LLaMA Omni
1.0.0
Authors: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng*
LLaMA-Omni is a speech-language model built upon Llama-3.1-8B-Instruct. It supports low-latency and high-quality speech interactions, simultaneously generating both text and speech responses based on speech instructions.
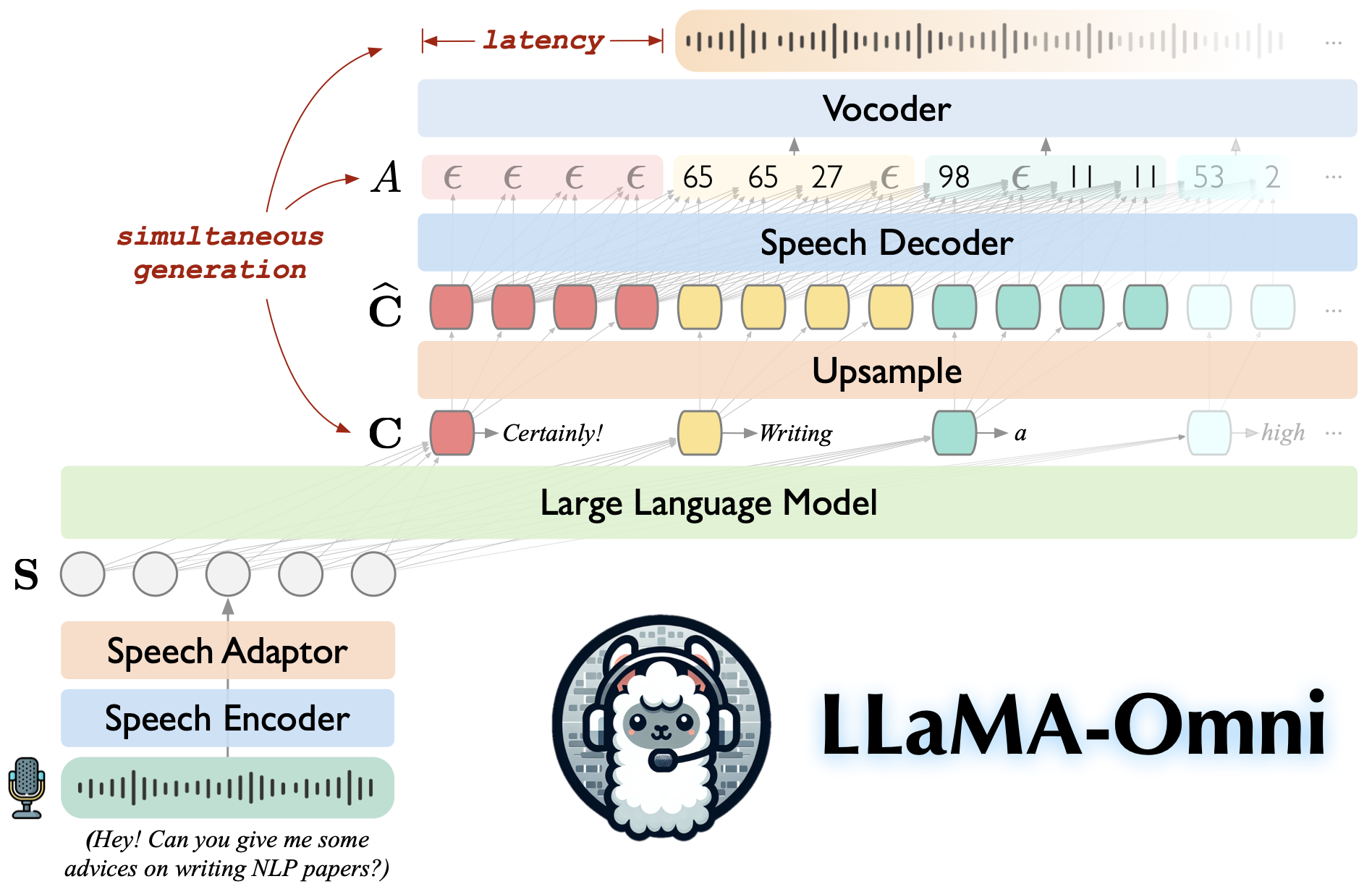
Built on Llama-3.1-8B-Instruct, ensuring high-quality responses.
Low-latency speech interaction with a latency as low as 226ms.
Simultaneous generation of both text and speech responses.
♻️ Trained in less than 3 days using just 4 GPUs.
Clone this repository.
git clone https://github.com/ictnlp/LLaMA-Omnicd LLaMA-Omni
Install packages.
conda create -n llama-omni python=3.10 conda activate llama-omni pip install pip==24.0 pip install -e .
Install fairseq.
git clone https://github.com/pytorch/fairseqcd fairseq pip install -e . --no-build-isolation
Install flash-attention.
pip install flash-attn --no-build-isolation
Download the Llama-3.1-8B-Omni model from ?Huggingface.
Download the Whisper-large-v3 model.
import whisper
model = whisper.load_model("large-v3", download_root="models/speech_encoder/")Download the unit-based HiFi-GAN vocoder.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -P vocoder/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -P vocoder/
Launch a controller.
python -m omni_speech.serve.controller --host 0.0.0.0 --port 10000
Launch a gradio web server.
python -m omni_speech.serve.gradio_web_server --controller http://localhost:10000 --port 8000 --model-list-mode reload --vocoder vocoder/g_00500000 --vocoder-cfg vocoder/config.json
Launch a model worker.
python -m omni_speech.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path Llama-3.1-8B-Omni --model-name Llama-3.1-8B-Omni --s2s
Visit http://localhost:8000/ and interact with LLaMA-3.1-8B-Omni!
Note: Due to the instability of streaming audio playback in Gradio, we have only implemented streaming audio synthesis without enabling autoplay. If you have a good solution, feel free to submit a PR. Thanks!
To run inference locally, please organize the speech instruction files according to the format in the omni_speech/infer/examples directory, then refer to the following script.
bash omni_speech/infer/run.sh omni_speech/infer/examples
Our code is released under the Apache-2.0 License. Our model is intended for academic research purposes only and may NOT be used for commercial purposes.
You are free to use, modify, and distribute this model in academic settings, provided that the following conditions are met:
Non-commercial use: The model may not be used for any commercial purposes.
Citation: If you use this model in your research, please cite the original work.
For any commercial use inquiries or to obtain a commercial license, please contact [email protected].
LLaVA: The codebase we built upon.
SLAM-LLM: We borrow some code about speech encoder and speech adaptor.
If you have any questions, please feel free to submit an issue or contact [email protected].
If our work is useful for you, please cite as:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

