KAN: Kolmogorov-Arnold Networks es un retador prometedor para las MLP tradicionales. ¡Estamos encantados de integrar KAN en NeRF! ¿KAN es adecuado para tareas de síntesis de vistas ? ¿Qué desafíos enfrentaremos? ¿Cómo los abordaremos? ¡Ofrecemos nuestras observaciones iniciales y discusiones futuras!
KANeRF está basado en nerfstudio y Efficient-KAN. Consulte el sitio web para obtener instrucciones detalladas de instalación si tiene algún problema.
# create python env
conda create --name nerfstudio -y python=3.8
conda activate nerfstudio
python -m pip install --upgrade pip
# install torch
pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
conda install -c " nvidia/label/cuda-11.8.0 " cuda-toolkit
# install tinycudann
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torch
# install nerfstudio
pip install nerfstudio
# install efficient-kan
pip install git+https://github.com/Blealtan/efficient-kan.gitIntegramos KAN y NeRFacto y comparamos KANeRF con NeRFacto en términos de parámetros del modelo, tiempo de entrenamiento, rendimiento de síntesis de vistas novedosas, etc. en el conjunto de datos de Blender. Bajo la misma configuración de red, KAN supera ligeramente a MLP en síntesis de vistas novedosas, lo que sugiere que KAN posee una capacidad de adaptación más potente. Sin embargo, la velocidad de inferencia y entrenamiento de KAN es significativamente** más lenta que la de MLP. Además, con un número comparable de parámetros, KAN tiene un rendimiento inferior al MLP.
| Modelo | NeRFacto | NeRFacto pequeño | KANeRF |
|---|---|---|---|
| Parámetros de red entrenables | 8192 | 2176 | 7131 |
| Parámetros totales de la red | 8192 | 2176 | 10683 |
| oculto_tenue | 64 | 8 | 8 |
| color oscuro oculto | 64 | 8 | 8 |
| numero de capas | 2 | 1 | 1 |
| número de capas de color | 2 | 1 | 1 |
| geo hazaña tenue | 15 | 7 | 7 |
| apariencia incrustar tenue | 32 | 8 | 8 |
| Tiempo de entrenamiento | 14m 13s | 13m 47s | 37m 20s |
| FPS | 2.5 | ~2.5 | 0,95 |
| LPIPS | 0.0132 | 0.0186 | 0.0154 |
| PSNR | 33,69 | 32,67 | 33.10 |
| SSIM | 0.973 | 0.962 | 0.966 |
| Pérdida | 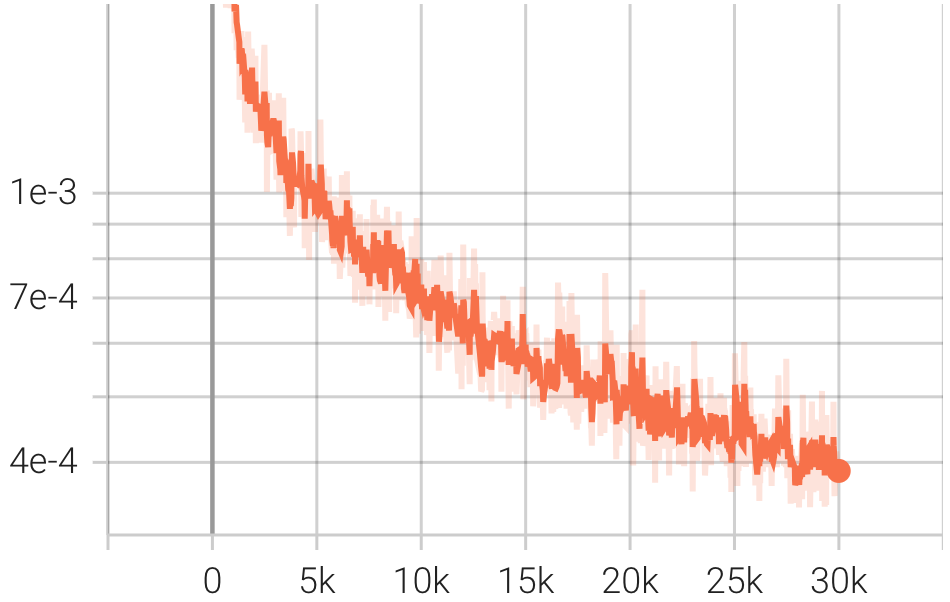 | 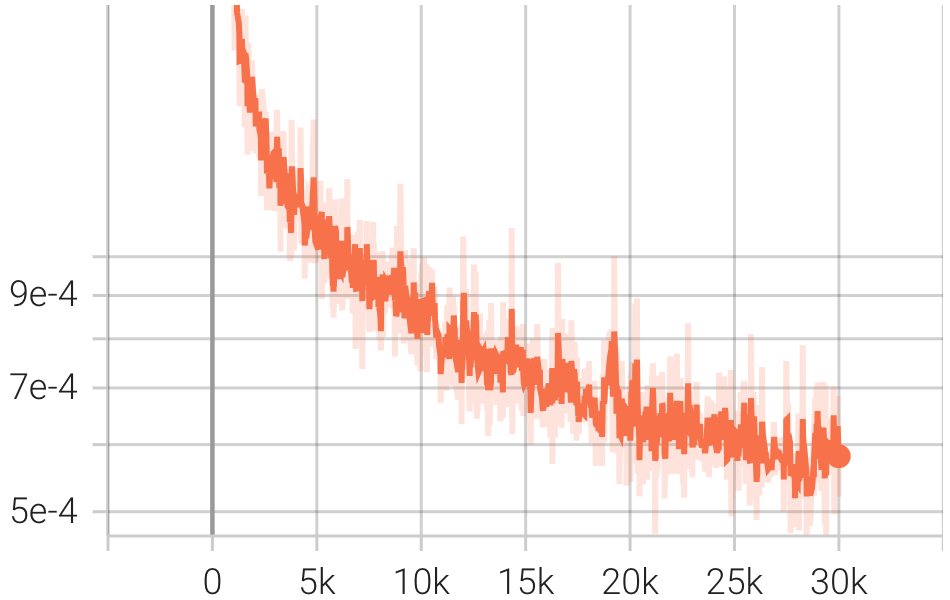 | 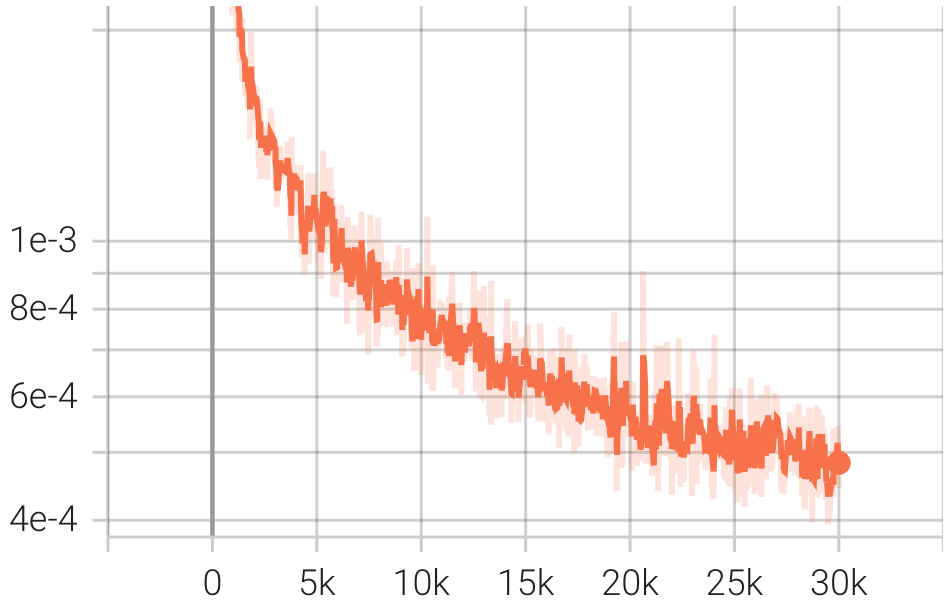 |
| resultado (rgb) | nerfacto_rgb.mp4 | nerfacto_tiny_rgb.mp4 | kanerf_rgb.mp4 |
| resultado (profundidad) | nerfacto_profundidad.mp4 | nerfacto_tiny_profundidad.mp4 | kanerf_profundidad.mp4 |
KAN tiene potencial de optimización, particularmente en lo que respecta a acelerar su velocidad de inferencia. Planeamos desarrollar una versión de KAN acelerada por CUDA para mejorar aún más su rendimiento: D
@Manual {,
title = { Hands-On NeRF with KAN } ,
author = { Delin Qu, Qizhi Chen } ,
year = { 2024 } ,
url = { https://github.com/Tavish9/KANeRF } ,
}

