bitnet.cpp es el marco de inferencia oficial para LLM de 1 bit (por ejemplo, BitNet b1.58). Ofrece un conjunto de núcleos optimizados que admiten una inferencia rápida y sin pérdidas de modelos de 1,58 bits en la CPU (con soporte para NPU y GPU a continuación).
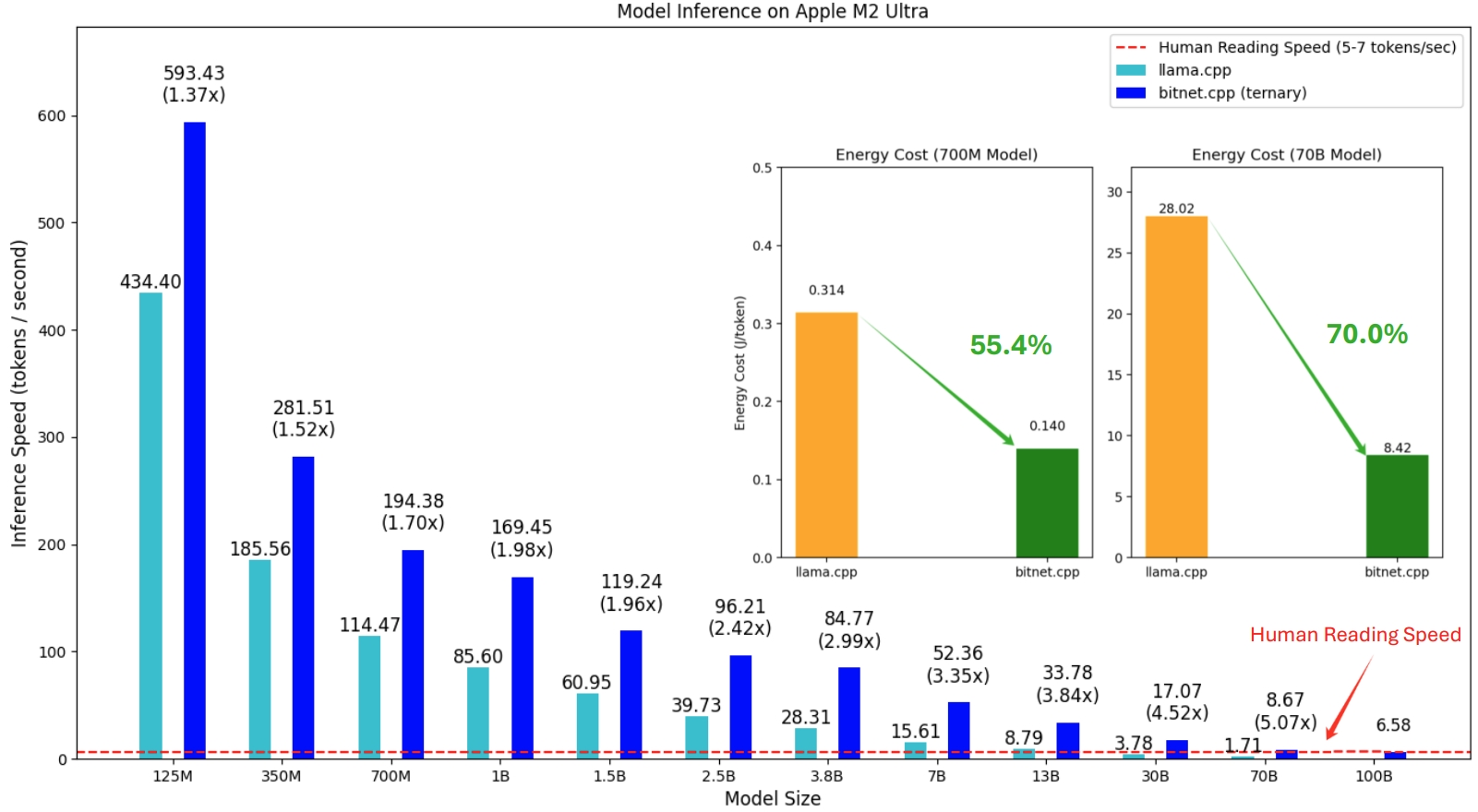
La primera versión de bitnet.cpp es para admitir la inferencia en las CPU. bitnet.cpp logra aceleraciones de 1,37x a 5,07x en CPU ARM, y los modelos más grandes experimentan mayores ganancias de rendimiento. Además, reduce el consumo de energía entre un 55,4% y un 70,0% , lo que aumenta aún más la eficiencia general. En las CPU x86, las aceleraciones oscilan entre 2,37x y 6,17x con reducciones de energía entre el 71,9% y el 82,2% . Además, bitnet.cpp puede ejecutar un modelo BitNet b1.58 de 100 B en una sola CPU, logrando velocidades comparables a la lectura humana (5-7 tokens por segundo), lo que mejora significativamente el potencial para ejecutar LLM en dispositivos locales. Consulte el informe técnico para obtener más detalles.


Los modelos probados son configuraciones ficticias utilizadas en un contexto de investigación para demostrar el rendimiento de inferencia de bitnet.cpp.
Una demostración de bitnet.cpp ejecutando un modelo BitNet b1.58 3B en Apple M2:
21/10/2024 Infraestructura AI de 1 bit: Parte 1.1, Inferencia BitNet b1.58 rápida y sin pérdidas en CPU
17/10/2024 Se lanzó bitnet.cpp 1.0.
21/03/2024 Preguntas frecuentes sobre el código de consejos de capacitación de la era de los LLM de 1 bit
27/02/2024 La era de los LLM de 1 bit: todos los modelos de lenguajes grandes están en 1,58 bits
17/10/2023 BitNet: Escalado de transformadores de 1 bit para modelos de lenguaje grandes
Este proyecto se basa en el marco llama.cpp. Nos gustaría agradecer a todos los autores por sus contribuciones a la comunidad de código abierto. Además, los núcleos de bitnet.cpp se basan en las metodologías de tablas de búsqueda pioneras en T-MAC. Para inferir LLM generales de bits bajos más allá de los modelos ternarios, recomendamos utilizar T-MAC.
❗️ Usamos LLM de 1 bit existentes disponibles en Hugging Face para demostrar las capacidades de inferencia de bitnet.cpp. Microsoft no entrena ni publica estos modelos. Esperamos que el lanzamiento de bitnet.cpp inspire el desarrollo de LLM de 1 bit en entornos a gran escala en términos de tamaño del modelo y tokens de entrenamiento.
| Modelo | Parámetros | UPC | Núcleo | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-grande | 0,7 mil millones | x86 | ✔ | ✘ | ✔ |
| BRAZO | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| BRAZO | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-tokens | 8.0B | x86 | ✔ | ✘ | ✔ |
| BRAZO | ✔ | ✔ | ✘ | ||
pitón>=3.9
cmhacer>=3.22
sonido metálico>=18
Desarrollo de escritorio con C++
Herramientas C++-CMake para Windows
Git para Windows
Compilador C++-Clang para Windows
Soporte de MS-Build para LLVM-Toolset (clang)
Para usuarios de Windows, instale Visual Studio 2022. En el instalador, active al menos las siguientes opciones (esto también instala automáticamente las herramientas adicionales necesarias, como CMake):
Para usuarios de Debian/Ubuntu, puede descargar con el script de instalación automática
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (muy recomendable)
Importante
Si está utilizando Windows, recuerde utilizar siempre un símbolo del sistema para desarrolladores/PowerShell para VS2022 para los siguientes comandos
Clonar el repositorio
clon de git --recursivo https://github.com/microsoft/BitNet.gitcd BitNet
Instalar las dependencias
# (Recomendado) Crear un nuevo entorno condaconda create -n bitnet-cpp python=3.9 conda activar bitnet-cpp instalación de pip -r requisitos.txt
construir el proyecto
# Descargue el modelo de Hugging Face, conviértalo al formato gguf cuantificado y cree el proyectopython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# O puede descargar manualmente el modelo y ejecutar con pathhuggingface-cli local descargar HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md modelos/Llama3-8B-1.58-100B-tokens -q i2_s
uso: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--use-preajustado]
Configurar el entorno para ejecutar la inferencia
argumentos opcionales:
-h, --help muestra este mensaje de ayuda y sale
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-tokens}
Modelo utilizado para la inferencia.
--model-dir MODEL_DIR, -md MODEL_DIR
Directorio para guardar/cargar el modelo
--log-dir LOG_DIR, -ld LOG_DIR
Directorio para guardar la información de registro
--tipo-cuantitativo {i2_s,tl1}, -q {i2_s,tl1}
Tipo de cuantificación
--quant-embd Cuantiza las incrustaciones a f16
--use-pretuned, -p Usa los parámetros del kernel preajustados# Ejecutar inferencia con el modelo cuantificadopython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel regresó al jardín. Mary viajó a la cocina. Sandra Viajó a la cocina. Sandra fue al pasillo. John fue al dormitorio. Mary regresó al jardín. Mary viajó a la cocina. Sandra se dirigió a la cocina. Sandra salió al pasillo. John fue al dormitorio. María volvió al jardín. ¿Dónde está María?# Respuesta: María está en el jardín.
uso: run_inference.py [-h] [-m MODELO] [-n N_PREDICT] -p PROMPT [-t HILOS] [-c CTX_SIZE] [-temp TEMPERATURA]
Ejecutar inferencia
argumentos opcionales:
-h, --help muestra este mensaje de ayuda y sale
-m MODELO, --modelo MODELO
Ruta al archivo de modelo
-n N_PREDICT, --n-predecir N_PREDICT
Número de tokens a predecir al generar texto
-p INDICACIÓN, --prompt INDICACIÓN
Solicitud para generar texto desde
-t HILOS, --hilos HILOS
Número de hilos a utilizar
-c CTX_TAMAÑO, --ctx-tamaño CTX_TAMAÑO
Tamaño del contexto del mensaje
-temp TEMPERATURA, --temperatura TEMPERATURA
Temperatura, un hiperparámetro que controla la aleatoriedad del texto generadoProporcionamos scripts para ejecutar el punto de referencia de inferencia proporcionando un modelo.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
Aquí hay una breve explicación de cada argumento:
-m , --model : la ruta al archivo del modelo. Este es un argumento obligatorio que se debe proporcionar al ejecutar el script.
-n , --n-token : la cantidad de tokens que se generarán durante la inferencia. Es un argumento opcional con un valor predeterminado de 128.
-p , --n-prompt : la cantidad de tokens de aviso que se usarán para generar texto. Este es un argumento opcional con un valor predeterminado de 512.
-t , --threads : el número de subprocesos que se utilizarán para ejecutar la inferencia. Es un argumento opcional con un valor predeterminado de 2.
-h , --help : muestra el mensaje de ayuda y sale. Utilice este argumento para mostrar información de uso.
Por ejemplo:
python utils/e2e_benchmark.py -m /ruta/al/modelo -n 200 -p 256 -t 4
Este comando ejecutaría el punto de referencia de inferencia utilizando el modelo ubicado en /path/to/model , generando 200 tokens a partir de un mensaje de 256 tokens, utilizando 4 subprocesos.
Para el diseño del modelo que no es compatible con ningún modelo público, proporcionamos scripts para generar un modelo ficticio con el diseño del modelo dado y ejecutar la prueba comparativa en su máquina:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Ejecute el punto de referencia con el modelo generado, use -m para especificar la ruta del modelo, -p para especificar el mensaje procesado, -n para especificar el número de tokens para generarpython utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128