Ecosistema de capa media de base de datos distribuida Apache ShardingSphere v5.5.0
5.5.0
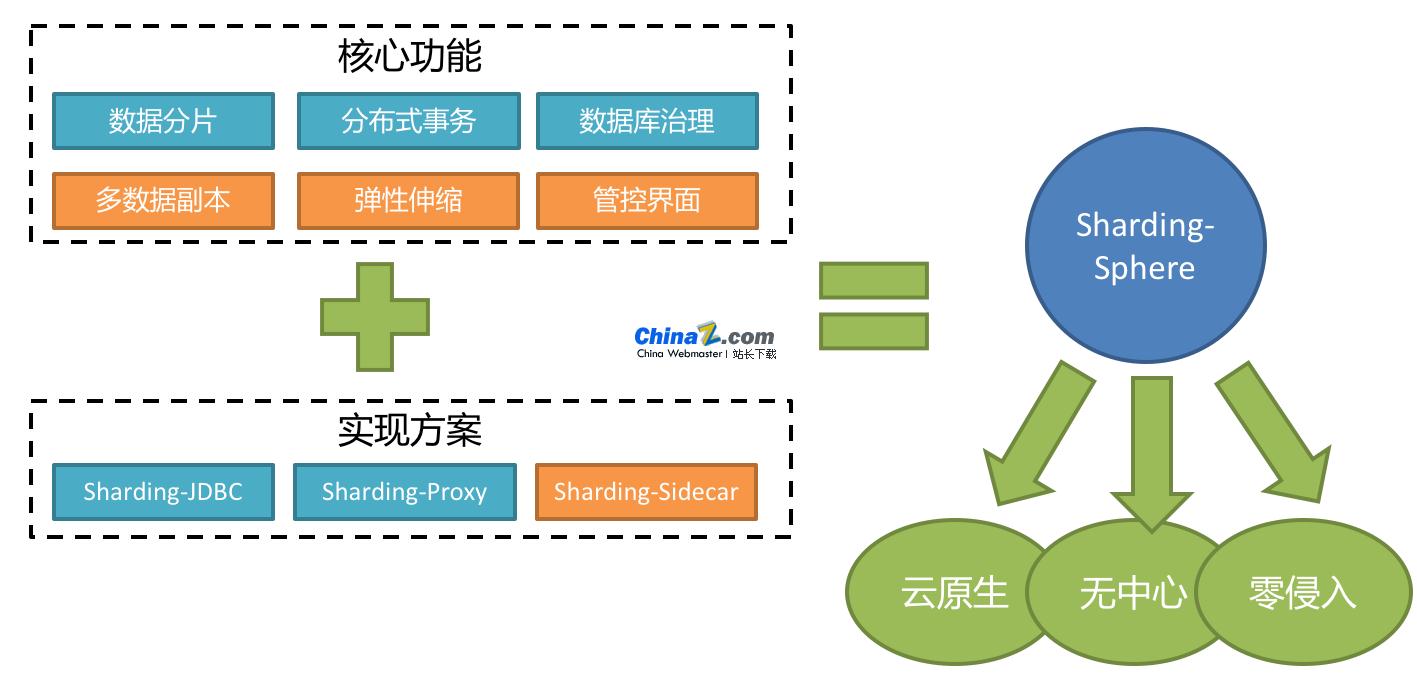
Apache ShardingSphere es un ecosistema compuesto por un conjunto de soluciones de middleware de bases de datos distribuidas de código abierto. Consta de JDBC, Proxy y Sidecar (en planificación), tres productos que son independientes entre sí pero que se pueden implementar y utilizar juntos. Todos proporcionan fragmentación de datos estandarizada, transacciones distribuidas y funciones de administración de bases de datos, y se pueden aplicar a varios escenarios de aplicaciones diversos, como isomorfismo de Java, lenguajes heterogéneos, nativos de la nube, etc.
Apache ShardingSphere se posiciona como middleware de bases de datos relacionales, con el objetivo de utilizar completa y razonablemente las capacidades informáticas y de almacenamiento de las bases de datos relacionales en escenarios distribuidos, en lugar de implementar una nueva base de datos relacional. Capta la esencia de las cosas centrándose en lo inmutable. Las bases de datos relacionales todavía ocupan un mercado enorme en la actualidad y son la piedra angular del negocio principal de cada empresa. Será difícil deshacerse de ellas en el futuro. En esta etapa, nos centramos más en los incrementos basados en la base original que en la subversión.
Apache ShardingSphere 5.x comenzó a centrarse en la arquitectura conectable y los componentes funcionales del proyecto se pueden expandir de manera flexible de manera conectable. Actualmente, funciones como fragmentación de datos, separación de lectura y escritura, copias múltiples de datos, cifrado de datos y pruebas de estrés de bases de datos ocultas, así como soporte para SQL y protocolos como MySQL, PostgreSQL, SQLServer y Oracle, están todas integradas en el proyecto a través de complementos. Los desarrolladores pueden personalizar su propio sistema único como si usaran bloques de construcción. Apache ShardingSphere actualmente proporciona docenas de SPI como puntos de extensión del sistema y aún se están agregando más.
ShardingSphere-JDBC
Posicionado como un marco Java liviano, proporciona servicios adicionales en la capa JDBC de Java. Utiliza el cliente para conectarse directamente a la base de datos y proporciona servicios en forma de paquetes jar sin implementación ni dependencias adicionales. Puede entenderse como una versión mejorada del controlador JDBC y es totalmente compatible con JDBC y varios marcos ORM.
Aplicable a cualquier marco ORM basado en JDBC, como: JPA, Hibernate, Mybatis, Spring JDBC Template o use JDBC directamente.
Admite cualquier grupo de conexiones de bases de datos de terceros, como: DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
Soporta cualquier base de datos que implemente la especificación JDBC. Actualmente, soporta MySQL, Oracle, SQLServer, PostgreSQL y cualquier base de datos que siga el estándar SQL92.
ShardingSphere-Proxy
Posicionado como un agente de base de datos transparente, proporciona un servidor que encapsula el protocolo binario de la base de datos para admitir lenguajes heterogéneos. Actualmente, se proporcionan MySQL y PostgreSQL. Puede utilizar cualquier cliente de acceso compatible con el protocolo MySQL/PostgreSQL (como MySQL Command Client, MySQL Workbench, Navicat, etc.) para operar datos, lo que los hace más amigables para los DBA.
Es completamente transparente para la aplicación y se puede utilizar directamente como servidor MySQL/PostgreSQL.
Aplicable a cualquier cliente compatible con el protocolo MySQL/PostgreSQL.
ShardingSphere-Sidecar (TODO)
Posicionado como un proxy de base de datos nativo de la nube para Kubernetes, representa todo el acceso a la base de datos en forma de Sidecar. Una solución sin centros y sin intrusiones proporciona una capa de participación que interactúa con la base de datos, a saber, Database Mesh, también conocida como cuadrícula de base de datos.
El objetivo de Database Mesh es cómo conectar orgánicamente aplicaciones y bases de datos de acceso a datos distribuidos. Se centra más en la interacción y en la clasificación eficaz de las interacciones entre aplicaciones y bases de datos desordenadas. Al utilizar Database Mesh, las aplicaciones y bases de datos que acceden a la base de datos eventualmente formarán un enorme sistema de cuadrícula. Las aplicaciones y bases de datos solo necesitan registrarse en el sistema de cuadrícula. Todos son objetos administrados por la capa de malla.
arquitectura híbrida
ShardingSphere-JDBC adopta una arquitectura descentralizada y es adecuado para aplicaciones OLTP livianas de alto rendimiento desarrolladas en Java; ShardingSphere-Proxy proporciona entrada estática y soporte de lenguaje heterogéneo y es adecuado para aplicaciones OLAP y gestión y operación de bases de datos fragmentadas.
Apache ShardingSphere es un ecosistema compuesto por múltiples terminales de acceso. Al combinar ShardingSphere-JDBC y ShardingSphere-Proxy, y utilizar el mismo centro de registro para configurar de manera uniforme estrategias de fragmentación, se pueden construir de manera flexible sistemas de aplicaciones adecuados para diversos escenarios, lo que permite a los arquitectos ajustar más libremente el mejor sistema para la arquitectura actual.
1. Fragmentación de datos
Subbiblioteca y subtabla
Separación de lectura y escritura.
Personalización de la estrategia de fragmentación
Clave primaria distribuida no centralizada
2. Transacciones distribuidas
Interfaz de transacción estandarizada
Transacciones XA fuertemente consistentes
Asuntos flexibles
3. Gestión de bases de datos
Gobernanza distribuida
Escalado elástico
Observabilidad (seguimiento distribuido, métricas)
Cifrado y descifrado de datos
Prueba de presión manométrica en sombra