kubeai
helm-chart-models-0.9.0
Get inferencing running on Kubernetes: LLMs, Embeddings, Speech-to-Text.
✅️ Drop-in replacement for OpenAI with API compatibility
⚖️ Scale from zero, autoscale based on load
? Serve text generation models (LLMs, VLMs, etc.)
Speech to Text API
? Embedding/Vector API
Multi-platform: CPU-only, GPU, TPU
? Model caching with shared filesystems (EFS, Filestore, etc.)
Zero dependencies (does not depend on Istio, Knative, etc.)
Chat UI included (OpenWebUI)
? Operates OSS model servers (vLLM, Ollama, FasterWhisper, Infinity)
✉ Stream/batch inference via messaging integrations (Kafka, PubSub, etc.)
Quotes from the community:
reusable, well abstracted solution to run LLMs - Mike Ensor
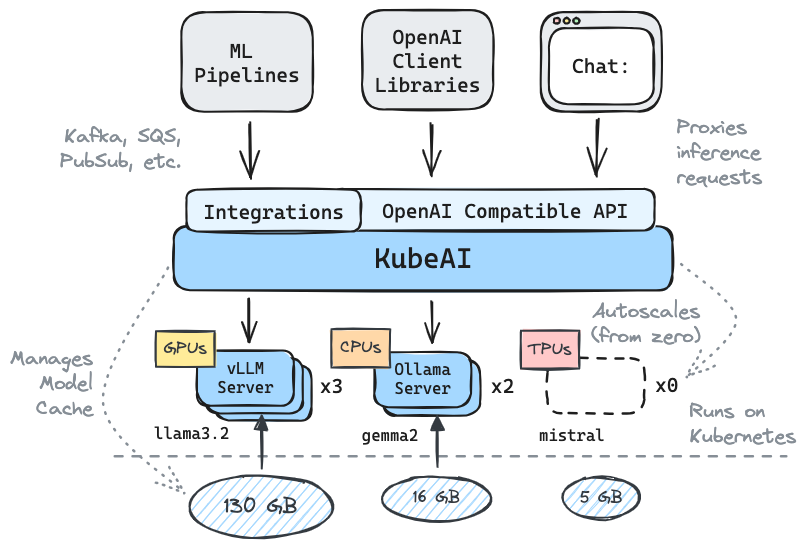
KubeAI serves an OpenAI compatible HTTP API. Admins can configure ML models via kind: Model Kubernetes Custom Resources. KubeAI can be thought of as a Model Operator (See Operator Pattern) that manages vLLM and Ollama servers.
Create a local cluster using kind or minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startAdd the KubeAI Helm repository.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstall KubeAI and wait for all components to be ready (may take a minute).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstall some predefined models.
cat <<EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlBefore progressing to the next steps, start a watch on Pods in a standalone terminal to see how KubeAI deploys models.
kubectl get pods --watchBecause we set minReplicas: 1 for the Gemma model you should see a model Pod already coming up.
Start a local port-forward to the bundled chat UI.
kubectl port-forward svc/openwebui 8000:80Now open your browser to localhost:8000 and select the Gemma model to start chatting with.
If you go back to the browser and start a chat with Qwen2, you will notice that it will take a while to respond at first. This is because we set minReplicas: 0 for this model and KubeAI needs to spin up a new Pod (you can verify with kubectl get models -oyaml qwen2-500m-cpu).
Checkout our documentation on kubeai.org to find info on:
List of known adopters:
| Name | Description | Link |
|---|---|---|
| Telescope | Telescope uses KubeAI for multi-region large scale batch LLM inference. | trytelescope.ai |
| Google Cloud Distributed Edge | KubeAI is included as a reference architecture for inferencing at the edge. | LinkedIn, GitLab |
| Lambda | You can try KubeAI on the Lambda AI Developer Cloud. See Lambda's tutorial and video. | Lambda |
If you are using KubeAI and would like to be listed as an adopter, please make a PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/*NOTE: KubeAI was born out of a project called Lingo which was a simple Kubernetes LLM proxy with basic autoscaling. We relaunched the project as KubeAI (late August 2024) and expanded the roadmap to what it is today.
? Don't forget to drop us a star on GitHub and follow the repo to stay up to date!
Let us know about features you are interested in seeing or reach out with questions. Visit our Discord channel to join the discussion!
Or just reach out on LinkedIn if you want to connect:


