
-
32K
Commercial use
Yi
Base & Chat
6b/9b/34b
3T
200K
Commercial use
Deepseek
Base & Chat
1.3B/7B/33B/67B
-
4K
Commercial use
Xverse
Base & Chat
7B/13B/65B/A4.2B
2.6T/3.2T
8K/16K/256K
Commercial use
Table of contents
Table of contents
1. Model
1.1 Text LLM model
1.2 Multifamily LLM model
2. Application
2.1 Filtering in the vertical field
Medical care
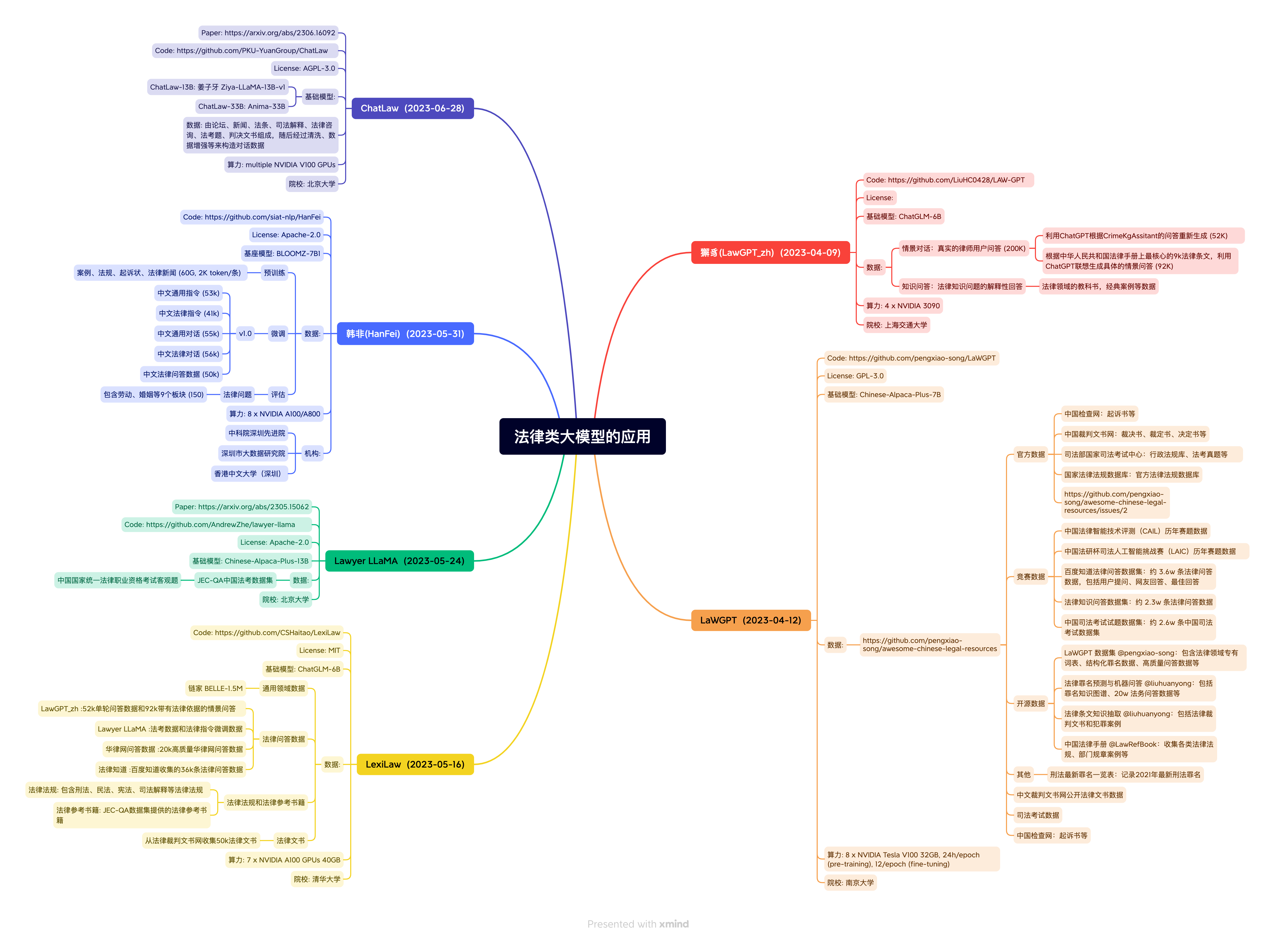
law
finance
educate
science and technology
E -commerce
Network security
agriculture
2.2 Langchain application
2.3 Other applications
3. Data set
Pre -training data set
SFT data set
Preference data set
4. LLM training fine -tuning framework
5. LLM reasoning deployment framework
6. LLM evaluation
7. LLM tutorial
LLM basic knowledge
Prompting engineering tutorial
LLM application tutorial
LLM actual combat tutorial
8. Related warehouse
Star History
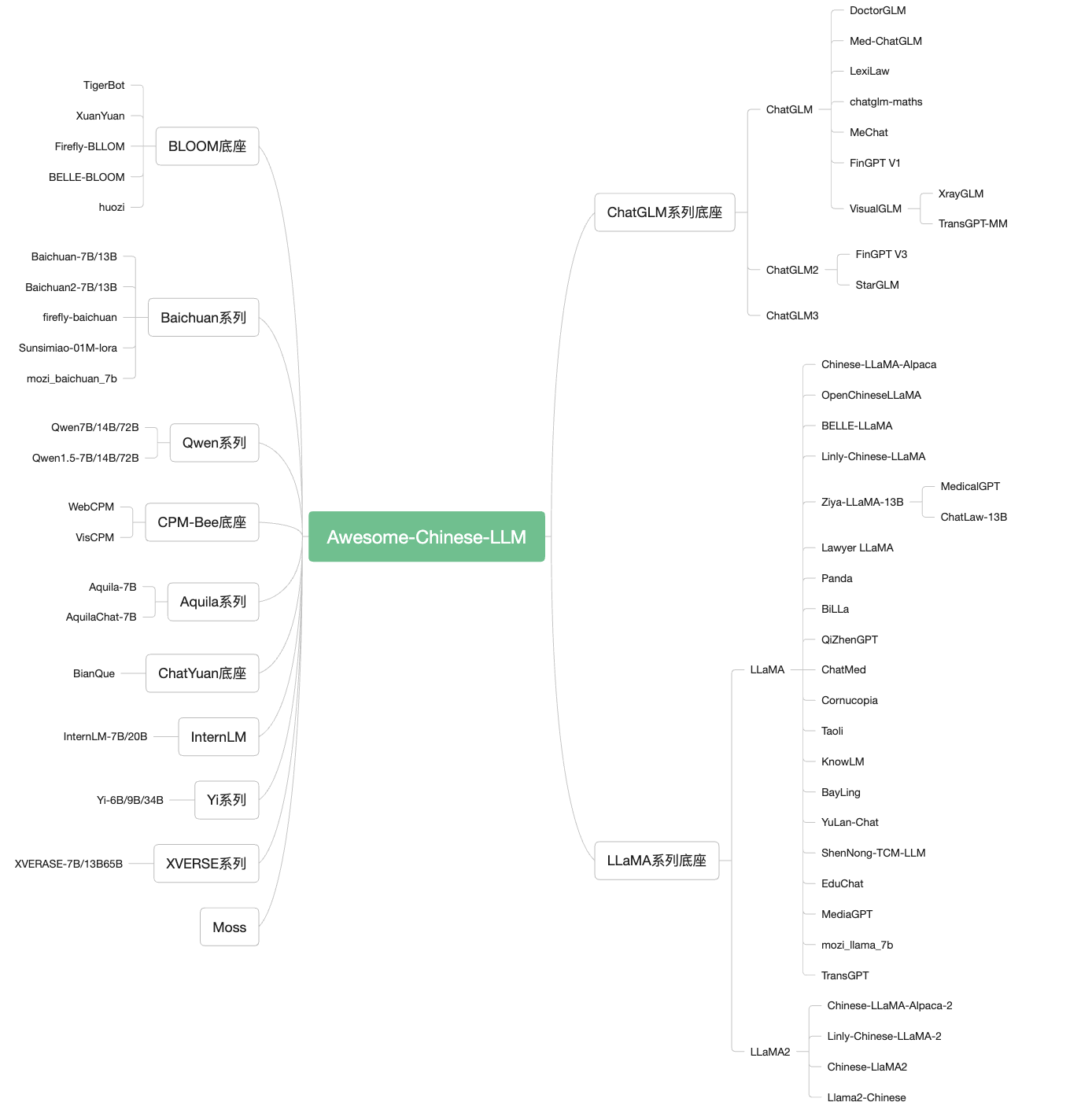
1. Model
1.1 Text LLM model
Chatglm:
Address: https://github.com/thudm/chatglm-6b
Introduction: One of the most effective open source base models in the Chinese field, optimized the Chinese Q & A and dialogue. After a bilingual training of about 1T identifier, supplemented by technologies such as supervising fine -tuning, feedback, and feedback from human feedback to strengthen learning
Chatglm2-6b
Address: https://github.com/thudm/chatglm2-6b
Introduction: Based on the second-generation version of the open source Chinese and English dialogue model Chatglm-6B, it has introduced the GLM's hybrid target function on the basis of the preserved model dialogue and low deployment thresholds, which have been retained. The pre-training of the British identification symbols in the T and the alignment of human preferences; the context length of the base model model has expanded to 32K, and the context length training of 8K context length is used during the dialogue stage; Vedication occupation; allowing commercial use.
Chatglm3-6b
Address: https://github.com/thudm/Chatglm3
Introduction: Chatglm3-6B is the open source model in the Chatglm3 series. On the basis of retaining many excellent characteristics such as the previous two generations of model dialogue and low deployment threshold, Chatglm3-6B introduces the following features: a more powerful basic model: Chatglm3- 6B's basic model Chatglm3-6B-Base uses more training data, more full training steps, and more reasonable training strategies; more complete functional support: Chatglm3-6b uses a newly designed Prompt format, except for normal Multiple rounds of dialogue.同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和Agent 任务等复杂场景;更全面的开源序列: 除了对话模型ChatGLM3-6B 外,还开源了基础模型ChatGLM3-6B-Base、长文本Dialogue model Chatglm3-6B-32K. The above weight is completely open to academic research, and free commercial use is also allowed after filling in the questionnaire.
GLM-4
Address: https://github.com/thudm/glm-4
Brief introduction: GLM-4-9B is the open source version of the latest generation pre-training model launched by the Smart Spectrum AI. In the assessment of data sets such as semantics, mathematics, reasoning, code, and knowledge, the GLM-4-9B and its human preference version of GLM-4-9B-CHAT all shows excellent performance beyond Llama-3-8B Essence In addition to multiple rounds of dialogue, GLM-4-9B-Chat also has advanced functions such as web browsing, code execution, custom tool calling (Function Call) and long text reasoning (support for maximum 128K context). This generation has added multi -language support, supporting 26 languages including Japanese, Korean, and German. We also launched GLM-4-9B-Chat-1M models that support 1M contextual length (about 2 million Chinese characters) and multi-mode model GLM-4V-9B based on GLM-4-9B. GLM-4V-9B has a multilingual multilingual multilingual dialogue ability under the high resolution of 1120 * 1120. In many aspects of multi-modal evaluation such as comprehensive Chinese and English comprehensive ability, perception reasoning, text recognition, chart understanding, GLM-4V-9B Express the excellent performance of surpassing GPT-4-Turbo-2024-04-09, Gemini 1.0 Pro, Qwen-Vl-Max, and Claude 3 Opus.
Qwen/qwen1.5/qwen2/qwen2.5
Address: https://github.com/qwenlm
Introduction: Tongyi Qianwen is a series of models of Tongyi Qianwen's model developed by Alibaba Cloud, including the parameter scale of 1.8 billion (1.8B), 7 billion (7B), 14 billion (14B), 72 billion (72B), 1100 and 1100 100 million (110B). The models of each scale include the basic model Qwen and the dialog model. Data sets include a variety of data types such as text and code. It covers the general field and professional fields. It can support the context length of 8 ~ 32K. Specific optimization of alignment data related to plug -in calls. The current model can effectively call the plug -in and upgrade to the agent Essence
Introduction: Shangtang Technology, Shanghai AI Laboratory and the Chinese University of Hong Kong, Fudan University, and Shanghai Jiaotong University released the 100 billion -level parameter large language model "Scholarship". It is reported that "scholar Pu" has 104 billion parameters, and is trained based on "multi -language high -quality data set containing 1.6 trillion token".
Internet
Address: https://github.com/internlm/internlm
Introduction: Shangtang Technology, Shanghai AI Laboratory and the Chinese University of Hong Kong, Fudan University, and Shanghai Jiaotong University released the 100 billion -level parameter large language model "Internlm2". Internlm2 has made great progress in digital, code, dialogue, and creation, and the comprehensive performance has reached the leading level of open source model. Internlm2 contains two models: 7B and 20B. 7B provides a lightweight but unique model for the research and application of lightweight. The comprehensive performance of the 20B model is more powerful, and it can effectively support more complex and practical scenarios.
Introduction: A large -scale pre -training language model developed by Baichuan Intelligent Development. Based on the Transformer structure, the 7 billion parameter model trained on about 1.2 trillion tokens supports Chinese and English bilingual, and the length of the context window is 4096. Both the standard Chinese and English authority Benchmark (C-Eval/MMLU) have the best effect of the same size.
Introduction: Baichuan-13B is a large-scale language model containing 13 billion parameters after Baichuan-7b after Baichuan-7B. It has achieved the best effects of the same size in the authoritative Chinese and English Benchmark. The project publishes two versions: Baichuan-13B-BASE and Baichuan-13B-CHAT.
Introduction: The new generation of open source large language model launched by Baichuan Intelligence uses 2.6 trillion tokens to train with high -quality corpus. Published Base with 7B, 13B and the Chat trained version of PPO, and provided the Chat version of the 4bits quantification.
Xverse-7b
Address: https://github.com/xverse- ai/xverse-7b
Introduction: The large language model supported by Shenzhen Yuanxiang Technology supports multi -language models, supports 8K context length, and uses a high -quality and diversified data of 2.6 trillion token to train the model. More than 40 languages such as Britain, Russia, and Western. It also includes models of GGUF and GPTQ quantitative versions, which supports reasoning on LLAMA.CPP and VLLM on the Macos/Linux/Windows system.
Xverse-13b
Address: https://github.com/xverse- ai/xverse-13b
Introduction: Large language models supported by Shenzhen Yuanxiang Technology supporting multi -language models, supporting 8K context length (Context Length), and using high -quality and diversified data of 3.2 trillion token to fully train the model. More than 40 languages such as Britain, Russia, and Western. Including the long sequence dialog model XVERSE-13B-256K. The model of this version supports the context window length with a maximum of 256K, and the input content of about 25W words can help the literature summary, report analysis and other tasks. It also includes models of GGUF and GPTQ quantitative versions, which supports reasoning on LLAMA.CPP and VLLM on the Macos/Linux/Windows system.
XVerse-65B
Address: https://github.com/xverse- ai/xverse-65b
Introduction: A large language model supported by Shenzhen Yuanxiang Technology supports multi -language model, supports the context length of 16K, and uses a high -quality and diversified data of 2.6 trillion token to train the model to fully train the model. More than 40 languages such as Britain, Russia, and Western. Including an incremental pre-training XVERSE-65B-2 model with an incremental pre-training. It also includes models of GGUF and GPTQ quantitative versions, which supports reasoning on LLAMA.CPP and VLLM on the Macos/Linux/Windows system.
Introduction: Large Language Model, which supports multi-language independently developed by Shenzhen Yuanxiang Technology. The parameters are 4.2 billion, supporting the context length of 8K, and using the high -quality and diverse data of 3.2 trillion token to fully train the model to support more than 40 languages such as China, Britain, Russia, and Western.
Skywork
Address: https://github.com/skyworkai/skywork
Introduction: The project is open to the Tiangong series models. This series of models conduct pre -training on 3.2TB of high -quality multi -language and code data. Open source includes model parameters, training data, evaluation data, and evaluation methods. Specific SkyWork-13B-Base model, Skywork-13B-Chat model, Skywork-13B-Math model, Skywork-13B-MM model, and quantitative version models of each model to support users to deploy and reason at the consumer graphics card deployment and reasoning Essence
Yi
Address: https://github.com/01- ai/yi
Brief introduction: This project is open to models such as Yi-6B and Yi-34B. This series of models can support the ultra-long context window version of 200K, which can process about 400,000 Chinese character ultra-long text inputs to understand PDF documents with more than 1000 pages.
Introduction: Chinese LLAMA & Alpaca large language model+local CPU/GPU deployment. Based on the original LLAMA, the Chinese vocabulary was expanded and Chinese data was used for secondary pre -training training.
Introduction: The project is based on the commercial LLAMA-2 for second development. Training; follow-up of the training scale will be increased; chinese-llama2-Chat: Form-to-chine-llama2 is fine-tuned and summarized to fine-tune multiple rounds to adapt to various application scenarios and multi-round dialogue interactions. At the same time, we also consider a faster Chinese adaptation solution: Chinese-Llama2-SFT-V0: Use existing open source Chinese instructions fine-tuning or dialogue data to directly fine-tune LLAMA-2 (will be recently open source).
Introduction: The project focuses on the optimization of the LLAMA2 model in Chinese and upper -level construction. Based on large -scale Chinese data, the Chinese capabilities of the LLAMA2 model have continued to upgrade from pre -training.
Introduction: Based on LLAMA-7B, a large language model base generated by the pre-training of Chinese dataset incremental training, compared to the original LLAMA, this model has greatly improved in terms of Chinese understanding and generating ability. In many downstream tasks Highlights.
Belle:
Address: https://github.com/lianjiaatech/belle
Introduction: Open source for a series of models based on Bloomz and LLAMA optimization. At the same time, it includes training data, related models, training code, application scenarios, etc. It will also continue to evaluate the impact of different training data and training algorithms on model performance.
Introduction: Open source is based on LLAMA -7B, -13B, -33B, -65B for continuous pre -training language models in the Chinese field, and uses nearly 15M data for secondary pre -training.
Robin (Robin):
Address: https://github.com/optimalscale/lmflow
Brief introduction: Robin (Robin) is a Chinese -English bilingual model developed by the LMFlow team of the University of Science and Technology of China. Only the Robin second -generation model obtained by only 180K data data was fine -tuned, reaching the first place on the HuggingFace list. LMFlow supports users to quickly train personalized models. It only takes a single 3090 and 5 hours to fine -tune 7 billion parameter customized models.
Introduction: Fengshenbang-LM (Big Model of God) is a large model open source system dominated by the Idea Research Institute Cognitive Computing and Natural Language Research Center. Training models, with the ability of translation, programming, text classification, information extraction, summary, copywriting, common sense quiz, and mathematical computing. In addition to the Jiangziya series models, the project is also open to the models such as Taiyi and Erlang God series.
Billa:
Address: https://github.com/neutralzz/billa
Brief introduction: The project is open source of China -English bilingual LLAMA model with enhanced reasoning capabilities. The main characteristics of the model are: greatly enhance the Chinese understanding ability of LLAMA, and minimize damage to the English ability of the original LLAMA as much as possible; the training process increases the task type data, and uses CHATGPT to generate analysis to strengthen the model understanding task to solve the logic of the task; full quantity Parameter update, pursue better generating results.
MOSS:
Address: https://github.com/openlmlab/moss
Introduction: Support the open source dialogue language model of Chinese and English bilingual and multiple plugins. The MOSS base language model is pre -training in about 700 billion Chinese and English and code words. After subsequent dialogue instructions, plug -in enhancement learning and human preference training, it has the dialogue instructions, plug -in learning and human preference training. Multiple rounds of dialogue and ability to use multiple plug -ins.
Introduction: It includes a series of open source projects of large Chinese language models, which contains a series of language models based on the existing open source models (MOSS, LLAMA), instructions to fine -tune data sets.
Linly:
Address: https://github.com/cvi-szu/linly
Introduction: Provide Chinese dialogue model Linly-Chatflow, Chinese basic model Linly-Chinese-Llama and its training data. The Chinese basic model is based on LLAMA, using Chinese and Chinese and British parallel incremental training. The project summarizes the current multi-language instruction data, conducts large-scale instructions to follow the Chinese model to follow the training, and realize the Linly-Chatflow dialogue model.
Firefly:
Address: https://github.com/yangjianxin1/firefly
Introduction: Firefly is a large open source Chinese language model project. Open source includes data, fine -tuning code, multiple fine -tuning models such as Bloom, Baichuan, etc.; Filtering instructions; support most of the mainstream open source models, such as Baichuan Baichuan, Ziya, Bloom, LLAMA, etc. Holding LoRa and Base Model to merge weight, which is more convenient to reason.
Chatyuan
Address: https://github.com/Clue- ai/chatyuan
Introduction: A series of functional dialogue language models supported by Yuanyu Intelligent, which supports Sino -British bilingual dialogue, optimized in fine -tuning data, human feedback enhanced learning, thinking chain, etc.
Chatrwkv:
Address: https://github.com/blinkdl/chatrwkv
Introduction: Open Source a series of CHAT models (including English and Chinese) based on the RWKV architecture, published models including Raven, Novel-ChNeng, Novel-CH and Novel-Chneng-ChnPro, can directly chat and play poetry, novels and other creations. Including models of 7B and 14B.
CPM-Bee
Address: https://github.com/openbmbmbmb/cpm-bee
Brief introduction: A full open source, allowable commercial use of 10 billion parameters Chinese and English base models. It adopts Transformer's auto-regression architecture to conduct pre-training on high-quality corpus in Trillion, and has strong basic capabilities. Developers and researchers can adapt to various scenarios on the basis of the CPM-BEE base model to create application models in specific fields.
Introduction: A large-scale language model (LLM) with a multi-language and multi-task (LLM), open source includes models: Tigerbot-7B, Tigerbot-7B-Base, Tigerbot-180B, basic training and reasoning code, 100G pre-training data, covering finance and law The field of encyclopedia and API.
Introduction: Published by Zhiyuan Research Institute, the Aquila Language Model inherited the architectural design advantages of GPT-3, LLAMA, etc., replaced a group of more efficient underlying operators to achieve, redesigned the Chinese and English bilingual Tokenizer , Upgraded the BMTrain parallel training method, started from 0 on the basis of Chinese and English high -quality corpus. Through data quality control and optimization methods of multiple training, it is achieved in smaller data sets and shorter training time. Get better performance than other open source models. It is also the first large -scale open source language model that supports Sino -British bilingual knowledge, support commercial license agreement, and meets the needs of domestic data compliance.
Aquila2
Address: https://github.com/flagai-open/aquila2
Introduction: Published by Zhiyuan Research Institute, Aquila2 series, including basic language model Aquila2-7B, Aquila2-34B and Aquila2-70B-EXPR, dialogue model Aquilachat2-7b, Aquilachat2-34B and Aquilachat2-70B-EXPR, long text text Dialog Aquilachat2-7B-16K and Aquilachat2-34B-16.
Anima
Address: https://github.com/lyogavin/anima
Introduction: A open source of QLORA-based 33B Chinese Language Model developed by Ai Ten Technology. This model is based on QLORA's Guanaco 33B model. The training data set opened by the Chinese-Vicuna project guanaco_belle_mer_v1.0 has trained 10,000 STEPs for FineTune. Based on ELO RATING TOURNAMENT evaluation is better.
Knowlm
Address: https://github.com/zjunlp/knowlm
Introduction: The Knowlm project aims to publish the framework of open source large models and corresponding model weights to help reduce the problem of knowledge fallacy, including the difficulty of the knowledge of large models and potential errors and prejudices. The first phase of the project released LLAMA -based extraction of big model intelligence analysis, using Chinese and English corpus to further fully train LLAMA (13B), and optimizes knowledge extraction tasks based on knowledge graph conversion instruction technology.
Bayling
Address: https://github.com/ictnlp/bayling
Introduction: A large -scale universal model with enhanced cross -language alignment was developed by the Natural Language Treatment Team of the Institute of Computing Technology of the Chinese Academy of Sciences. Bayling uses LLAMA as the base model, exploring the method of fine -tuning instructions with interactive translation tasks as the core. It aims to complete language alignment at the same time and align with human intentions. English migration to other languages (Chinese). In the evaluation of multi -language translation, interactive translation, universal tasks, and standardized examinations, Bai Ling showed better performance in Chinese/English. Bai Ling provides an online version of DEMO for everyone to experience.
Yulan-chaat
Address: https://github.com/ruc-gsai/yulan- Chat
Introduction: Yulan-Chat is a big language model developed by Renmin University of China GSAI researchers. It is developed fine -tuned on the basis of LLAMA and has high -quality English and Chinese instructions. Yulan-Chat can chat with users, follow English or Chinese instructions well, and can be deployed on the GPU (A800-80g or RTX3090) after quantification.
Polylm
Address: https://github.com/damo-nlp-mt/polylm
Brief introduction: A multi -language model trained from the beginning of 640 billion words, including the size of two models (1.7B and 13B). POLYLM covers China, Britain, Russia, West, France, Portuguese, Germany, Italy, He, Bo, Bobo, Ashi, Hebrews, Japan, South Korea, Thailand, Vietnam, Indonesia and other types, especially more friendly to Asian language.
huozi
Address: https://github.com/hit-sCir/huozi
Introduction: A large -scale pre -training language model of a large -scale pre -training language model that is developed by Harbin Institute of Nature Language Treatment Research Institute. This model is based on the 7 billion parameter model of the BLOOM structure, which supports Chinese and English bilingual. The length of the context window is 2048. At the same time, it also opens the model of RLHF training and the 16.9K Chinese preference data set.
Yayi
Address: https://github.com/weenge-research/yayi
Introduction: The elegant model is fine -tuned in the high -quality field data of the high -quality field of millions of artificial structures. The training data covers five major areas of media propaganda, public opinion analysis, public safety, financial risk control, and urban governance. Task. From the iteration of the pre -training initialization of the pre -training, we gradually enhanced its basic Chinese ability and field analysis capabilities, and increased multiple rounds of dialogue and some plug -in capabilities. At the same time, after hundreds of users' internal testing, continuous artificial feedback optimization has been continuously improved, which further improves model performance and security. Open source of Chinese optimization model based on LLAMA 2, explores the latest practice suitable for Chinese missions in many fields of Chinese.
Yayi2
Address: https://github.com/weenge-research/yayi2
Introduction: YAYI 2 is a new generation of open source large language models developed by Zhongke Wenge, including Base and Chat versions with a parameter scale of 30B. Yayi2-30B is a large language model based on Transformer, using high-quality and multi-language corpus of more than 2 trillion tokens for pre-training. In response to the application scenarios in general and specific areas, we have used millions of instructions to fine -tune, and at the same time, we use human feedback to strengthen learning methods to better align the model and human values. This open source model is YAYI2-30B Base model.
Yuan-2.0
Address: https://github.com/ieit-yuan/yuan-2.0
Introduction: The project is open to a new generation of basic language model released by Inspur Information. It specifically opens all 3 model sources 2.0-102B, source 2.0-51b and source 2.0-2B. And provide relevant scripts for pre -training, fine -tuning, and reasoning services. Source 2.0 is based on source 1.0, using more high -quality pre -training data and fine -tuning data sets to make the model have stronger understanding in semantics, mathematics, reasoning, code, and knowledge.
Introduction: The project conducts pre-training Chinese-expansion tables based on the MiXTRAL-8X7B sparse hybrid expert model. It opens the CHINESE-MIXTRAL-8X7B word-expansion table model and the training code. The Chinese coding efficiency of this model is significantly improved than the original model. At the same time, through incremental pre -training on large -scale open source corpus, this model has a strong Chinese generation and understanding ability.
Bluelm
Address: https: //github.com/vivo-jlab/bluelm
Introduction: Bluelm is a large -scale pre -training language model independently developed by the Vivo AI Global Research Institute. This release contains the 7B foundation (Base) model and the 7B dialogue (CHAT) model. At the same time ) Model and dialogue (Chat) model.
Introduction: Turingmm-34B-Chat is an open source Chinese and English Chat model. Beijing Guangnian Unlimited Technology Co., Ltd. is based on the Yi-34B open source model, 14W refined education data, SFT fine-tuning and 15W alignment data. A fine -tuning model obtained.
Orion
Address: https://github.com/orionStarai/orion
Introduction: Orion-14B-Base is a multi-language model with 14 billion parameters. This model is trained on a diverse data set containing 2.5 trillion token, covering various types of Chinese, English, Japanese, Korean, etc. language.
Introduction: OrionStar-YI-34B-CHAT is the Hangion Starry Sky-based Yi-34B model based on the open source of 10,000 things. It uses 15W+ high-quality corpus training to fine-tune the big model, which aims to provide outstanding interactive experiences for large model community users.
Minicpm
Add
Introduction: MinicPM is a series of side-side models commonly opened by Noodle Wall Intelligence and Tsinghua University Natural Language Treatment Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word-embedded parameters, totaling 2.7B of parameters.
Mengzi3
Address: https://github.com/langboat/mengzi3
Introduction: Mengzi3 8B/13B model is based on the LLAMA architecture, with corpus selection from web pages, encyclopedia, social, media, news, and high -quality open source data sets. By continuing multi -language corpus training on trillion tokens, the Chinese ability of the model is outstanding and takes into account multi -language ability.
1.2 Multifamily LLM model
Visualglm-6B
Address: https://github.com/thudm/visualglm-6b
Introduction: An open source, multi-mode dialogue language model supporting images, Chinese, and English. The language model is based on Chatglm-6B and has 6.2 billion parameters. The model has a total of 7.8 billion parameters. Relying on the 30M high -quality Chinese graphic pair from the COGView data set, pre -training with the screened English graphic with 300M.
COGVLM
Address: https://github.com/thudm/cogvlm
Brief introduction: A powerful open source visual language model (VLM). COGVLM-17B has 10 billion visual parameters and 7 billion language parameters. COGVLM-17B has achieved SOTA performance in 10 classic cross-modular benchmark tests. COGVLM can accurately describe images, and almost no hallucinations appear.
Introduction: Multi -mode Chinese models developed based on Chinese LLAMA & Alpaca Model Project. Visualcla adds image encoding modules to the Chinese LLAMA/Alpaca model, so that the LLAMA model can receive visual information. On this basis, the Chinese graphic was used for multi -modal pre -training on the data. The alignment images and text representations were given to give it a basic multi -mode understanding ability; The ability to understand, execute and dialogue of multi-mode instructions is currently open source Visualcla-7B-V0.1.
LLASM
Address: https://github.com/linksoul- ai/llasm
Brief introduction: The first open source and commercial dialogue model that supports Chinese and English dual-voice-text multi-modal dialogue. The convenient voice input will greatly improve the experience of the large model with text as the input, while avoiding the tedious processes based on ASR solutions and possible errors that may be introduced. Currently open source Llasm-Chinese-Llama-2-7b, LLASM-BAICHUAN-7B and other models and data sets.
Viscpm
Add
Introduction: A open source multi-mode and large model series, supports Chinese and English bilingual multi-mode dialogue (VISCPM-CHAT models) and text to graph generation capabilities (VISCPM-PAINT model). VISCPM is based on tens of billions of parameters, a large-scale language model CPM-BEE (10B) training, and integrates the visual encoder (Q-FORMER) and the visual decoder (Diffusion-UNet) to support the input and output of the visual signal. Thanks to the excellent bilingual ability of the CPM-Bee base, VISCPM can only be pre-training through English multi-modal data to achieve excellent Chinese multi-modal ability.
Minicpm-v
地址:https://github.com/OpenBMB/MiniCPM-V
Introduction: The end -side multi -modal model series facing graphic understanding. Including a series of minicpm-v 2/2.6, parameters include 2B, 8B, etc., 2B multi-mode comprehensive performance surpassed the larger parameter size models such as Yi-VL 34B, COGVLM-CHAT 17B, Qwen-Vl-Chat 10B, 8B , Single, multi-map, and video understanding performance exceeded GPT-4V.
Qwen-vl
Address: https://github.com/qwenlm/qwen-vl
Introduction: It is a large -scale visual language model developed by Alibaba Cloud. It can be used as an input with images, texts, and detection boxes, and text and detection boxes. Features include: powerful performance: the best effect of the same general model in the standard English evaluation of the four categories of multi -mode tasks; multi -language dialogue models: naturally supports English, Chinese and other multi -language dialogue, end -to -end to end to end Support the long text recognition of Chinese and English bilingual in the picture; multi -diagram interlaced dialogue: support multi -diagram input and comparison, designated picture questions and answers, multi -picture literary creation, etc.; The first universal model that supports Chinese open domain positioning: expressed through Chinese open domain language expression Detecting box labeling; fine particle size recognition and understanding: Compared to the 224 resolution used by other open source LVLM, Qwen-VL is the first open source 448 resolution LVLM model. Higher resolution can improve fine -grained text recognition, document question answering and detection boxes.
Internvl/1.5/2.0
Address: https://github.com/opengvlab/internvl
Introduction: Open source multi -mode and big models are also the first model in China to break the 60 model on MMMU (multi -disciplinary Q & A). In the test of mathematical benchmark Mathvista, the score of 66.3%of the scholar · Vientiane is significantly higher than that of other closed source business models and open source models. In general chart benchmark Chartqa, documentation benchmark DOCVQA, information graphic category benchmark InfogramicVQA, and universal visual Q & A benchmark MMBENCH (V1.1), the scholar Vientiane also achieved the most advanced (SOTA) performance.
2. Application
2.1 Filtering in the vertical field
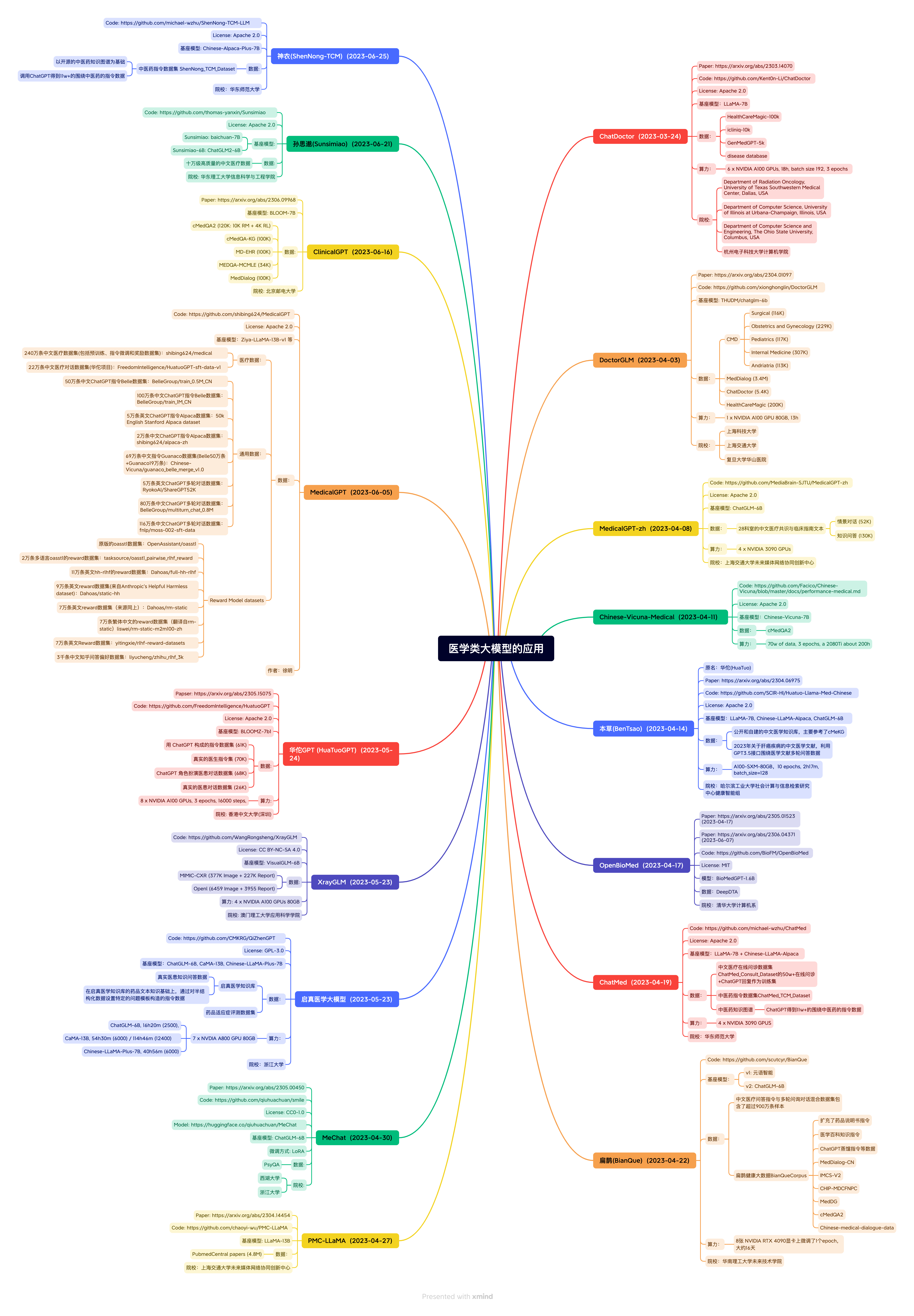
Medical care
Doctorglm:
Add
Introduction: Based on the Chinese consultation model of Chatglm-6B, fine-tuning through the Chinese medical dialogue data set, it has achieved fine-tuning and deployment of fine-tuning and deployment including LoRa, P-Tuningv2
Brief introduction: open source Llama-7B model of the Chinese medical instructions/instructions fine-tuning. Through medical knowledge maps and GPT3.5 API, a Chinese medical instruction data set was built, and on this basis, LLAMA was fine -tuned, which improved LLAMA's Q & A effect in the medical field.
Bianque:
Address: https://github.com/scutcyr/bianque
Introduction: A large model of medical dialogue with a multi-round inquiry dialogue with multiple rounds of inquiry dialogue. Based on the CLUEAI/Chatyuan-Large-V2 as the base, use the Chinese medical question and answer instruction to mixed database sets with multiple rounds of inquiry dialogue.
Introduction: open source, a GPT-Like model that has gone through Chinese medical instructions/instructions
Med-Chatglm:
Address: https://github.com/scir-hi/med-chatglm
Introduction: The CHATGLM model based on Chinese medical knowledge is fine -tuned, and the fine -tuning data is the same as BENTSAO.
Qizhengpt:
Address: https://github.com/cmkrg/qizhengptpt
Introduction: The project uses the Chinese medical instruction data set built by Qizhen Medical Knowledge Base, and based on this on the LLAMA-7B model, it has greatly improved the effect of the model in the Chinese medical scenario. Evaluate data sets, follow -up plans to optimize the question and answer effects of diseases, surgery, and inspection, and expand expansion of applications such as doctor -patient Q & A, automatic medical records and other applications.
ChatMed:
Address: https://github.com/michael-wzhu/chatmed
Introduction: The project launched a large-scale language model of Chinese medical treatment series in this project. The model of the model is LLAMA-7B and uses LoRa fine-tuning. Specific ChatMed-Consult: 50W+online consultation+Chatgpt reply based on Chinese medical online consultation data set ChatMed_Consult_dataset+Chatgpt reply as training Collection; ChatMed-TCM: Based on the Chinese medicine instruction data set ChatMed_TCM_DataSet, based on the open source Chinese medicine knowledge map, the entity-centered self-instruction method is used, and the ChatGPT is used to get 2.6W+around Pharmaceutical instruction data training is obtained.
XRayglm, the first Chinese multi -modal medical model that can watch the chest X -rays:
Address: https://github.com/wangrongSheng/xrayglm
Introduction: In order to promote the research and development of medical multi -modal models in the Chinese field, this project has released XRAYGLM data sets and models, which shows extraordinary potential in medical imaging diagnosis and multi -round interactive dialogue.
Mechat, Chinese Psychological Health Support Dialogue Model:
Address: https://github.com/qiuhuachuan/smile
Introduction: The open source of the project supports the general model by the Chatglm-6B LORA 16-BIT instruction.数据集通过调用gpt-3.5-turbo API扩展真实的心理互助QA为多轮的心理健康支持多轮对话,提高了通用语言大模型在心理健康支持领域的表现,更加符合在长程多轮对话的应用Scene.
简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
数据集说明:数据集通过ChatGPT改写真实的心理互助QA为多轮的心理健康支持多轮对话(single-turn to multi-turn inclusive language expansion via ChatGPT),该数据集含有56k个多轮对话,其对话主题、词汇和篇章语义更加丰富多样,更加符合在长程多轮对话的应用场景。
偏好数据集
CValues
地址:https://github.com/X-PLUG/CValues
数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议(safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
简介:一个中文版的大模型入门教程,围绕吴恩达老师的大模型系列课程展开,主要包括:吴恩达《ChatGPT Prompt Engineering for Developers》课程中文版,吴恩达《Building Systems with the ChatGPT API》课程中文版,吴恩达《LangChain for LLM Application Development》课程中文版等。
简介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more To go.
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.