JARVIS ChatGPT
1.0.0
A voice-based interactive assistant equipped with a variety of synthetic voices (including J.A.R.V.I.S's voice from IronMan)
 image by MidJourney AI
image by MidJourney AI
Ever dreamed to ask hyper-intelligent system tips to improve your armor? Now you can! Well, maybe not the armor part... This project exploits OpenAI Whisper, OpenAI ChatGPT and IBM Watson.
PROJECT MOTIVATION:
Many times ideas come in the worst moment and they fade away before you have the time to explore them better. The objective of this project is to develop a system capable of giving tips and opinions in quasi-real-time about anything you ask. The ultimate assistant will be able to be accessed from any authorized microphone inside your house or your phone, it should run constantly in the background and when summoned should be able to generate meaningful answers (with a badass voice) as well as interface with the pc or a server and save/read/write files that can be accessed later. It should be able to run research, gather material from the internet (extract content from HTML pages, transcribe Youtube videos, find scientific papers...) and provide summaries that can be used as context to make informed decisions. In addition, it might interface with some external gadgets (IoT) but that's extra.
DEMO:
I can finnaly share the first draft of the Research Mode. This modality was thought for people often dealing with research papers.
PS: This mode is not super stable and needs to be worked on
PPS: This project will be discontinued for some time since I'll be working on my thesis until 2024. However there are already so many things that can be improved so I'll be back!
DISCLAIMER:
The project might consume your OpenAI credit resulting in undesired billing;
I don't take responsibility for any unwanted charges;
Consider setting limitations on credit consumption at your OpenAI account;
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117);you can rely on the new
setup.batthat will do most of the things for you.
MAIN script you should run: openai_api_chatbot.py if you want to use the latest version of the OpenAI API Inside the demos folder you'll find some guidance for the packages used in the project, if you have errors you might check these files first to target the problem. Mostly is stored in the Assistant folder: get_audio.py stores all the functions to handle mic interactions, tools.py implements some basic aspects of the Virtual Assistant, voice.py describes a (very) rough Voice class. Agents.py handle the LangChain part of the system (here you can add or remove tools from the toolkits of the agents)
The remaining scripts are supplementary to the voice generation and should not be edited.
You can run setup.bat if you are running on Windows/Linux. The script will perform every step of the manual installation in sequence. Refer to those in case the procedure should fail.
The automatic installation will also run the Vicuna installation (Vicuna Installation Guide)
pip install -r venv_requirements.txt; This might take some time; if you encounter conflicts on specific packages, install them manually without the ==<version>;whisper_edits to the whisper folder of your environment (.venvlibsite-packageswhisper ) these edits will add just an attribute to the whisper model to access its dimension more easily; demos/tts_demo.py);
cd Vicuna
call vicuna.ps1
env.txt file and rename it to .env (yes, remove the txt extension)torch.cuda.is_available() and torch.cuda.get_device_name(0) inside Pyhton; .tests.py. This file attempt to perform basic operations that might raise errors;VirtualAssistant.__init__() ;
__main__() at whisper_model = whisper.load_model("large"); but I hope your GPU memory is large likewise.openai_api_chatbot.py):When running, you'll see much information being displayed. I'm constantly striving to improve the readability of the execution, the whole project is a huge beta, forgive slight variations from the screens below. Anyway, this is what happens in general terms when you hit 'run':
Jarvis to summon the assistant. At this point, a conversation will begin and you can speak in whatever language you want (if you followed step 2). The conversation will terminate when you 1) say a stop word 2) say something with one word (like 'ok') 3) when you stop making questions for more than 30 seconds
chat_history with your question, it will send a request with the API and it will update the history as soon as it receives a full answer from ChatGPT (this may take up to 5-10 seconds, consider explicitly asking for a short answer if you are in a hurry);say() function will perform voice duplication to speak with Jarvis/Someone's voice; if the argument is not in English, IBM Watson will send the response from one of their nice text-to-speech models. If everything fails, the functions will rely on pyttsx3 which is a fast yet not as cool alternative;
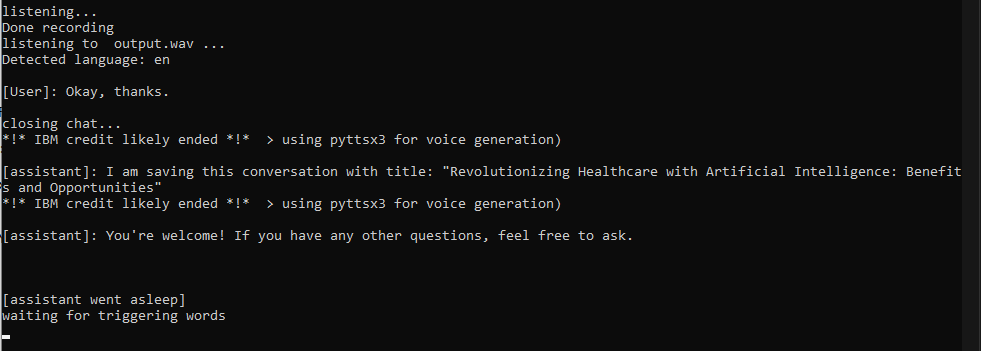
I made some prompts and closed the conversation
not ideal I know but works for now
VirtualAssistant class with memory and local storage accesscurrently working on:
following:
Check the UpdateHistory.md of the project for more insights.
Have fun!
categories: Install, General, Runtime
The problem is concerning Whisper. You should re-install it manually with pip install whisper-openai
pip install --upgrade openai.Requirements are not updated every commit. While this might generate errors you can quickly install the missing modules, at the same time it keeps the environment clean from conflicts when I try new packages (and I try LOTS of them)
It means the model you selected is too big for your CUDA device memory. Unfortunately, there is not much you can do about it except load a smaller model. If the smaller model does not satisfy you, you might want to speak 'clearer' or make longer prompts to let the model predict more accurately what you are saying. This sounds inconvenient but, in my case, greatly improved my English-speaking :)
This is a bug still present, don't expect to have ever long conversations with your assistant as it will simply have enough memory to remember the whole conversation at some point. A fix is in development, it might consist of adopting a 'sliding windows' approach even if it might cause repetition of some concepts.
Right now (April 2023) I'm working almost non-stop on this. I will likely take a break in the summer because I'll be working on my thesis.
If you have questions you can contact me by raising an Issue and I'll do my best to help as soon as possible.
Gianmarco Guarnier


