Versión oficial del almacén de datos analíticos Apache Kylin v4.0.3
4.0.3
Apache Kylin: una herramienta de consulta en menos de un segundo para datos de escala extremadamente grande
Editor de códigos descendentes
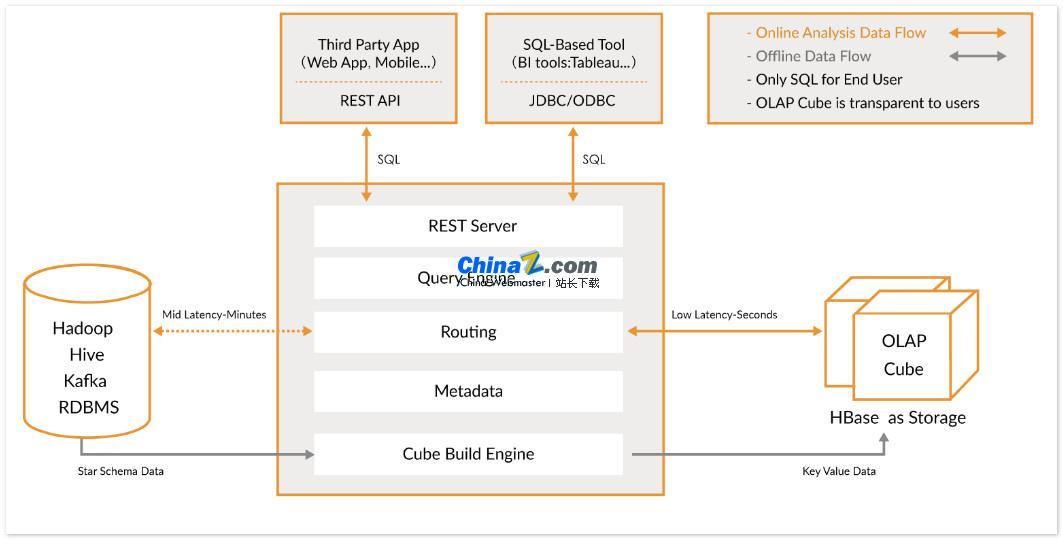
Apache Kylin es un almacén de datos analíticos distribuidos de código abierto que proporciona una interfaz de consulta SQL y capacidades de análisis multidimensional (OLAP) además de Hadoop/Spark, y puede procesar de manera eficiente datos a escala extremadamente grande. Desarrollado originalmente por eBay y contribuido a la comunidad de código abierto, completa consultas sobre datos masivos en menos de segundos.
Los tres pasos principales de Kylin
Kylin permite a los usuarios implementar consultas de menos de un segundo en conjuntos de datos muy grandes en solo tres pasos:
1. Defina un modelo de estrella o copo de nieve en su conjunto de datos: Primero, debe definir un modelo de estrella o copo de nieve para describir su conjunto de datos. Esto ayudará a Kylin a comprender la relación entre los datos y así optimizar el rendimiento de las consultas.
2. Build Cube: Build Cube en la tabla de datos definida es la unidad para que Kylin precalcule y almacene datos, lo que puede mejorar en gran medida la velocidad de consulta.
3. Utilice una consulta SQL estándar: utilice la sintaxis SQL estándar para consultar Cube a través de ODBC, JDBC o API RESTFUL. Kylin puede devolver los resultados de la consulta en menos de segundos.
Capacidades de integración de Kylin
Kylin se integra con una variedad de herramientas de visualización de datos, como Tableau, Power BI, etc. Los usuarios pueden utilizar estas herramientas de BI para analizar datos de Hadoop y mostrar visualmente información valiosa sobre los datos.
Resumir
Apache Kylin es una poderosa herramienta que puede ayudar a los usuarios a completar consultas sobre datos de gran escala en menos de segundos. Su facilidad de uso, escalabilidad y eficiencia lo hacen ideal para manejar análisis de datos a gran escala.