a custom comfyui node for coqui-ai/TTS's xtts module! support 17 languages voice cloning and tts
English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt), Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh-cn), Japanese (ja), Hungarian (hu), Korean (ko) Hindi (hi)
We do not hold any responsibility for any illegal usage of the codebase. Please refer to your local laws about DMCA and other related laws. Responsibility. Please refer to your local DMCA (Digital Millennium Act) and other relevant laws and regulations.
srt file for subtitle was supportedsrt make sure ffmpeg is worked in your commandline for Linux
apt update
apt install ffmpeg
for Windows, you can install ffmpeg by WinetUI automatically
Then!
git clone https://github.com/AIFSH/ComfyUI-XTTS.git
cd ComfyUI-XTTS
pip install -r requirements.txt
weights will be downloaded from huggingface automatically! if you in china,make sure your internet attach the huggingface or if you still struggle with h uggingface, you may try following hf-mirror to config your env.
Or download the weight file and decompress it, put the entire folder of pretrained_models into ComfyUI-XTTS directory
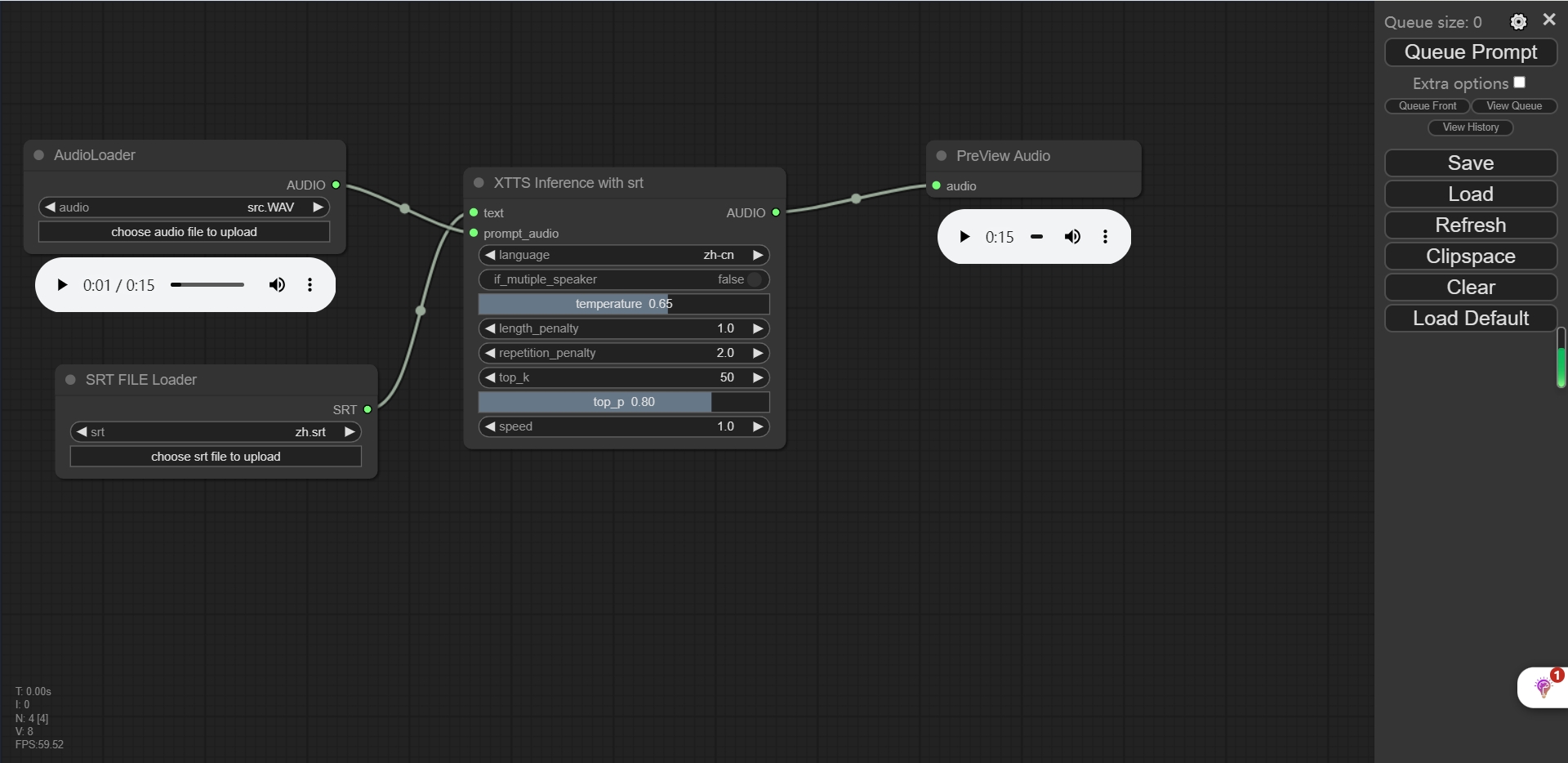
Demo
temperature : The softmax temperature of the autoregressive model. Defaults to 0.65.
length_penalty : A length penalty applied to the autoregressive decoder. Higher settings causes the model to produce more terse outputs. Defaults to 1.0.
repetition_penalty : A penalty that prevents the autoregressive decoder from repeating itself during decoding. Can be used to reduce the incident of long silences or “uhhhhhhs”, etc. Defaults to 2.0.
top_k : Lower values mean the decoder produces more “likely” (aka boring) outputs. Defaults to 50.
top_p : Lower values mean the decoder produces more “likely” (aka boring) outputs. Defaults to 0.8.
speed : The speed rate of the generated audio. Defaults to 1.0. (can produce artifacts if far from 1.0)


coqui-ai/TTS


