awesome RLHF
1.0.0
This is a collection of research papers for Reinforcement Learning with Human Feedback (RLHF). And the repository will be continuously updated to track the frontier of RLHF.
Welcome to follow and star!
Awesome RLHF (RL with Human Feedback)
2024
2023
2022
2021
2020 and before
Detailed Explanation
Table of Contents
Overview of RLHF
Papers
Codebases
Dataset
Blogs
Other Language Support
Contributing
License
The idea of RLHF is to use methods from reinforcement learning to directly optimize a language model with human feedback. RLHF has enabled language models to begin to align a model trained on a general corpus of text data to that of complex human values.
RLHF for Large Language Model (LLM)
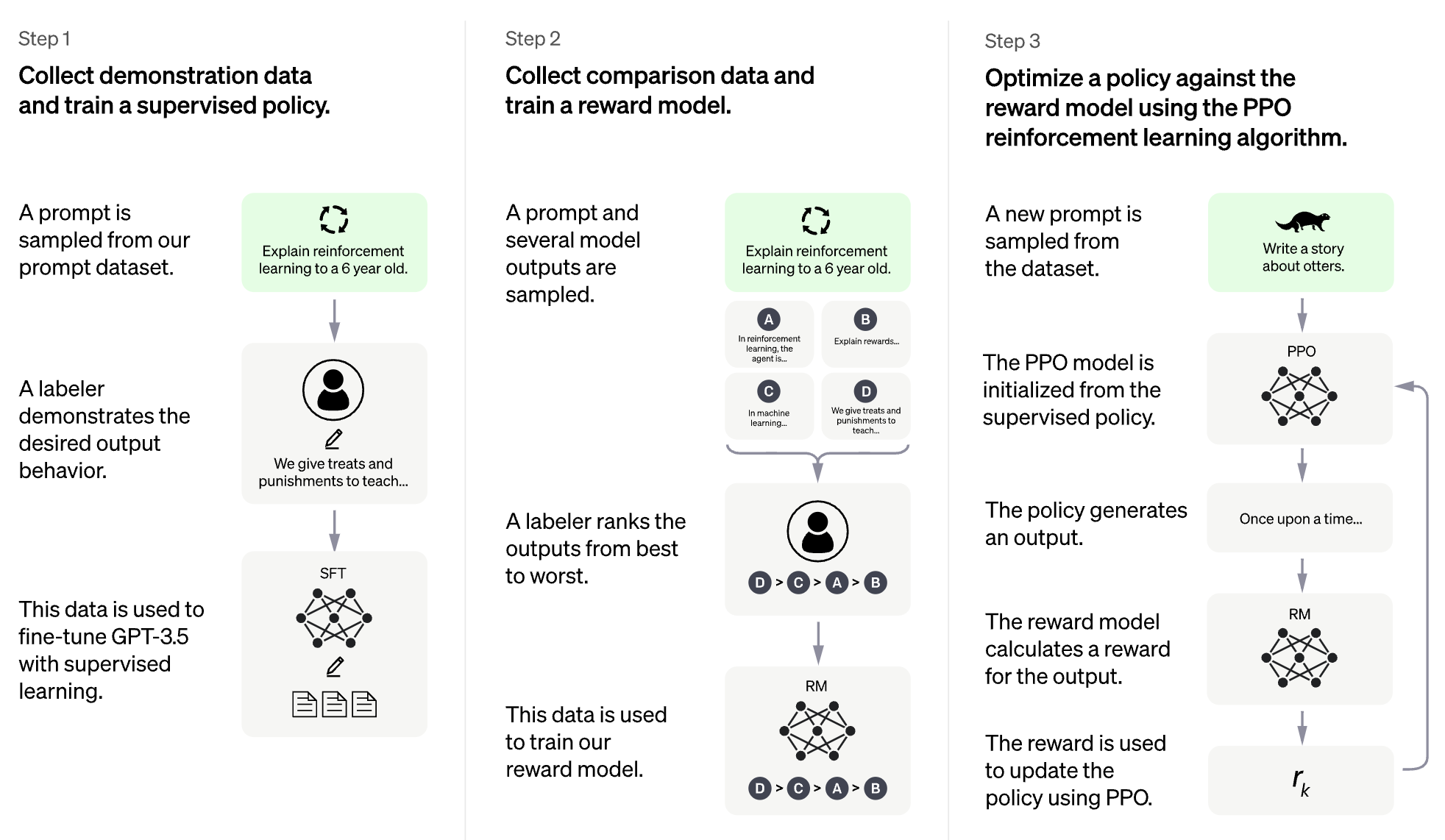
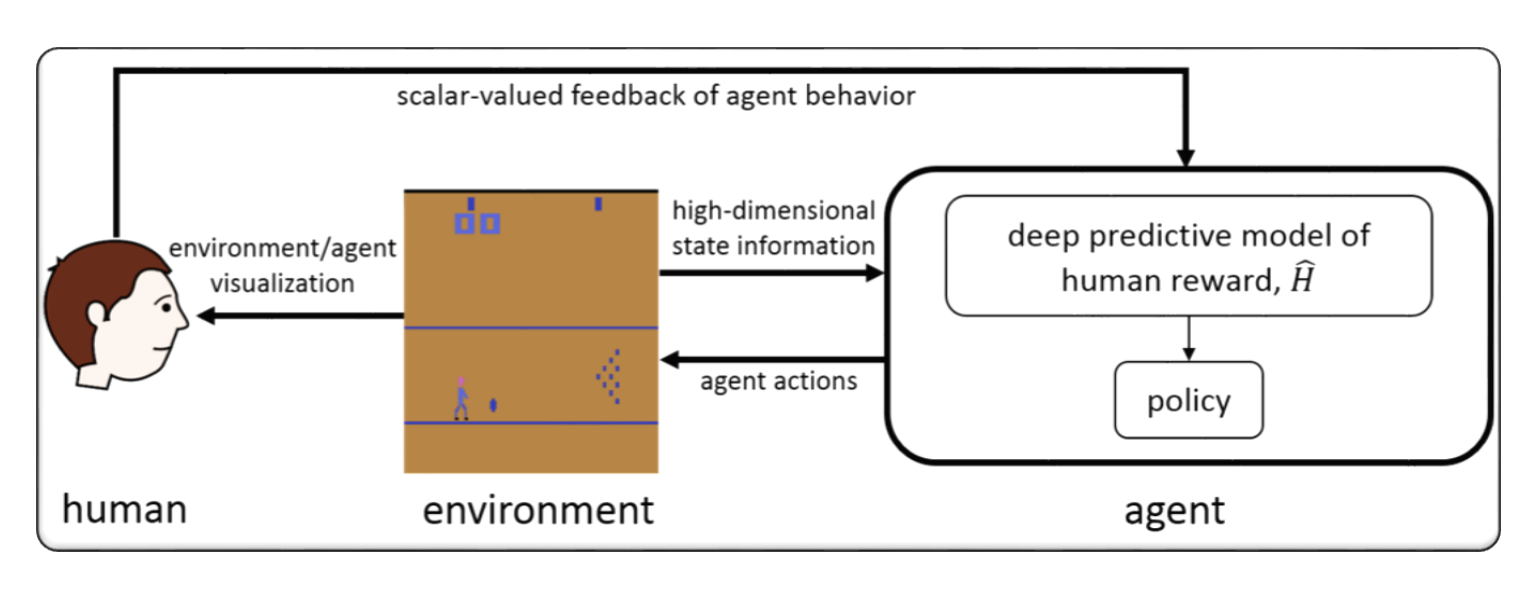
RLHF for Video Game (e.g. Atari)
(The following section was automatically generated by ChatGPT)
RLHF typically refers to "Reinforcement Learning with Human Feedback". Reinforcement Learning (RL) is a type of machine learning that involves training an agent to make decisions based on feedback from its environment. In RLHF, the agent also receives feedback from humans in the form of ratings or evaluations of its actions, which can help it learn more quickly and accurately.
RLHF is an active research area in artificial intelligence, with applications in fields such as robotics, gaming, and personalized recommendation systems. It seeks to address the challenges of RL in scenarios where the agent has limited access to feedback from the environment and requires human input to improve its performance.
Reinforcement Learning with Human Feedback (RLHF) is a rapidly developing area of research in artificial intelligence, and there are several advanced techniques that have been developed to improve the performance of RLHF systems. Here are some examples:
Inverse Reinforcement Learning (IRL): IRL is a technique that allows the agent to learn a reward function from human feedback, rather than relying on pre-defined reward functions. This makes it possible for the agent to learn from more complex feedback signals, such as demonstrations of desired behavior.
Apprenticeship Learning: Apprenticeship learning is a technique that combines IRL with supervised learning to enable the agent to learn from both human feedback and expert demonstrations. This can help the agent learn more quickly and effectively, as it is able to learn from both positive and negative feedback.
Interactive Machine Learning (IML): IML is a technique that involves active interaction between the agent and the human expert, allowing the expert to provide feedback on the agent's actions in real-time. This can help the agent learn more quickly and efficiently, as it can receive feedback on its actions at each step of the learning process.
Human-in-the-Loop Reinforcement Learning (HITLRL): HITLRL is a technique that involves integrating human feedback into the RL process at multiple levels, such as reward shaping, action selection, and policy optimization. This can help to improve the efficiency and effectiveness of the RLHF system by taking advantage of the strengths of both humans and machines.
Here are some examples of Reinforcement Learning with Human Feedback (RLHF):
Game Playing: In game playing, human feedback can help the agent learn strategies and tactics that are effective in different game scenarios. For example, in the popular game of Go, human experts can provide feedback to the agent on its moves, helping it improve its gameplay and decision-making.
Personalized Recommendation Systems: In recommendation systems, human feedback can help the agent learn the preferences of individual users, making it possible to provide personalized recommendations. For example, the agent could use feedback from users on recommended products to learn which features are most important to them.
Robotics: In robotics, human feedback can help the agent learn how to interact with the physical environment in a safe and efficient manner. For example, a robot could learn to navigate a new environment more quickly with feedback from a human operator on the best path to take or which objects to avoid.
Education: In education, human feedback can help the agent learn how to teach students more effectively. For example, an AI-based tutor could use feedback from teachers on which teaching strategies work best with different students, helping to personalize the learning experience.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Keyword: Flexible, Efficient, RLHF framework
Code: Official
ALaRM: Align Language Models via Hierarchical Rewards Modeling
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Keyword: Hierarchical Reward, Open Text Generation Tasks
Code: Official
TLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Eunseop Yoon, Hee Suk Yoon, SooHwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon On, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Keyword: Token-Level Continuous Reward, RLHF
Code: Official
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Keyword: Factually Augmented RLHF, Vision & Language, Human Preference Dataset
Code: Official
Direct Large Language Model Alignment Through Self-Rewarding Contrastive Prompt Distillation
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Keyword: Without Human Preference Data, Self-Reward, DPO
Code: Official
Arithmetic Control of LLMs for Diverse User Preferences: Directional Preference Alignment with Multi-Objective Rewards
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
Keyword: User Preference, Multi-objective Reward Model, Rejection Sampling Finetuning
Code: Official
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, Sara Hooker
Keyword: Online RL Optimization, Low Computational Cost
Code: Official
Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Keyword: Token-level Reward, LLM
Code: Official
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
Keyword: RL from AI Feedback
Code: official
Principled Penalty-based Methods for Bilevel Reinforcement Learning and RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
Keyword: Bilevel optimization
Code: official
Dense Reward for Free in Reinforcement Learning from Human Feedback
Alex James Chan, Hao Sun, Samuel Holt, Mihaela Van Der Schaar
Keyword: reward shaping, RLHF
Code: official
A Minimaximalist Approach to Reinforcement Learning from Human Feedback
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Keyword: Minimax Winner, Self-Play Preference Optimization
Code: official
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Keyword: Multimodal Large Language Models, Hallucination Problem, Reinforcement Learning from Human Feedback
Code: official
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Keyword: Online Iterative RLHF, Preference Modeling, Large Language Models
Code: official
MaxMin-RLHF: Towards equitable alignment of large language models with diverse human preferences
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Keyword: mixture of preference distributions, MaxMin alignment objective
Code: official
Dataset Reset Policy Optimization for RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Keyword: Dataset Reset Policy Optimization
Code: official
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Keyword: RLHF for Text-to-Image Generation, Dense Reward Improvement of DPO, Efficient Alignment
Code: official
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
Keyword: Self-Play Fine-Tuning
Code: official
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Keyword: RLHF, Oracular Reward, Reward Model Analysis, Survey
Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Keyword: Diffusion Models, Alignment, Reinforcement Learning, RLHF, Reward Overoptimization, Primacy Bias
Code: official
On Diversified Preferences of Large Language Model Alignment
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
Keyword: Aligning shared preference, Reward modeling metrics, LLM
Code: official
Aligning Crowd Feedback via Distributional Preference Reward Modeling
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
Keyword: RLHF, Preference distribution, Aligning, LLM
Beyond One-Preference-Fits-All Alignment: Multi-Objective Direct Preference Optimization
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Keyword: Multi-objective RLHF without reward modeling, DPO
Code: official
Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
Keyword: LLM inference-time attack, DPO, Producing harmful LLMs without training
Code: official
A Theoretical Analysis of Nash Learning from Human Feedback under General KL-Regularized Preference
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Keyword: Game-based RLHF, Nash Learning, Alignment under reward-model-free oracle
Mitigating the Alignment Tax of RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Tong Zhang
Keyword: RLHF, Alignment tax, Catastrophic forgetting
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, Sergey Levine
Keyword: reinforcement learning, RLHF, diffusion models
Code: official
AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng,Yujing Hu, Tangjie Lv, Changjie Fan, Zhipeng Hu
Keyword: Reinforcement learning; Diffusion models; RLHF; Preference aligning
Code: official
Dense Reward for Free in Reinforcement Learning from Human Feedback
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Keyword: RLHF
Code: official
Transforming and Combining Rewards for Aligning Large Language Models
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex D'Amour, Sanmi Koyejo, Victor Veitch
Keyword: RLHF, Aligning, LLM
Parameter Efficient Reinforcement Learning from Human Feedback
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li, Abhinav Rastogi, Lucas Dixon
Keywords: RLHF, Parameter Efficient method, Low Computational Cost, LLM, VLM
Improving Reinforcement Learning from Human Feedback with Efficient Reward Model Ensemble
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Keywords: RLHF, Reward Ensemble, Efficient Ensemble Method
A General Theoretical Paradigm to Understand Learning from Human Preferences
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Keywords: RLHF, Pairwise Preference
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Keyword: RLHF, Sentence-level Reward, LLM
Code: official
Preference-grounded Token-level Guidance for Language Model Fine-tuning
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Keyword: RLHF, Token-level Training Guidance, Alternate/Online Training Framework, Minimalist Training Objectives
Code: official
Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-oriented Dialogue Systems
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Keyword: RLHF, Genralized Reward Function Learning, Reward Function Utilization, Task-oriented Dialogue System, Learning-to-rank
Code: official
Inverse Preference Learning: Preference-based RL without a Reward Function
Joey Hejna, Dorsa Sadigh
Keyword: Inverse Preference Learning, without reward model
Code: official
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Keyword: RLHF, Simulation Framework
Code: official
Preference Ranking Optimization for Human Alignment
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
Keyword: Preference Ranking Optimization
Code: official
Adversarial Preference Optimization
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan Du
Keyword: RLHF, GAN, Adversarial Games
Code: official
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Keyword: RLHF, Iterative DPO, Mathematical foundation
Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
Keyword: RLHF, sample efficience, exploration
Reinforcement Learning from Statistical Feedback: the Journey from AB Testing to ANT Testing
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Keyword: RLHF, AB testing, RLSF
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Ben Pikus, Will LeVine, Tony Chen, Sean Hendryx
Keyword: RLHF, OOD, Distribution Shift
Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Keyword: RLHF, data-efficient, Alignment
Let's Reinforce Step by Step
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Keyword: RLHF, reasoning
Direct Preference-based Policy Optimization without Reward Modeling
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
Keyword: RLHF without reward modeling, Contrastive learning, Offline refinforcement learning
AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie Lv, Changjie Fan, Zhipeng Hu
Keyword: RLHF, Alignment, Diffusion model
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
Keyword: LLM based, reward functions design
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Keyword: Sale RL, LLM fine-ture
Quality Diversity through Human Feedback
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Keyword: Quality Diversity, Diffusion model
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Keyword: computational efficiency, variance-reduction technique
Tuning computer vision models with task rewards
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Keyword: Reward tuning in Computer Vision
The Wisdom of Hindsight Makes Language Models Better Instruction Followers
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
Keyword: Hindsight Instruction Relabeling, RLHF System, No Value Network Required
Code: official
Language Instructed Reinforcement Learning for Human-AI Coordination
Hengyuan Hu, Dorsa Sadigh
Keyword: Human-AI coordination, Human preference alignment, Instruction conditioned RL
Aligning Language Models with Offline Reinforcement Learning from Human Feedback
Jian Hu, Li Tao, June Yang, Chandler Zhou
Keyword: Decision Transformer-based Alignment, Offline Reinforcement Learning, RLHF System
Preference Ranking Optimization for Human Alignment
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li and Houfeng Wang
Keyword: Supervised Human Preference Alignment, Preference Ranking Extension
Code: official
Bridging the Gap: A Survey on Integrating (Human) Feedback for Natural Language Generation
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José G. C. de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André F. T. Martins
Keyword: Natural Language Generation, Human Feedback Integration, Feedback Formalization and Taxonomy, AI Feedback and Principles-Based Judgments
GPT-4 Technical Report
OpenAI
Keyword: A large-scale, multimodal model, Transformerbased model, Fine-tuned used RLHF
Code: official
Dataset: DROP, WinoGrande, HellaSwag, ARC, HumanEval, GSM8K, MMLU, TruthfulQA
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
Keyword: Rejection Sampling Finetuning, Alternative to PPO, Diffusion Model
Code: official
RRHF: Rank Responses to Align Language Models with Human Feedback without tears
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Keyword: New paradigm for RLHF
Code: official
Few-shot Preference Learning for Human-in-the-Loop RL
Joey Hejna, Dorsa Sadigh
Keyword: Preference Learning, Interactive Learning, Multi-task Learning, Expanding the pool of available data by viewing human-in-the-loop RL
Code: official
Better Aligning Text-to-Image Models with Human Preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Keyword: Diffusion Model, Text-to-Image, Aesthetic
Code: official
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Keyword: General-purpose text-to-Image human preference RM, Evaluating Text-to-Image Generative Models
Code: official
Dataset: COCO, DiffusionDB
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao liu, MoonKyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
Keyword: Text-to-Image, Stable diffusion model, Reward function that predicts human feedback
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Keyword: Visual Foundation Models, Visual ChatGPT
Code: official
Pretraining Language Models with Human Preferences (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Keyword: Pretraining, offline RL, Decision transformer
Code: official
Aligning Language Models with Preferences through f-divergence Minimization (f-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Keyword: f-divergence, RL with KL penalties
Principled Reinforcement Learning with Human Feedback from Pairwise or K-wise Comparisons
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Keyword: Pessimistic MLE, Max-entropy IRL
The Capacity for Moral Self-Correction in Large Language Models
Anthropic
Keyword: Improve moral self-correction capability by increasing RLHF training
Dataset; BBQ
Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté,Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Keyword: Optimizing language generators with RL, Benchmark, Performant RL algorithm
Code: official
Dataset: IMDB, CommonGen, CNN Daily Mail, ToTTo, WMT-16 (en-de),NarrativeQA, DailyDialog
Scaling Laws for Reward Model Overoptimization
Leo Gao, John Schulman, Jacob Hilton
Keyword: Gold reward model train proxy reward model, Dataset size, Policy parameter size, BoN, PPO
Improving alignment of dialogue agents via targeted human judgements (Sparrow)
Amelia Glaese, Nat McAleese, Maja Trębacz, et al.
Keyword: Information-seeking dialogue agent, Break down the good dialogue into natural language rules, DPC, Interact with the model to elicit violation of a specific rule (Adversarial Probing)
Dataset: Natural Questions, ELI5, QuALITY, TriviaQA, WinoBias, BBQ
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, et al.
Keyword: Red team language model, Investigate scaling behaviors, Read teaming Dataset
Code: official
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
Keyword: Real-time, Open-ended dialogue system, Pairs the succinct embedding of the conversation state by language models, CAQL, CQL, BERT
Quark: Controllable Text Generation with Reinforced Unlearning
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Keyword: Fine-tuning the language model on signals of what not to do, Decision Transformer, LLM tuning with PPO
Code: official
Dataset: WRITINGPROMPTS, SST-2, WIKITEXT-103
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, et al.
Keyword: Harmless assistants, Online mode, Robustness of RLHF training, OOD detection.
Code: official
Dataset: TriviaQA, HellaSwag, ARC, OpenBookQA, LAMBADA, HumanEval, MMLU, TruthfulQA
Teaching language models to support answers with verified quotes (GopherCite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat McAleese
Keyword: Generate answers which citing specific evidence, Abstain from answering when unsure
Dataset: Natural Questions, ELI5, QuALITY, TruthfulQA
Training language models to follow instructions with human feedback (InstructGPT)
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Keyword: Large Language Model, Align Language Model with Human Intent
Code: official
Dataset: TruthfulQA, RealToxicityPrompts
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
Keyword: RL from AI feedback(RLAIF), Training a harmless AI assistant through selfimprovement, Chain-of-thought style, Control AI behavior more precisely
Code: official
Discovering Language Model Behaviors with Model-Written Evaluations
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, et al.
Keyword: Automatically generate evaluations with LMs, More RLHF makes LMs worse, LM-written evaluations are highquality
Code: official
Dataset: BBQ, Winogender Schemas
Non-Markovian Reward Modelling from Trajectory Labels via Interpretable Multiple Instance Learning
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Keyword: Reward Modelling (RLHF), Non-Markovian, Multiple Instance Learning, Interpretability
Code: official
WebGPT: Browser-assisted question-answering with human feedback (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al.
Keyword: Model search the web and provide reference, Imitation learning, BC, long form question
Dataset: ELI5, TriviaQA, TruthfulQA
Recursively Summarizing Books with Human Feedback
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
Keyword: Model trained on small task to assist human evaluate broader task, BC
Dataset: Booksum, NarrativeQA
Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation
Samuel Kiegeland, Julia Kreutzer
Keyword: The success of policy gradient is because of reward rather than the shape of output distribution, Machine Translation, NMT, DOmain Adaption
Code: official
Dataset: WMT15, IWSLT14
Learning to summarize from human feedback
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Keyword: Care about summary quality, Training loss affect the model behavior, Reward model generalizes to new datasets
Code: official
Dataset: TL;DR, CNN/DM
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Keyword: Reward learning for language, Continuing text with positive sentiment, Summary task, Physical descriptive
Code: official
Dataset: TL;DR, CNN/DM
Scalable agent alignment via reward modeling: a research direction
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Keyword: Agent alignment problem, Learn reward from interaction, Optimize reward with RL, Recursive reward modeling
Code: official
Env: Atari
Reward learning from human preferences and demonstrations in Atari
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
Keyword: Expert demonstration trajectory preferences reward hacking problem, Noise in human label
Code: official
Env: Atari
Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
Keyword: High dimension state, Leverage the input of Human trainer
Code: third party
Env: Atari
Deep reinforcement learning from human preferences
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
Keyword: Explore goal defined in human preferences between pairs of trajectories segmentation, Learn more complex thing than human feedback
Code: official
Env: Atari, MuJoCo
Interactive Learning from Policy-Dependent Human Feedback
James MacGlashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
Keyword: Decision is influenced by current policy rather than human feedback, Learn from policy dependent feedback that converges to a local optimal
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
veRL: Volcano Engine Reinforcement Learning for LLM
ByteDance Seed MLSys Team & HKU: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Keyword: Flexible, Efficient, RLHF framework
Tasks: RLHF, Reasoning tasks including math and code.
OpenRLHF
OpenRLHF
Keyword: 70B, RLHF, DeepSpeed, Ray, vLLM
Task: An Easy-to-use, Scalable and High-performance RLHF Framework (Support 70B+ full tuning & LoRA & Mixtral & KTO).
PaLM + RLHF - Pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
Keyword: Transformers, PaLM architecture
Dataset: enwik8
lm-human-preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Keyword: Reward learning for language, Continuing text with positive sentiment, Summary task, Physical descriptive
Dataset: TL;DR, CNN/DM
following-instructions-human-feedback
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Keyword: Large Language Model, Align Language Model with Human Intent
Dataset: TruthfulQA RealToxicityPrompts
Transformer Reinforcement Learning (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Keyword: Train LLM with RL, PPO, Transformer
Task: IMDB sentiment
Transformer Reinforcement Learning X (TRLX)
Jonathan Tow, Leandro von Werra, et al.
Keyword: Distributed training framework, T5-based language models, Train LLM with RL, PPO, ILQL
Task: Fine tuning LLM with RL using provided reward function or reward-labeled dataset
RL4LMs (A modular RL library to fine-tune language models to human preferences)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté,Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Keyword: Optimizing language generators with RL, Benchmark, Performant RL algorithm
Dataset: IMDB, CommonGen, CNN Daily Mail, ToTTo, WMT-16 (en-de), NarrativeQA, DailyDialog
LaMDA-rlhf-pytorch
Phil Wang
Keyword: LaMDA, Attention-mechanism
Task: Open-source pre-training implementation of Google's LaMDA research paper in PyTorch
TextRL
Eric Lam
Keyword: huggingface's transformer
Task: Text generation
Env: PFRL, gym
minRLHF
Thomfoster
Keyword: PPO, Minimal library
Task: educational purposes
DeepSpeed-Chat
Microsoft
Keyword: Affordable RLHF Training
Dromedary
IBM
Keyword: Minimal human supervision, Self-aligned
Task: Self-aligned language model trained with minimal human supervision
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi, et al.
Keyword: Fine-Grained RLHF, providing a reward after every segment, Incorporating multiple RMs associated with different feedback types
Task: A framework that enables training and learning from reward functions that are fine-grained in density and multiple RMs -Safe-RLHF
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Keyword: Support popular pre-trained models, Large human-labeled dataset, Multi-scale metrics for safety constraints verification, Customized parameters
Task: Constrained Value-Aligned LLM via Safe RLHF
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Deep Ganguli
Keyword: Human preference dataset, Red teaming data, machine-written
Task: Open-source dataset for human preference data about helpfulness and harmlessness
Stanford Human Preferences Dataset(SHP)
Ethayarajh, Kawin and Zhang, Heidi and Wang, Yizhong and Jurafsky, Dan
Keyword: Naturally occurring and human-written dataset,18 different subject areas
Task: Intended to be used for training RLHF reward models
PromptSource
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Keyword: Prompted English datasets, Mapping a data example into natural language
Task: Toolkit for creating, Sharing and using natural language prompts
Structured Knowledge Grounding(SKG) Resources Collections
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Keyword: Structured Knowledge Grounding
Task: Collection of datasets are related to structured knowledge grounding
The Flan Collection
Longpre Shayne, Hou Le, Vu Tu et al.
Task: Collection compiles datasets from Flan 2021, P3, Super-Natural Instructions
rlhf-reward-datasets
Yiting Xie
Keyword: Machine-written dataset
webgpt_comparisons
OpenAI
Keyword: Human-written dataset, Long form question answering
Task: Train a long form question answering model to align with human preferences
summarize_from_feedback
OpenAI
Keyword: Human-written dataset, summarization
Task: Train a summarization model to align with human preferences
Dahoas/synthetic-instruct-gptj-pairwise
Dahoas
Keyword: Human-written dataset, synthetic dataset
Stable Alignment - Alignment Learning in Social Games
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
Keyword: Interaction data used for alignment training, Run in Sandbox
Task: Train on the recorded interaction data in simulated social games
LIMA
Meta AI
Keyword: without any RLHF, few carefully curated prompts and responses
Task: Dataset used for training the LIMA model
[OpenAI] ChatGPT: Optimizing Language Models for Dialogue
[Hugging Face] Illustrating Reinforcement Learning from Human Feedback (RLHF)
[ZhiHu] 通向AGI之路:大型语言模型 (LLM) 技术精要
[ZhiHu] 大语言模型的涌现能力:现象与解释
[ZhiHu] 中文hh-rlhf数据集上的ppo实践
[W&B Fully Connected] Understanding Reinforcement Learning from Human Feedback (RLHF)
[Deepmind] Learning through human feedback
[Notion] 深入理解语言模型的突现能力
[Notion] 拆解追溯 GPT-3.5 各项能力的起源
[gist] Reinforcement Learning for Language Models
[YouTube] John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
[OpenAI / Arize] OpenAI on Reinforcement Learning With Human Feedback
[Encord] Guide to Reinforcement Learning from Human Feedback (RLHF) for Computer Vision
[Weixun Wang] Overview of RL(HF)+LLM
Turkish
Our purpose is to make this repo even better. If you are interested in contributing, please refer to HERE for instructions in contribution.
Awesome RLHF is released under the Apache 2.0 license.


