Reading_groups
1.0.0
The power of computing : A lot of evidence shows that advances in machine learning are largely driven by computing, not research, please refer to "The Bitter Lesson", and there are often Emergence and Homogenization phenomena. Studies have shown that the use of artificial intelligence computing doubles about every 3.4 months, while the efficiency improvement only doubles every 16 months. Among them, the amount of calculation is mainly driven by computing power, while the efficiency is driven by research. This means that computing growth has historically dominated advances in machine learning and its subfields. This is further proven by the emergence of GPT-4. Despite this, we still need to pay attention to whether there will be a more subverted architecture in the future, such as S4. Most of the current NLP research hotspots are based on more advanced LLM (~100B,
For more LLM topics papers please refer to here and here.
Papers ( rough category )
resource
【Testing on GPT-4, limitation】Sparks of Artificial General Intelligence: Early experiments with GPT-4
【InstructGPT papers, including sft, ppo, etc., one of the most important articles】 Training language models to follow instructions with human feedback
【scalable oversight: How can humans continue to improve their models after their models exceed their own tasks? 】Measuring Progress on Scalable Oversight for Large Language Models
【Definition of Alignment, produced by deepmind】Alignment of Language Agents
A General Language Assistant as a Laboratory for Alignment
[RETRO paper, model searched using CCA+] Improving language models by retrieving from trillions of tokens
Fine-Tuning Language Models from Human Preferences
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
【Big model in Chinese and English, exceeding GPT-3】GLM-130B: An Open Bilingual Pre-trained Model
【Pre-training target optimization】UL2: Unifying Language Learning Paradigms
【Alignment’s new benchmarks, model libraries and new methods】Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
【MLM without the [MASK] tags through technology】Representation Deficiency in Masked Language Modeling
【Text to image training relieves Vocabulary's needs and resists certain attacks】 Language Modelling with Pixels
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval
InCoder: A Generative Model for Code Infilling and Synthesis
[Search Text-related images for language model pre-training] Visually-Augmented Language Modeling
A Non-monotonic Self-terminating Language Model
【Comparison and fine-tuning of negative feedback through propt design】 Chain of Hindsight Aligns Language Models with Feedback
【Sparrow Model】Improving alignment of dialog agents via targeted human judgements
[Use small model parameters to accelerate the training process of large model (not starting from scratch)] Learning to Grow Pretrained Models for Efficient Transformer Training
[MoE semi-parametric knowledge fusion model for multiple knowledge sources] Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models
[Merge method for merging multiple trained models on different datasets] Dataless Knowledge Fusion by Merging Weights of Language Models
[It is very inspiring that the search mechanism replaces the general architecture of FFN in Transformer (×2.54 time) to decouple knowledge stored in model parameters] Language model with Plug-in Knowldge Memory
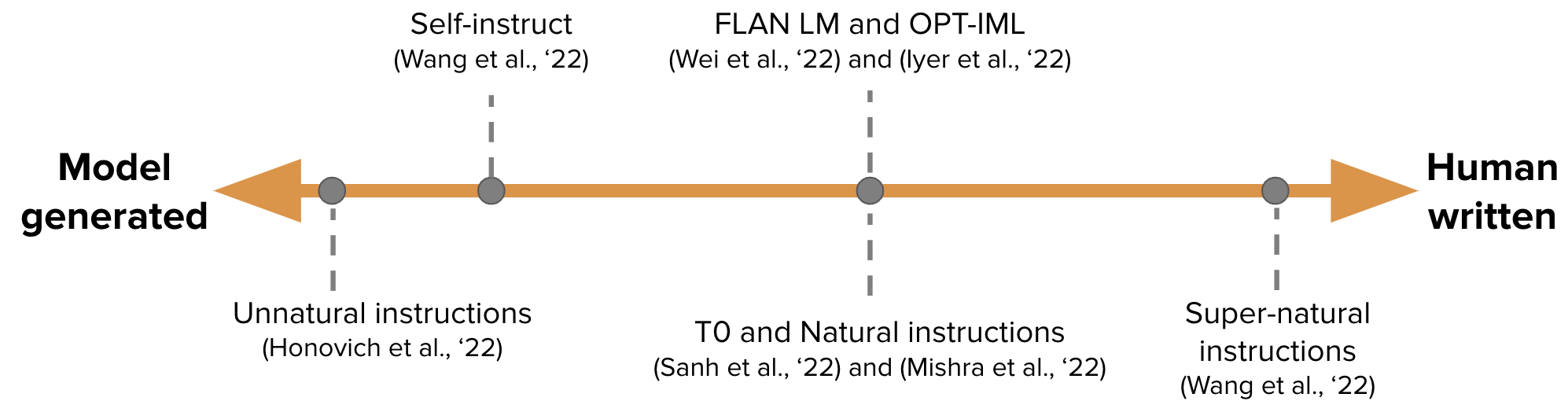
【Automatically generate Instruction tuning data for GPT-3 training】 Self-Instruction: Aligning Language Model with Self Generated Instructions
- 
Towards Conditionally Dependent Masked Language Models
【Iteratively calibrate imperfectly generated independent correctors, Sean Welleck's follow-up article】Generating Sequences by Learning to Self-Correct
[Continuous Learning: Add a propt for the new task, and the previous task's propt and the big model remain unchanged] Progressive Prompts: Continual Learning for Language Models without Forgetting
[EMNLP 2022, continuous update of the model] MemPrompt: Memory-assisted Prompt Editing with User Feedback
【New Neural Architecture (FOLNet), which contains first-order logical induction bias】 Learning Language Representations with Logical Inductive Bias
GanLM: Encoder-Decoder Pre-training with an Auxiliary Discriminator
【Pretraining language model based on state-space models, exceeding BERT】Pretraining Without Attention
[Consider human feedback during pre-training] Pretraining Language Models with Human Preferences
[Meta's open source LLaMA model, 7B-65B, trains more labeled small models than usual, achieving optimal performance under various inference budgets] LLaMA: Open and Efficient Foundation Language Models
[Teaching large language models to self-debug and explain the generated code through a small number of examples, but they have been used like this now] Teaching Large Language Models to Self-Debug
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
LIMA: Less Is More for Alignment
【Tree-of-thought, more and more like alphago】Deliberate Problem Solving with Large Language Models
【Multi-step reasoning method for applying ICL is very inspiring】ReAct: Synergizing Reasoning and Acting in Language Models
【CoT directly generates program code, and then lets python interpreter execute】 Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks
[Big model directly generates evidence context] Generate rather than Retrieve: Large Language Models are Strong Context Generators
【Writing model with 4 specific operations】PEER: A Collaborative Language Model
【Combining Python, SQL executors and big models】Binding Language Models in Symbolic Languages
[Retrieve the document generation code] DocPrompting: Generating Code by Retrieving the Docs
[There will be many articles in Grounding+LLM in the next series] LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
【Self-Iterative Generation (Verified using Python) Training Data】 Language Models Can Teach Themselves to Program Better
Related articles: Specializing Smaller Language Models towards Multi-Step Reasoning
STaR: Bootstrapping Reasoning With Reasoning, from Neurips 22 (generate CoT data for model fine-tuning), causing a series of CoT articles teaching small models.
Similar ideas [Knowledge Distillation] Teaching Small Language Models to Reason and Learning by Distilling Context
Similar ideas KAIST and Xiang Ren groups ([CoT's rationale fine-tuning (professor)] PINTO: Faithful Language Reasoning Using Prompt-Generated Rationales, etc.) and Large Language Models Are Reasoning Teachers
ETH's [CoT data trains problem decomposition and problem-solving models separately] Distilling Multi-Step Reasoning Capabilities of Large Language Models into Smaller Models via Semantic Decompositions
【Let small models learn CoT abilities】In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models
【Big Model Teach Small Model CoT】 Large Language Models Are Reasoning Teachers
[Big model generates evidence (recitation) and then performs small sample closed-book question and answer] Recitation-Augmented Language Models
[Natural Language Methods of Inductive Reasoners] Language Models as Inductive Reasoners
[GPT-3 is used for data annotation (such as emotional classification)] Is GPT-3 a Good Data Annotator?
【Models for Data Augmentation based on multitasking training for less sample data augmentation】KnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Low-Resource NLP
【Procedural planning work, not interested in the time being】Neuro-Symbolic Procedural Planning with Commonsense Prompting
[Objective: Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus
【Combining the results of the external physics simulator in the context】Mind's Eye: Grounded Language Model Reasoning through Simulation
[Retrieve the task of enhancing CoT to do knowledge Intensive] Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
【Contrast the potential (binary) knowledge in unsupervised recognition language model】Discovering Latent Knowledge in Language Models Without Supervision
[Percy Liang group, trusted search engine, only 51.5% of generated sentences are fully supported by citations] Evaluating Verifiability in Generative Search Engines
Progressive-Hint Prompting Improves Reasoning in Large Language Models
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
[In my opinion, it is one of the most important articles. The law of proportion of language models under cross entropy loss, the loss is a power-law relationship with the model size, the dataset size, the amount of the computation used for training, and the width and depth of the architecture details such as the width and depth. Scaling Laws for Neural Language Models
[One of the other most important articles, Chinchilla, under limited computing, the optimal model is not the largest model, but a smaller model trained with more data (60-70B)] Training Compute-Optimal Large Language Models
[Which architecture and optimization goals help zero-sample generalization] What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
【Grokking “Epiphany” learning process Memorization->Circuit formation->Cleanup】Progress measures for grokking via mechanistic interpretation
[Investigate the characteristics of the search-based model and find that both are of limited reasoning] Can Retriever-Augmented Language Models Reason? The Blame Game Between the Retriever and the Language Model
[Human-AI Language Interaction Evaluation Framework] Evaluating Human-Language Model Interaction
What learning algorithm is in-context learning? Investigations with linear models
【Model editing, this is Hot topic】Mass-Editing Memory in a Transformer
[The model's sensitivity to irrelevant context, adding irrelevant information to the examples in the prompt and adding instructions that ignore irrelevant context partially resolve] Large Language Models Can Be Easily Distracted by Irrelevant Context
【zero-shot CoT will show bias and toxicity under sensitive issues】 On Second Thought, Let's Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning
【CoT of the big model has cross-language capabilities】 Language models are multilingual chain-of-thought reasons
[The lower the confusion of different Prompt sequences, the better the performance] Demystifying Prompts in Language Models via Perplexity Estimation
[Binary implicity resolution task of large models, this suggestion is difficult and there is no scaling phenomenon] Large language models are not zero-shot communicators (https://github.com/google/BIG-bench/tree/main/bigbench/benchmark_tasks/ Implicity)
【Complexity-Based Prompting for Multi-step Reasoning
What Matters In The Structured Pruning of Generative Language Models?
[AmbiBench dataset, Task Ambiguity: The scaling RLHF model performs best in disambiguating tasks. Fine-tuning is more helpful than few-shot prompting】Task Ambiguity in Humans and Language Models
【GPT-3 test, including memory, calibration, bias, etc.】Prompting GPT-3 To Be Reliable
[OSU study which part of CoT is effective for performance] Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
[Research on cross-language model of discrete prompts] Can discrete information extraction prompts generalize across language models?
【The memory rate is logarithmic linear relationship with the model size, prefix length and repetition rate in training】 Quantifying Memorization Across Neural Language Models
【It's very inspiring, decompose the problem into sub-questions through GPT iteration and answer it】Measuring and Narrowing the Compositionality Gap in Language Models
[Analogous test of GPT-3 similar to civil servants’ intelligence questions] Emergent Analogical Reasoning in Large Language Models
【Short text training, long text testing, evaluation of model variable length adaptability】A Length-Extrapolatable Transformer
[When not to Trust Language Models: Investigating Effectiveness and Limitations of Parametric and Non-Parametric Memories
【ICL is another form of gradient update】Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta Optimizers
Is GPT-3 a Psychopath? Evaluating Large Language Models from a Psychological Perspective
[Research on the process of training the OPT model in different sizes, and found that confusion is an indicator of ICL] Training Trajectories of Language Models Across Scales
[EMNLP 2022, Pre-trained pure English corpus contains other languages, and the model's cross-language capabilities may come from data leakage] Language Contamination Helps Explains the Cross-lingual Capabilities of English Pretrained Models
[Overriding semantic priors and using information in propt is a surge capability] Larger language models do in-context learning differently
【EMNLP 2022 findings】What Language Model to Train if You Have One Million GPU Hours?
[Introducing CFG technology during reasoning greatly improves the instruction compliance ability of small models] Stay on topic with Classifier-Free Guidance
【Train your own LLaMA model with openai’s GPT-4, and I can only say I admire you】Instruction Tuning with GPT-4
Reflexion: an autonomous agent with dynamic memory and self-reflection
【Personalized style prompt learning, OPT】Extensible Prompts for Language Models
[Accelerating large model decoding, using the direct consensus between small models and large models to be used multiple times at a time, after all, the input will be very slow if it is long] Accelerating Large Language Model Decoding with Specialized Sampling
[Use soft prompt to reduce the decline in ICL capability caused by fine tuning, fine-tuning the first stage, fine-tuning the second stage] Preserving In-Context Learning ability in Large Language Model Fine-tuning
【Semantic parsing tasks, sample selection methods of ICL, CODEX and T5-large】Diverse Demonstrations Improve In-context Compositional Generalization
【A new optimization method for text generation】Tailoring Language Generation Models under Total Variation Distance
[Uncertainty estimation of conditional generation, using semantic clustering combined with multiple sampling outputs to estimate the entropy of clusters] Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Go-tuning: Improving Zero-shot Learning Abilitys of Smaller Language Models
[Very inspiring, text generation method under free text constraints] Controllable Text Generation with Language Constraints
[When generating predictions, use similarity to select phrase instead of softmax token] Nonparametric Masked Language Modeling
[ICL method for long text] Parallel Context Windows Improve In-Context Learning of Large Language Models
【Sample of InstructGPT model generating ICL by itself】 Self-Prompting Large Language Models for Open-Domain QA
【Transfer and attention mechanisms enable ICL to enter more annotation samples】Structured Prompting: Scaling In-Context Learning to 1,000 Examples
Momentum Calibration for Text Generation
【Two ICL sample selection methods, experiments based on OPT and GPTJ】Careful Data Curation Stabilizes In-context Learning
【Analysis of the evaluation indicators of Mauve (pillutla et al.)】On the Usefulness of Embeddings, Clusters and Strings for Text Generation Evaluation
Promptagator: Few-shot Dense Retrieval From 8 Examples
[Three cobblers, Zhuge Liang] Self-Consistency Improves Chain of Thought Reasoning in Language Models
[Invert, input and label generate instructions for conditions] Guess the Instruction! Making Language Models Stronger Zero-Shot Learners
【LLM’s reverse derivation self-verification】 Large Language Models are reasons with Self-Verification
【Methods for searching - Safety scenarios under the process of generating evidence】Foveate, Attribute, and Rationalize: Towards Safe and Trustworthy AI
[Confidence estimation of fragments extracted by text-generated information based on beam search] How Does Beam Search improve Span-Level Confidence Estimation in Generative Sequence Labeling?
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
【A Discussion on Extracted Summary Gold Label】Text Summarization with Oracle Expectation
【OOD detection method based on Martian distance】Out-of-Distribution Detection and Selective Generation for Conditional Language Models
[Attention module integrates Prompt to predict sample level] Model ensemble instead of prompt fusion: a sample-specific knowledge transfer method for few-shot prompt tuning
【Prompt for multiple tasks by decomposition and distillation into one Prompt】Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
[The evaluation indicators of step-by-step reasoning generated text can be used as the topic to share next time] ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
[Calibrating Sequence likelihood Improves Conditional Language Generation]
【Text attack method based on gradient optimization】TextGrad: Advancing Robustness Evaluation in NLP by Gradient-Driven Optimization
[GMM modeling ICL decision classification boundaries to calibrate] Prototypical Calibration for Few-shot Learning of Language Models
【Rewriting problem, and graph-based ICL aggregation method】Ask Me Anything: A simple strategy for prompting language models
[Database for selecting good candidates as ICLs from unannotated example pools] Selective Annotation Makes Language Models Better Few-Shot Learners
PromptBoosting: Black-Box Text Classification with Ten Forward Passes
Attention-Guided Backdoor Attacks against Transformers
【Prompt Mask position automatic label selection】Pre-trained Language Models can be Fully Zero-Shot Learners
[Compress the length of the FiD input vector and reorder it when outputting to output document ranking] FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
【Explanation on the generation of large models】PINTO: Faithful Language Reasoning Using Prompted-Generated Rationales
【Find a subset of pre-training impacts】ORCA: Interpreting Prompted Language Models via Location Supporting Evidence in the Ocean of Pretraining Data
[Prompt project, aimed at Instruction, generates first stage and two stage sorting filtering] Large Language Models are Human-Level Prompt Engineers
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Editing models with task arithmetic
[Don't enter instructions and samples every time, convert them into parameter-efficient modules,] HINT: Hypernetwork Instruction Tuning for Efficient Zero-Shot Generalisation
[ICL display generation method without manual sample selection] Z-ICL: Zero-Shot In-Context Learning with Pseudo-Demonstrations
[Task Instruction and text generate Embedding together]One Embedder, Any Task: Instruction-Finetuned Text Embeddings
【Big model teaching small model CoT】KNIFE: Knowledge Distillation with Free-Text Rationales
[Problem of inconsistency between source and target word segmentation of information extraction generation model] Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Parsel: A Unified Natural Language Framework for Algorithmic Reasoning
[ICL sample selection, first phase selection and second phase sorting] Self-adaptive In-context Learning
[Intensive reading, readable prompt unsupervised selection method, GPT-2] Toward Human Readable Prompt Tuning: Kubrick's The Shining is a good movie, and a good prompt too
【PRONTOQA dataset tests CoT inference ability and finds that Planning ability is still limited】 Language Models Can (kind of) Reason: A Systematic Formal Analysis of Chain-of-Thought
【reasoning dataset】WikiWhy: Answering and Explaining Cause-and-Effect Questions
【reasoning dataset】STREET: A MULTI-TASK STRUCTURED REASONING AND EXPLANATION BENCHMARK
【Reasoning dataset, comparing OPT pre-training and fine-tuning, including CoT fine-tuning models】 ALERT: Adapting Language Models to Reasoning Tasks
[Summary of the recent reasoning by Zhang Ningyu team of Zhejiang University] Reasoning with Language Model Prompting: A Survey
[Summary of text generation technology and direction by Xiao Yanghua's team in Fudan] Harnessing Knowledge and Reasoning for Human-Like Natural Language Generation: A Brief Review
[Summary of recent reasoning articles, Jie Huang from UIUC] Towards Reasoning in Large Language Models: A Survey
【Review of tasks, datasets and methods of mathematical reasoning and DL】A Survey of Deep Learning for Mathematical Reasoning
A Survey on Natural Language Processing for Programming
Reward modeling dataset:
Red-teaming datasets, harmless vs. helpful, RLHF + scale is harder to attack (another effective technique is CoT fine-tuning):
【Knowledge】+【Inference】+【Generate】
If it is helpful to you, please support it. Welcome to Pull Request~
Subjectively organized, the time mainly starts from the ICLR 2023 Rebuttal period, including preprint papers such as ICLR, ACL, ICML, etc.
Please correct any inappropriate points or suggestions! Dongfang Li, [email protected]


