SonicSim
Speech

Kai Li 1 , Wendi Sang 1 , Chang Zeng 2 , Runxuan Yang 1 , Guo Chen 1 , Xiaolin Hu 1
1 Universidad de Tsinghua, China
2 Instituto Nacional de Informática, Japón
Papel | Manifestación
Presentamos SonicSim, un conjunto de herramientas sintético diseñado para generar datos altamente personalizables para fuentes de sonido en movimiento. SonicSim se desarrolla sobre la base de la plataforma de simulación de IA incorporada, Habitat-sim, y admite ajustes de parámetros de múltiples niveles, incluidos nivel de escena, nivel de micrófono y nivel de fuente, generando así datos sintéticos más diversos. Aprovechando SonicSim, construimos un conjunto de datos de referencia de fuentes de sonido en movimiento, SonicSet, utilizando el conjunto de datos LibriSpeech, Freesound Dataset 50k (FSD50K) y Free Music Archive (FMA), y 90 escenas de Matterport3D para evaluar los modelos de mejora y separación del habla.
[2024-10-30] Corregimos los errores para instalar el entorno y actualizamos el código de entrenamiento para los modelos de mejora y separación de voz en el conjunto de datos de SonicSet.
[2024-10-23] Publicamos el training code para los modelos de mejora y separación del habla en el conjunto de datos SonicSet.
[2024-10-03] Publicamos el artículo en arxiv
[2024-10-01] Publicamos el conjunto de datos de separación de voz en el mundo real, cuyo objetivo es evaluar el rendimiento de los modelos de separación de voz en escenarios del mundo real.
[2024-07-31] Lanzamos el SonicSim dataset , que incluye tareas de mejora y separación del habla.
[2024-07-24] Publicamos los scripts para dataset construction y los modelos previamente entrenados para speech separation and enhancement .

Importación de escenas 3D: admite la importación de una variedad de activos 3D desde conjuntos de datos como Matterport3D, lo que permite una generación eficiente y escalable de entornos acústicos complejos.
Simulación de entorno acústico:
Simula reflejos de sonido dentro de la geometría de la habitación utilizando modelado acústico interior y algoritmos de seguimiento de trayectoria bidireccional.
Asigna etiquetas semánticas de escenas 3D a propiedades de materiales, estableciendo los coeficientes de absorción, dispersión y transmisión de las superficies.
Sintetiza datos de fuentes de sonido en movimiento en función de las rutas de origen, lo que garantiza una alta fidelidad a las condiciones del mundo real.
Configuraciones de micrófono: ofrece una amplia gama de configuraciones de micrófono, incluidas mono, binaural y Ambisonics, además de compatibilidad con conjuntos de micrófonos lineales y circulares personalizados.
Posicionamiento de fuente y micrófono: proporciona personalización o aleatorización de las posiciones de la fuente de sonido y el micrófono. Admite trayectorias de movimiento para simulaciones de fuentes de sonido en movimiento, agregando realismo a escenarios acústicos dinámicos.

Puede descargar el conjunto de datos preconstruido desde el siguiente enlace:
| Nombre del conjunto de datos | Onedrive | Disco Baidu |
|---|---|---|
| carpeta de tren (40 archivos rar divididos, 377G) | [Enlace de descarga] | [Enlace de descarga] |
| val.rar (4.9G) | [Enlace de descarga] | [Enlace de descarga] |
| prueba.rar (2.2G) | [Enlace de descarga] | [Enlace de descarga] |
| datos de referencia de septiembre (8,57G) | [Enlace de descarga] | [Enlace de descarga] |
| datos de referencia enh (7,70G) | [Enlace de descarga] | [Enlace de descarga] |
| Nombre del conjunto de datos | Onedrive | Disco Baidu |
|---|---|---|
| Conjunto de datos del mundo real (1,0G) | [Enlace de descarga] | [Enlace de descarga] |
Conjunto de datos RealMAN: RealMAN


Para construir el conjunto de datos usted mismo, consulte el archivo README en la carpeta SonicSim-SonicSet/data-script . Este documento proporciona instrucciones detalladas sobre cómo utilizar los scripts proporcionados para generar el conjunto de datos.
Para configurar el entorno para entrenamiento e inferencia, utilice el archivo YAML proporcionado:
conda crear -n SonicSim-Train python = 3.10 conda activar SonicSim-Train instalación de pip Cython==3.0.10 numpy==1.26.4 pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118 instalación de pip -r requisitos.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
Navegue hasta el directorio separation y ejecute el siguiente script para generar el conjunto de validación fijo:
separación de cd python generate_fixed_validation.py --raw_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val --save_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val-sep-2 --is_mono python generate_fixed_test.py --raw_dir=/home/pod/SonicSim/SonicSim/SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/test --is_mono
Navegue hasta el directorio enhancement y ejecute el siguiente script para generar el conjunto de validación fijo:
mejora de cd python generate_fixed_validation.py --raw_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val --save_dir=../SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/val-enh-noise --is_mono python generate_fixed_test.py --raw_dir=/home/pod/SonicSim/SonicSim/SonicSim-SonicSet/SonicSet/scene_datasets/mp3d/test --is_mono
Navegue hasta el directorio separation y ejecute el script de entrenamiento con el archivo de configuración especificado:
separación de cd python train.py --conf_dir=configs/afrcnn.yaml
Navegue hasta el directorio enhancement y ejecute el script de capacitación con el archivo de configuración especificado:
mejora de cd python train.py --conf_dir=config/dccrn.yaml
Verifique el contenido de README.md en las carpetas sep-checkpoints y enh-checkpoints, descargue los modelos previamente entrenados apropiados en Release y descomprímalos en las carpetas apropiadas.
Navegue hasta el directorio separation y ejecute el script de inferencia con el archivo de configuración especificado:
separación de cd python inference.py --conf_dir=../sep-checkpoints/TFGNet-Noise/config.yaml
Navegue hasta el directorio enhancement y ejecute el script de inferencia con el archivo de configuración especificado:
mejora de cd python inference.py --conf_dir=../enh-checkpoints/TaylorSENet-Noise/config.yaml


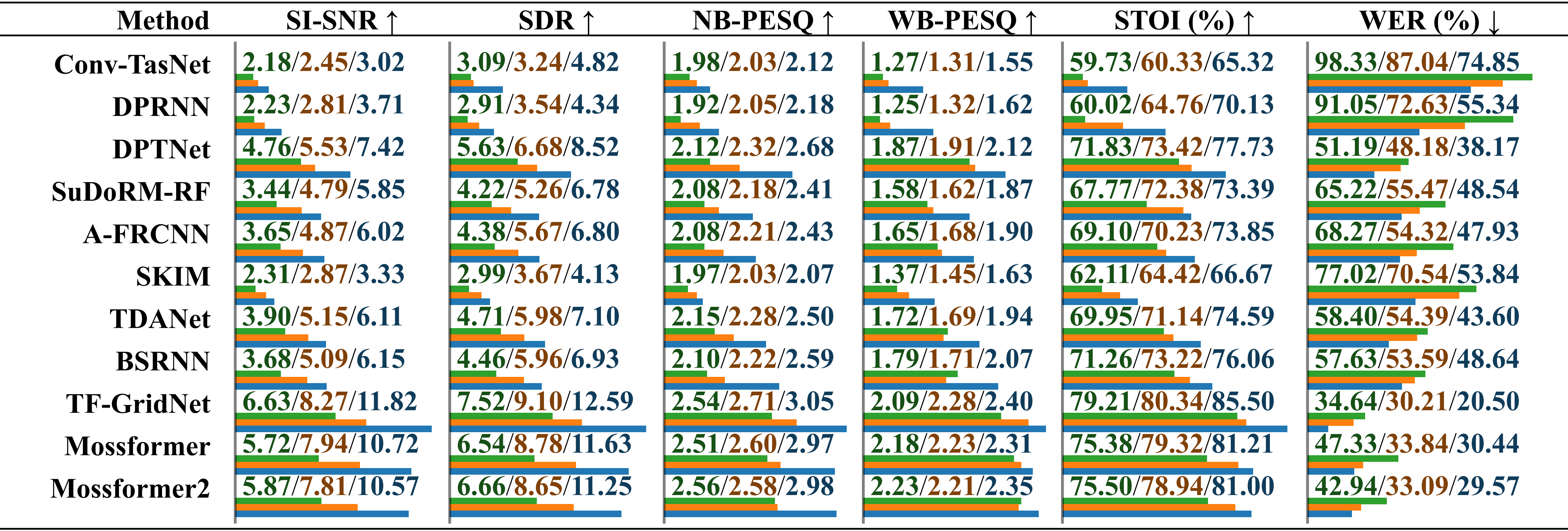
Evaluación comparativa del rendimiento de modelos entrenados en diferentes conjuntos de datos utilizando audio grabado real con ruido ambiental . Los resultados se informan por separado para "entrenado en LRS2-2Mix", "entrenado en Libri2Mix" y "entrenado en SonicSet", distinguidos por una barra. La longitud relativa se indica debajo del valor mediante barras horizontales.


Evaluación comparativa del rendimiento de modelos entrenados en diferentes conjuntos de datos utilizando audio grabado real con ruido musical . Los resultados se informan por separado para "entrenado en LRS2-2Mix", "entrenado en Libri2Mix" y "entrenado en SonicSet", distinguidos por una barra.


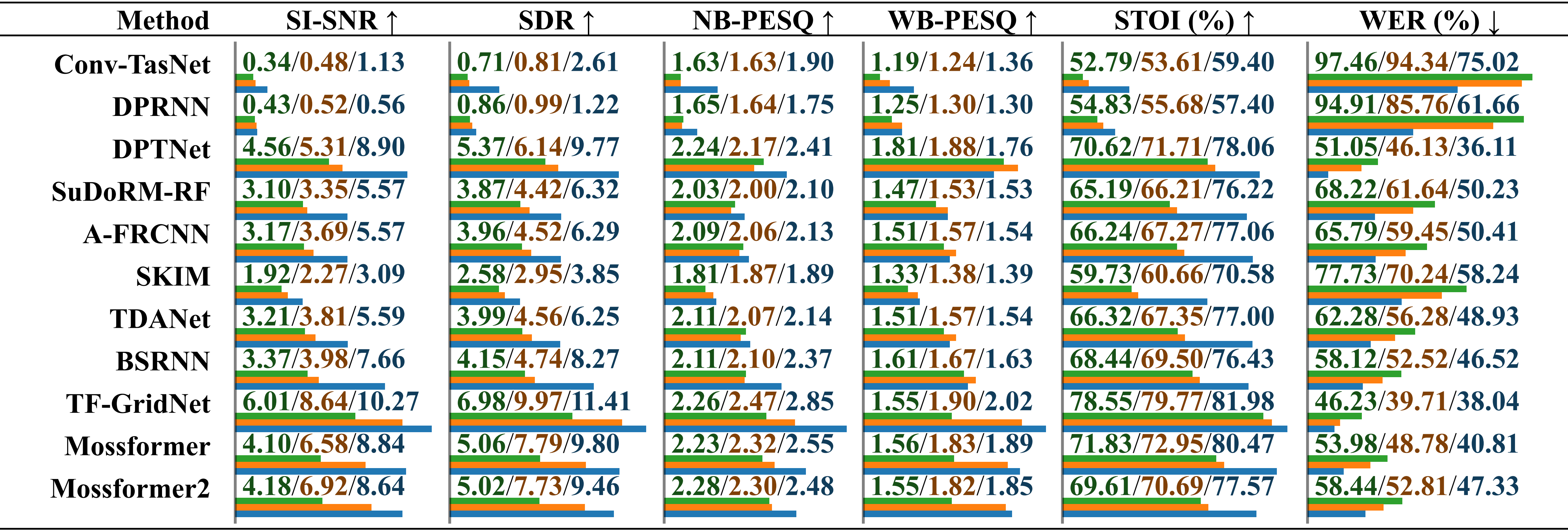
Evaluación comparativa del rendimiento de modelos entrenados en diferentes conjuntos de datos utilizando el conjunto de datos RealMAN. Los resultados se informan por separado para "capacitados en VoiceBank+DEMAND", "capacitados en DNS Challenge" y "capacitados en SonicSet", distinguidos por una barra.
Hemos entrenado modelos de separación y mejora en el conjunto de datos SonicSet. Los resultados son los siguientes:


Comparación de los métodos de separación de voz existentes en el conjunto de datos SonicSet. El rendimiento de cada modelo se enumera por separado para los resultados en “ruido ambiental” y “ruido musical”, distinguidos por una barra.


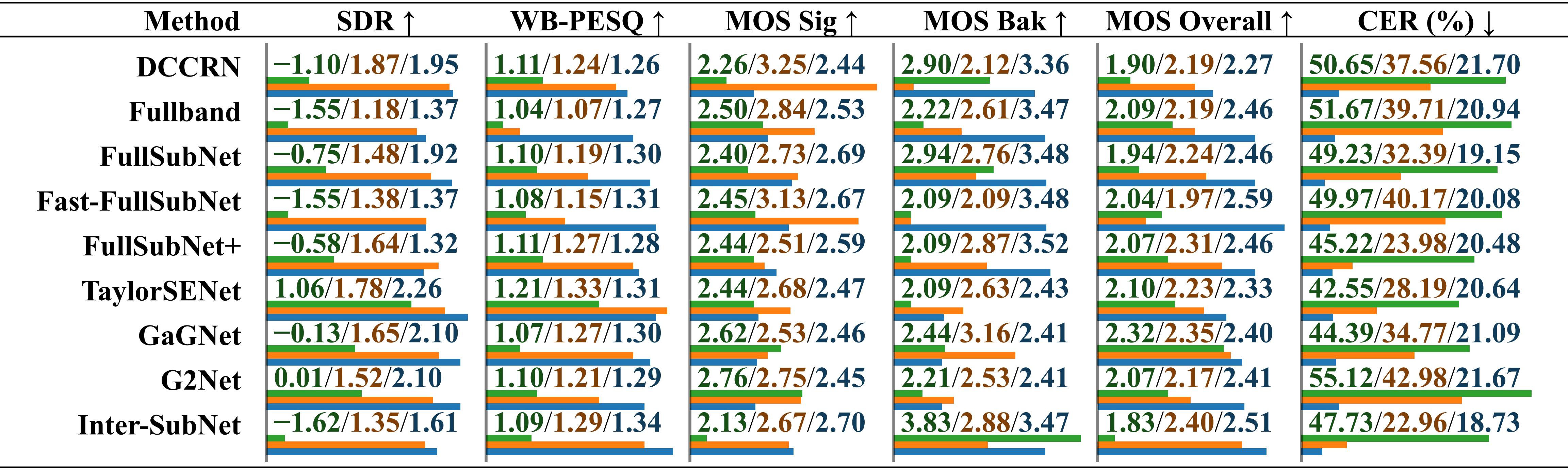
Comparación de métodos de mejora del habla existentes en Comparación de métodos de mejora del habla utilizando el conjunto de pruebas SonicSet. Las métricas se enumeran por separado en “ruido ambiental” y “ruido musical”, distinguidas por una barra.
Nos gustaría expresar nuestro agradecimiento a las siguientes personas:
LibriSpeech para proporcionar los datos de voz.
SoundSpaces para el entorno de simulación.
Apple por proporcionar guiones de síntesis de audio dinámico.
Este trabajo está bajo una licencia internacional Creative Commons Atribución-CompartirIgual 4.0.