Kamil Slowikowski
2024-04-22
Tabla de contenido
Aquí, compartimos un único archivo afnd.tsv (5,99 MB) en formato delimitado por tabulaciones con todas las frecuencias alélicas para 8 genes HLA, 18 genes KIR, 2 genes MIC y 29 genes de citocinas de la base de datos Allele Frequency Net Database (AFND).
El script allelefrequencies.py descarga automáticamente frecuencias alélicas del sitio web.
¿Qué es la base de datos neta de frecuencia de alelos?
La base de datos Allele Frequency Net (AFND) es una base de datos pública que contiene información de frecuencia de varios genes inmunes, como los antígenos leucocitarios humanos (HLA), los receptores similares a inmunoglobulinas de células asesinas (KIR), el complejo mayor de histocompatibilidad relacionado con la cadena de clase I (MIC). ) genes y varios polimorfismos de genes de citoquinas.
El archivo afnd.tsv tiene este aspecto:
d <- fread( " afnd.tsv " )
head( d ) ## group gene allele population indivs_over_n alleles_over_2n n
## 1: hla A A*01:01 Argentina Rosario Toba 15.1 0.0760 86
## 2: hla A A*01:01 Armenia combined Regions 0.1250 100
## 3: hla A A*01:01 Australia Cape York Peninsula Aborigine 0.0530 103
## 4: hla A A*01:01 Australia Groote Eylandt Aborigine 0.0270 75
## 5: hla A A*01:01 Australia New South Wales Caucasian 0.1870 134
## 6: hla A A*01:01 Australia Yuendumu Aborigine 0.0080 191
Definiciones:
alleles_over_2n (Allelos / 2n) Frecuencia del alelo: número total de copias del alelo en la muestra de población en formato tres decimales.
indivs_over_n (100 * Individuos / n) Porcentaje de individuos que tienen el alelo o gen.
n (Individuos) Número de individuos muestreados de la población.
Aquí hay algunos ejemplos de cómo podemos usar R para analizar estos datos.
Vea las poblaciones más grandes y más pequeñas disponibles en los datos:
d % > %
mutate( n = parse_number( n )) % > %
select( population , n ) % > %
unique() % > %
arrange( - n ) ## population n
## 1: Germany DKMS - German donors 3456066
## 2: USA NMDP European Caucasian 1242890
## 3: USA NMDP African American pop 2 416581
## 4: USA NMDP Mexican or Chicano 261235
## 5: USA NMDP South Asian Indian 185391
## ---
## 1489: Cameroon Sawa 13
## 1490: Paraguay/Argentina Ache NA-DHS_24 (G) 13
## 1491: Malaysia Orang Kanaq Cytokine 11
## 1492: Cameroon Baka Pygmy 10
## 1493: Paraguay/Argentina Guarani NA-DHS_23 (G) 10
Cuente el número de alelos de cada gen:
d % > %
count( group , gene , allele ) % > %
count( group , gene ) % > %
arrange( - n ) % > %
head( 15 ) ## group gene n
## 1: hla B 1979
## 2: hla A 1394
## 3: hla C 1209
## 4: hla DRB1 954
## 5: hla DPB1 384
## 6: hla DQB1 351
## 7: kir 3DL1 90
## 8: mic MICA 69
## 9: kir 3DL3 67
## 10: kir 2DL1 52
## 11: kir 2DL4 35
## 12: mic MICB 34
## 13: hla DQA1 30
## 14: kir 3DL2 30
## 15: kir 2DL5B 24
Sume las frecuencias alélicas de cada gen en cada población. Esto nos permite ver qué poblaciones tienen un conjunto de frecuencias alélicas que suman el 100 por ciento:
d % > %
mutate( alleles_over_2n = parse_number( alleles_over_2n )) % > %
filter( alleles_over_2n > 0 ) % > %
group_by( group , gene , population ) % > %
summarize( sum = sum( alleles_over_2n )) % > %
count( sum == 1 ) ## `summarise()` has grouped output by 'group', 'gene'. You can override using the `.groups` argument.
## # A tibble: 44 × 4
## # Groups: group, gene [28]
## group gene `sum == 1` n
##
## 1 hla A FALSE 420
## 2 hla A TRUE 18
## 3 hla B FALSE 513
## 4 hla B TRUE 19
## 5 hla C FALSE 323
## 6 hla C TRUE 19
## 7 hla DPA1 FALSE 54
## 8 hla DPA1 TRUE 6
## 9 hla DPB1 FALSE 207
## 10 hla DPB1 TRUE 39
## # ℹ 34 more rows
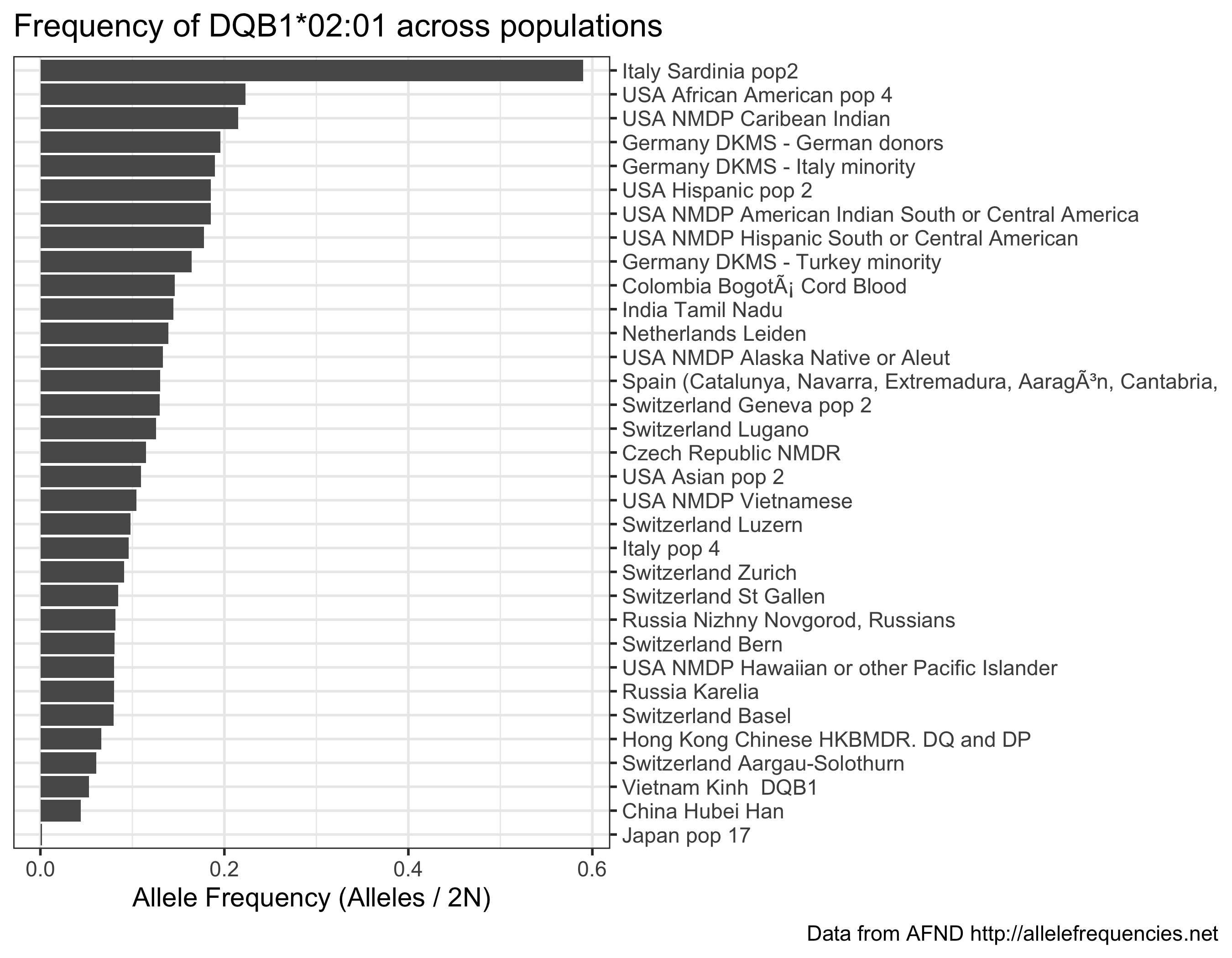
Trazar la frecuencia de un alelo específico en poblaciones con más de 1000 individuos muestreados:
my_allele <- " DQB1*02:01 "
my_d <- d % > % filter( allele == my_allele ) % > %
mutate(
n = parse_number( n ),
alleles_over_2n = parse_number( alleles_over_2n )
) % > %
filter( n > 1000 ) % > %
arrange( - alleles_over_2n )
ggplot( my_d ) +
aes( x = alleles_over_2n , y = reorder( population , alleles_over_2n )) +
scale_y_discrete( position = " right " ) +
geom_colh() +
labs(
x = " Allele Frequency (Alleles / 2N) " ,
y = NULL ,
title = glue( " Frequency of {my_allele} across populations " ),
caption = " Data from AFND http://allelefrequencies.net "
)
Si utiliza estos datos, cite el último manuscrito sobre Allele Frequency Net Database :
@ARTICLE{Gonzalez-Galarza2020,
title = "{Allele frequency net database (AFND) 2020 update: gold-standard
data classification, open access genotype data and new query
tools}",
author = "Gonzalez-Galarza, Faviel F and McCabe, Antony and Santos, Eduardo
J Melo Dos and Jones, James and Takeshita, Louise and
Ortega-Rivera, Nestor D and Cid-Pavon, Glenda M Del and
Ramsbottom, Kerry and Ghattaoraya, Gurpreet and Alfirevic, Ana
and Middleton, Derek and Jones, Andrew R",
journal = "Nucleic acids research",
volume = 48,
number = "D1",
pages = "D783--D788",
month = jan,
year = 2020,
language = "en",
issn = "0305-1048, 1362-4962",
pmid = "31722398",
doi = "10.1093/nar/gkz1029",
pmc = "PMC7145554"
}
Aquí están todos los recursos que pude encontrar que tienen información sobre las frecuencias de los alelos HLA en diferentes poblaciones.
https://github.com/Vaccitech/HLAfreq/
Los autores proporcionan archivos xlsx en este sitio web:
Pero la información de frecuencia está agrupada en categorías:
Existe una herramienta llamada HLA-Net que proporciona una visualización de los datos de CIWD.
http://tools.iedb.org/population/download
En la página de Herramientas de IEDB podemos encontrar una herramienta llamada Cobertura de Población . Los autores descargaron la información de frecuencia HLA de AFND y la guardaron en un archivo pickle de Python.
https://www.ncbi.nlm.nih.gov/gv/mhc
La base de datos y el sitio web de dbMHC parecen estar descontinuados. Pero todavía hay un archivo de archivos antiguos disponible a través de FTP.
https://bioinformatics.bethematchclinical.org/hla-resources/haplotype-frequencies/high-solving-hla-alleles-and-haplotypes-in-the-us-population/
Gracias a David A. Wells por compartir scrapeAF, que me inspiró a trabajar en este proyecto.