ROSGPT_Vision
1.0.0
Bilel Benjdira, Anis Koubaa and Anas M. Ali
Robotics and Internet of Things Lab (RIOTU Lab), Prince Sultan University, Saudi Arabia
Inspired by ROSGPT. Both projects aim to bridge the gap between robotics, natural language understanding, and image analysis.
Collaborators who want to participate in this project, are very welcome.
An illustrative video demonstration of ROSGPT_Vision is provided:

ROSGPT_Vision offers a unified platform that allows robots to perceive, interpret, and interact with visual data through natural language. The framework leverages state-of-the-art language models, including LLAVA, MiniGPT-4, and Caption-Anything, to facilitate advanced reasoning about image data. LangChain is used for easy customization of the prompts. The provided implementation includes the CarMate application, a driver monitoring and assistance system designed to ensure safe and efficient driving experiences.

** for more information go to
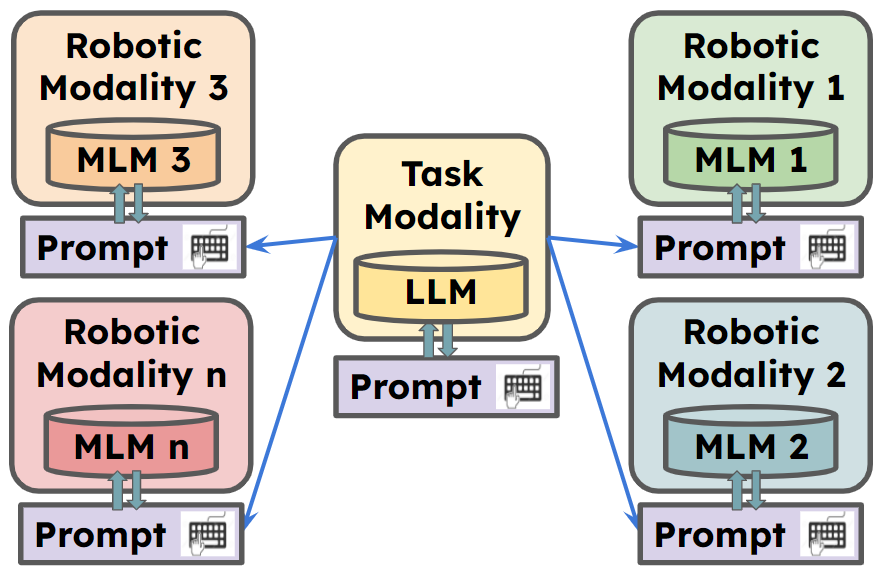
CarMate is a complete application for monitoring driver behavior which was developed just by setting two prompts in the YAML file. It automatically analyses the input video using the Visual prompt, analyses what should be done using the LLM prompt, and gives an instant alert to the driver when needed.
These are the prompts used to develop the application, without needing extra code:
The Visual prompt:
Visual prompt: "Describe the driver’s current level of focus
on driving based on the visual cues, Answer with one short sentence."
The LLM prompt:
LLM prompt:"Consider the following ontology: You must write your Reply
with one short sentence. Behave as a carmate that surveys the driver
and gives him advice and instruction to drive safely. You will be given
human language prompts describing an image. Your task is to provide
appropriate instructions to the driver based on the description."
We can see three examples of scenarios, got during the driving:
We can see in the top box the description generated by the image semantics module for the input image using the Visual prompt. Meanwhile, the second box generates the alert that should be given to the driver using the LLM prompt.



1. Prepare the code and the environment
Git clone our repository, creating a python environment and ativate it via the following command
git clone https://github.com/bilel-bj/ROSGPT_Vision.git
cd ROSGPT_Vision
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
git clone https://github.com/haotian-liu/LLaVA.git
conda env create -f environment.yml
conda activate ROSGPT_Vision2. Install the required dependencies
You can run image_semantics.py by install all required dependencies from LLAVA, MiniGPT-4 and Caption-Anything.
Ensure the installation of all requisite dependencies for ROS2.
The YAML contains 6 main sections of configurations parameters:
Task_name: This field specifies the name of the task that the ROS system is configured to perform.
ROSGPT_Vision_Camera_Node: This section contains the configuration for the ROSGPT_Vision_Camera_Node.
Image_Description_Method: This field specifies the method used by the node to generate descriptions from images. It can be one of the currently developed methods: MiniGPT4, LLaVA, or SAM. The configurations needed for everyone of them is put separately at the end of this file.
Vision_prompt: This field specifies the prompt used to guide the image description process.
Output_video: This field specifies the path or the name of where to save the output video file.
GPT_Consultation_Node: This section contains the configuration for the GPT_Consultation_Node.
llm_prompt: This field specifies the prompt used to guide the language model.
GPT_temperature: This field specifies the temperature parameter for the GPT model, which controls the randomness of the model's output.
MiniGPT4_parameters: This section contains the configuration for the MiniGPT4 model. It should be clearly set if the model is used in this task, otherwise it could be empty.
configuration: This field specifies the path for the configuration file of MiniGPT4.
temperature_miniGPT4: This field specifies the temperature parameter for the MiniGPT4 model.
llava_parameters: This section contains the configuration for the llavA model (if used).
SAM_parameters: This section contains the configuration for the SAM model.
colcon build --packages-select rosgpt_vision
source install/setup.bash
python3 src/rosgpt_vision/rosgpt_vision/rosgpt_vision_node_web_cam.py
python3 src/rosgpt_vision/rosgpt_vision/ROSGPT_Vision_Camera_Node.py /home/anas/ros2_ws/src/rosgpt_vision/rosgpt_vision/cfg/driver_phone_usage.yaml colcon build --packages-select rosgpt_vision
source install/setup.bash
python3 src/rosgpt_vision/rosgpt_vision/ROSGPT_Vision_GPT_Consultation_Node.py /home/anas/ros2_ws/src/rosgpt_vision/rosgpt_vision/cfg/driver_phone_usage.yamlbash ros2 topic echo /Image_Description
bash ros2 topic echo /GPT_Consultation
@misc{benjdira2023rosgptvision,
title={ROSGPT_Vision: Commanding Robots Using Only Language Models' Prompts},
author={Bilel Benjdira and Anis Koubaa and Anas M. Ali},
year={2023},
eprint={2308.11236},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
This project is licensed under the Creative Commons Attribution-NonCommercial 4.0 International License. You are free to use, share, and adapt this material for non-commercial purposes, as long as you provide attribution to the original author(s) and the source.
The codes are based on ROSGPT, LLAVA, MiniGPT-4, Caption-Anything and SAM. Please also follow their licenses. Thanks for their awesome works.
As this project is still under progress, contributions are welcome! To contribute, please follow these steps:
Before submitting your pull request, please ensure that your changes do not break the build and adhere to the project's coding style.
For any questions or suggestions, please open an issue on the GitHub issue tracker.


