The repository consists of a VQ-VAE implemented in PyTorch and trained on the MNIST dataset.
VQ-VAE follow the same basic concept as behind the variational auto-encoders(VAE). VQ-VAE use discrete latent embeddings for variational auto encoders,i.e. each dimension of z(latent vector) is a discrete integer, instead of the continuous normal distribution generally used while encoding the inputs.
VAEs consist of 3 parts:
Well, you may ask about the differences VQ-VAEs bring to the table. Let's list them out:
Many important real-world objects are discrete. For example in images we might have categories like “Cat”, “Car”, etc. and it might not make sense to interpolate between these categories. Discrete representations are also easier to model.
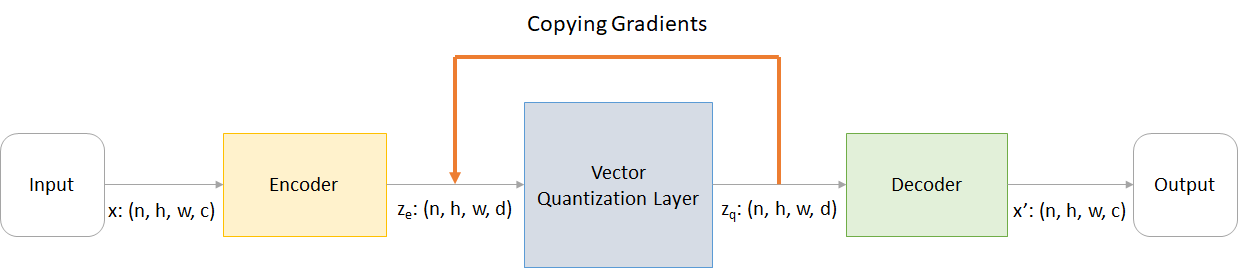
where:
n : batch sizeh : image heightw : image widthc : number of channels in the input imaged : number of channels in the hidden stateHere's a brief overview of the working of a VQ-VAE network:
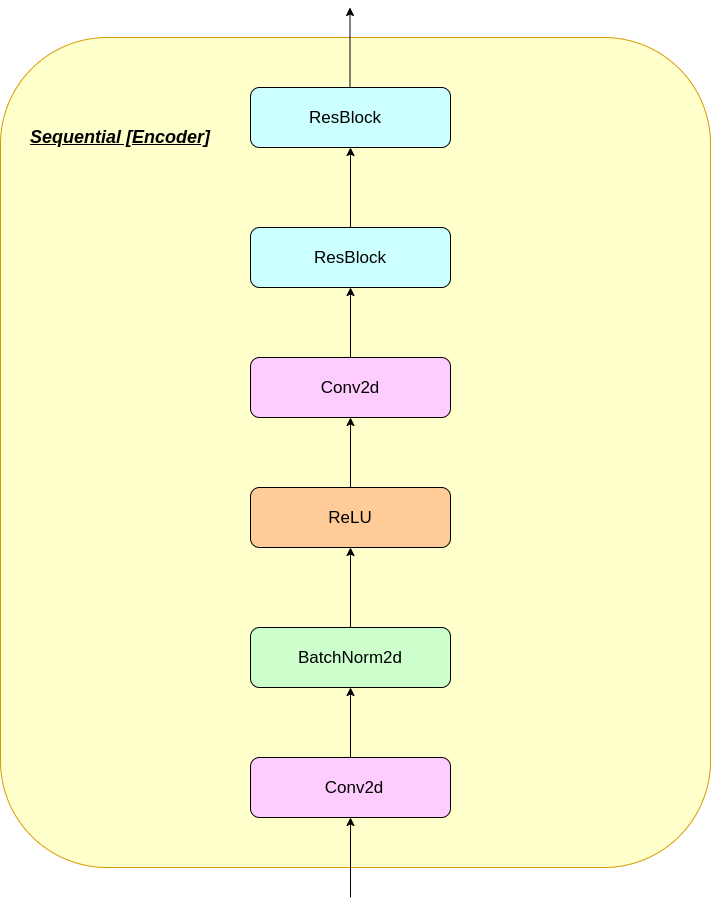
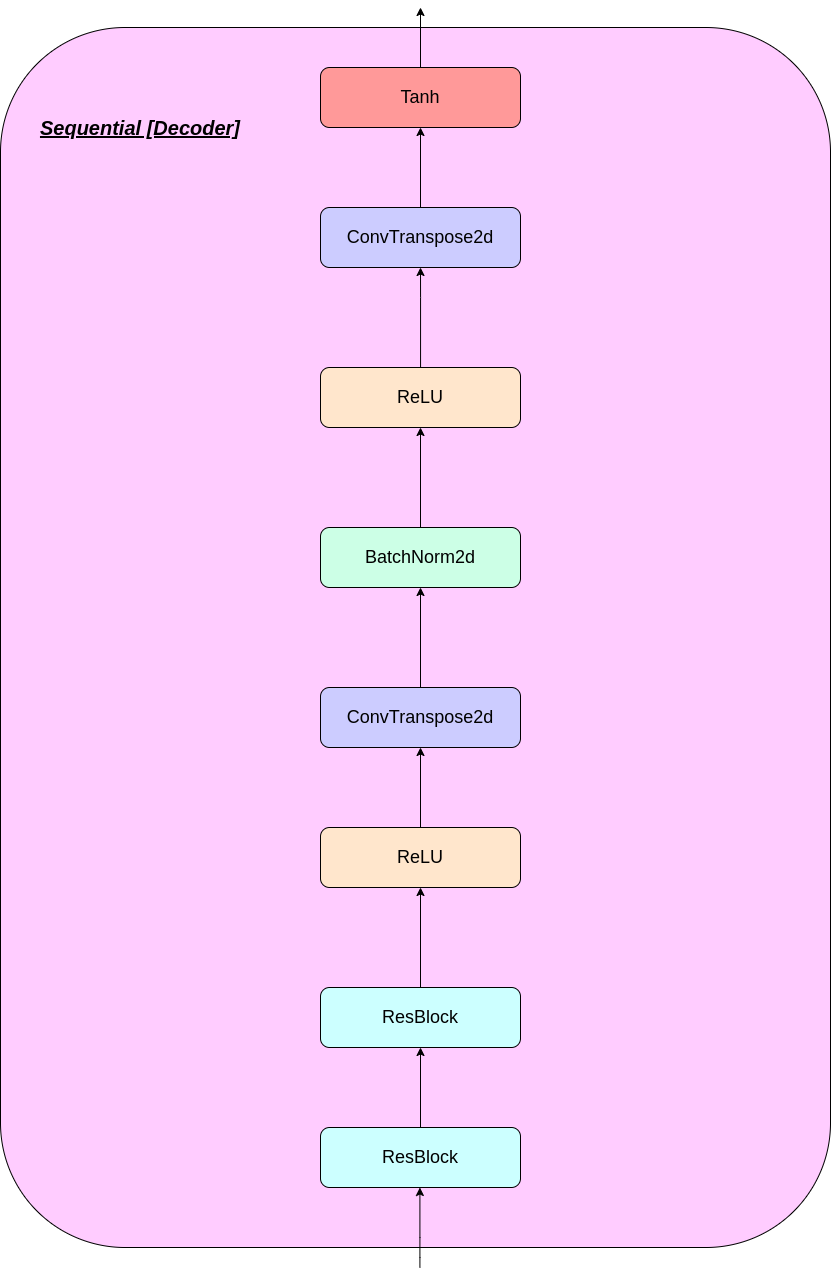
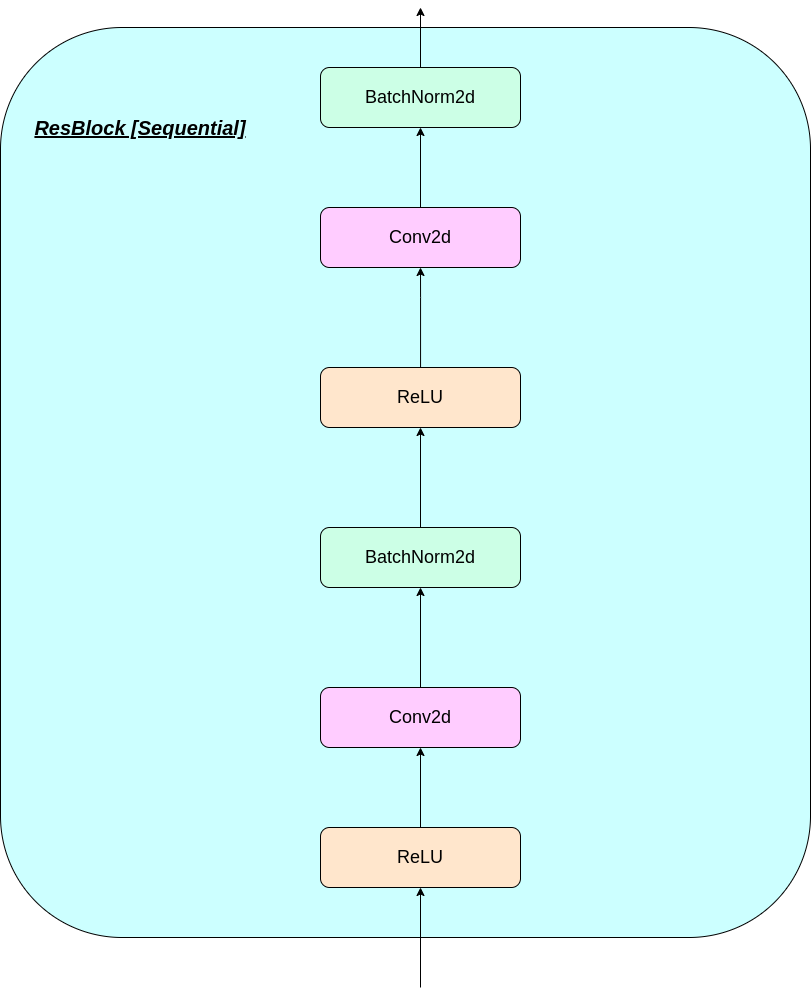
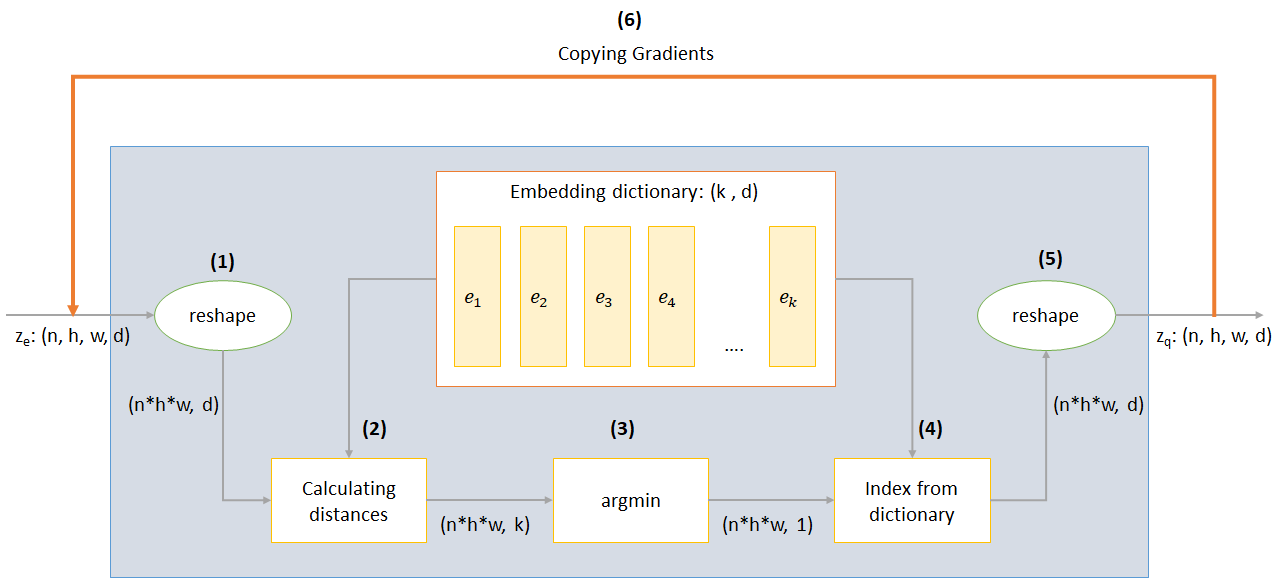
The working of VQ layer can be explained in six steps as numbered in the figure:
VQ-VAE uses 3 losses to compute the total loss during training:
Reconstruction loss: optimizes the decoder and encoder as VAE,i.e. the difference between the input image and the reconstruction:
reconstruction_loss = -log( p(x|z_q) )
CodeBook loss: due to the fact that gradients bypass the embedding, a dictionary learning algorithm which uses an l2 error to move the embedding vectors e_i towards the encoder output is used.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(sg represents stop gradient operator meaning no gradient flows through whatever it's applied on)
Commitment loss: since the volume of the embedding space is dimensionless, it can grow arbitrarily if the embeddings e_i do not train as fast as the encoder parameters, and thus a commitment loss is added to make sure that the encoder commits to an embedding.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β is a hyperparameter that controls how much we want to weigh commitment loss compared to other components)
You can either download the repo or clone it by running the following in cmd prompt
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
You can train the model from scratch by the following command (in google colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder- name of the data folderdata-folder - name of the data folderdevice - set the device (cpu or cuda, default: cpu)hidden-size - size of the latent vectors (default: 40 )k - number of latent vectors(default: 512)batch-size - batch size (default: 128)num-epochs - number of epochs (default: 10)lr - learning rate for Adam optimizer (default: 2e-4)beta - contribution of commitment loss, between 0.1 and 2.0 (default: 1.0)num-workers - number of workers for trajectories sampling (default: cpu_count() - 1)The program automatically downloads the MNIST dataset and saves it in PATH_TO_MNIST_dataset folder (you need to create this folder). This only happens once.
It also creates a logs folder and models folder and inside them creates a folder with the name passed by you to save logs and model checkpoints inside it respectively.
To generate new images from z sampled randomly from a unit gaussian run the following command(in google colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - filename containing the modelinput - MNIST or randomdevice - set the device (cpu or cuda, default: cpu)hidden-size - size of the latent vectors(default: 40 )k - number of latent vectors (default: 512)filename - name with which file is to be savedIt generates a 10*10 grid of images which are saved in a folder named generatedImages.
You can use a pre-trained model by downloading it from the link in model.txt.
The repository contains the following files
modules.py - Contains the different modules used for making our modelVQ-VAE.py - Contains the functions and code for training our VQ-VAE modelvector_quantizer.py - The vector quantization classes are defined in this filegenerate-py - Generates new images from a pre-trained modelmodel.txt - Contains a link to a pre-trained modelREADME.md - README giving an overview of the reporeferences.txt - references used while creating this reporeadme_images - Has various images for the readmeMNIST - Contains the zipped MNIST Dataset(though it will be downloaded automatically if needed)Training track for VQ-VAE.txt - contains the loss values during the training of our VQ-VAE modellogs_VQ-VAE - Contains the zipped tensorboard logs for our VQ-VAE model (automatically created by the program)testers.py - Contains some functions to test our defined modulesCommand to run tensorboard(in google colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Training Image
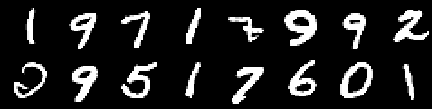
Image from 0th epoch

Image from 2nd epoch
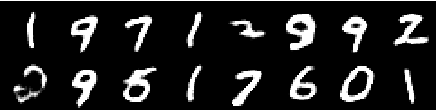
Image from 4th epoch
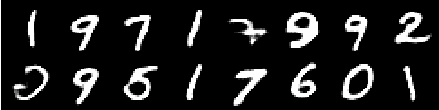
Image from 6th epoch
Image from 8th epoch
Image from 10th epoch
The reconstructions keep on improving and at the end almost resemble the training_set images which is reflected in the loss values(check in Training track for VQ-VAE.txt).
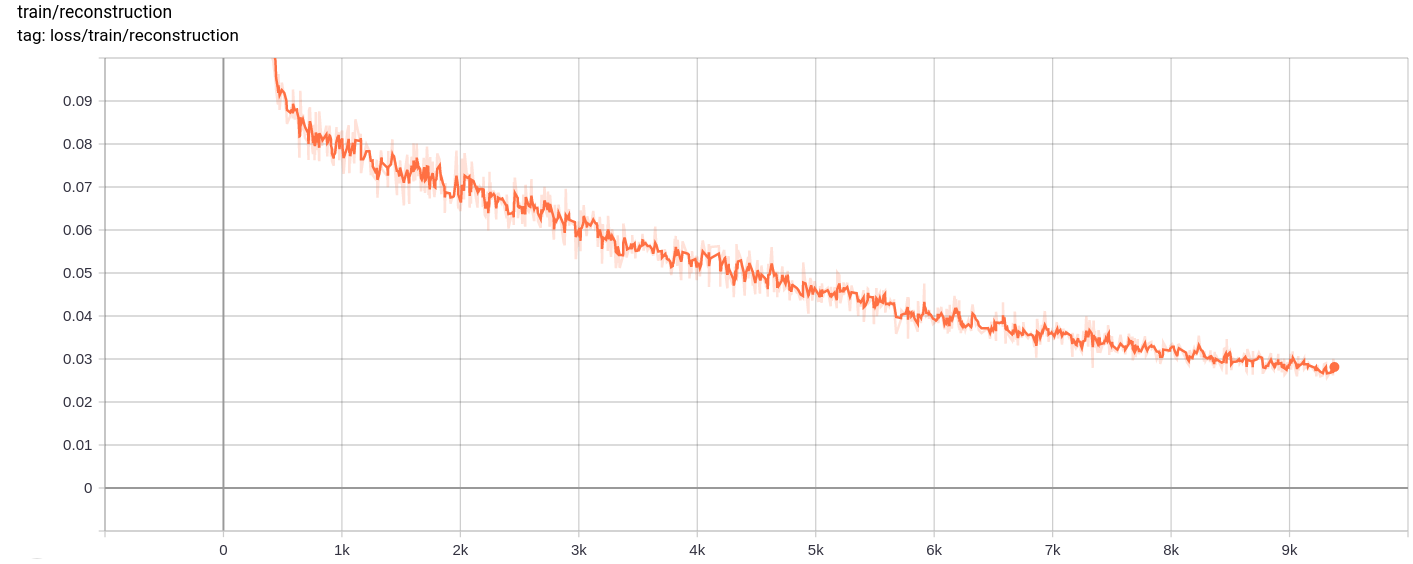
Reconstruction Loss
Quantization Loss
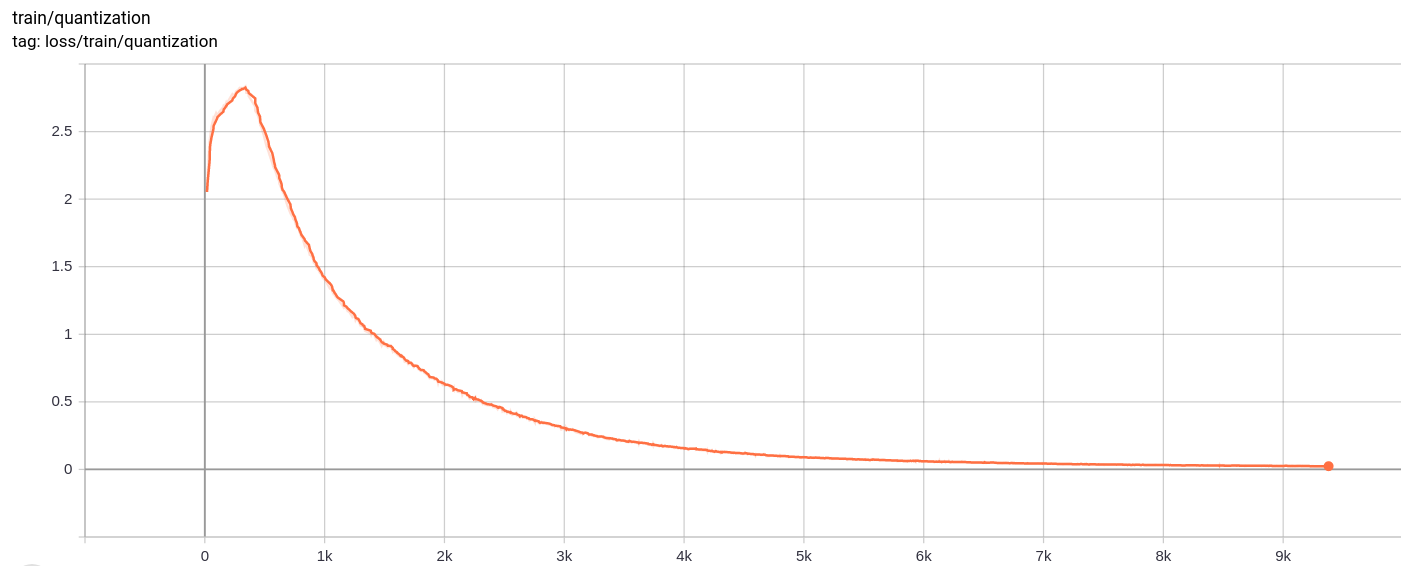
Total_Loss
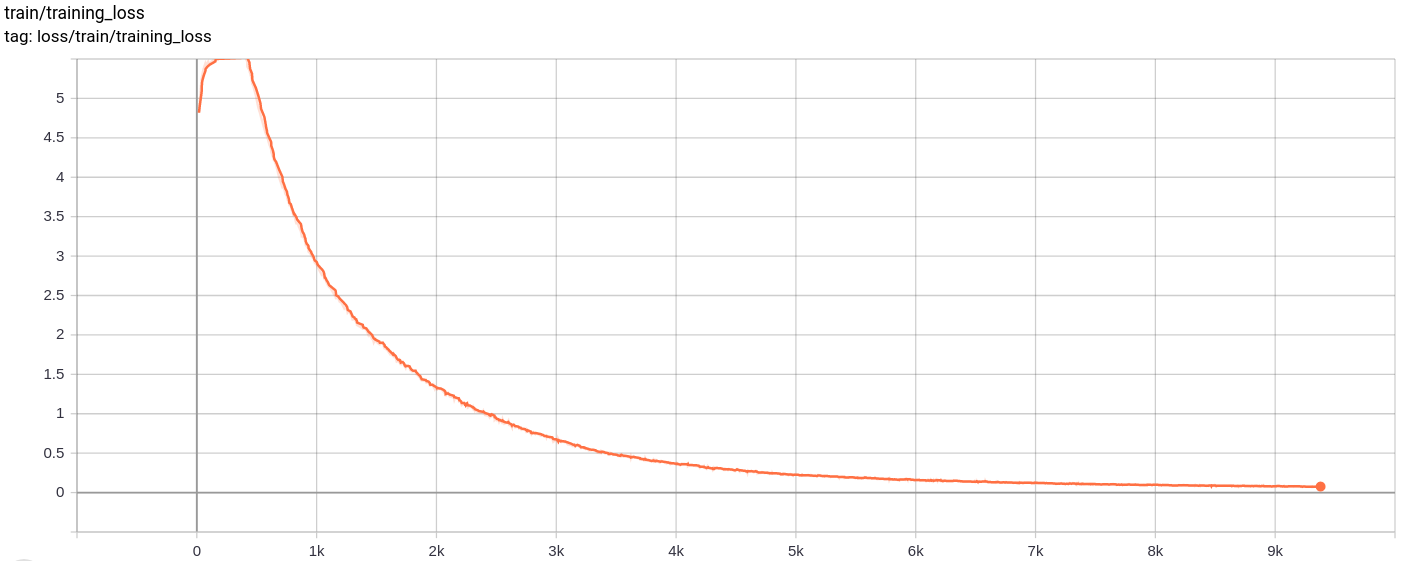
The total loss , reconstruction loss and quantization loss decrease uniformly as expected.
Testing_Loss
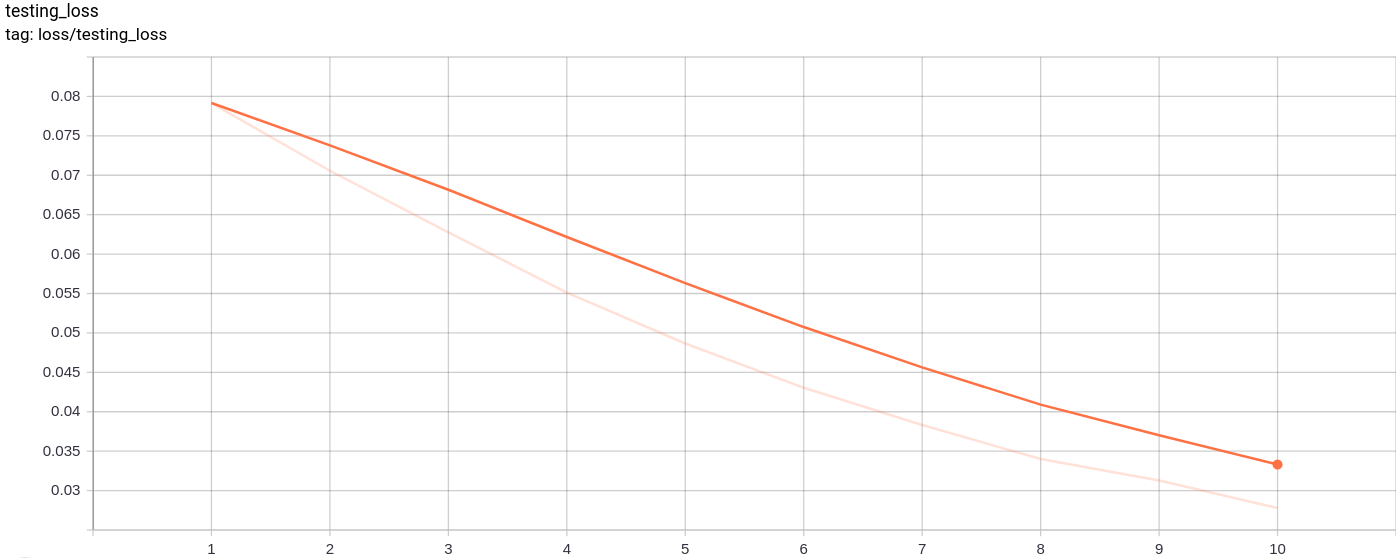
The testing loss decreases uniformly as expected.
The following image grid was generated after passing MNIST images as inputs:

The generation is pretty good.
The following image grids were generated after passing a z sampled randomly from a unit gaussian as input to model and then passed through the decoder


The images don't look perfect. Tuning the latent space's dimensions, number of embedding vectors etc. can help in generating better random images.
The model was trained on google colab for 10 epochs, with batch size 128.
After training the model was able to reconstruct the input images quite well, and was also able to generate new images although the generated images are not so good.
The training as well as the testing loss also kept on decreasing almost monotonically.
I observed that training the model for more than 10-20 epochs produced results that suggested a probable sign of overfitting in the model. Also, I experimented with different dimensions of the latednt space and in the end dimension = 40 produced the best results. The best range for dimension came out to be between 16-42.
The following sources helped a lot to make this repository


