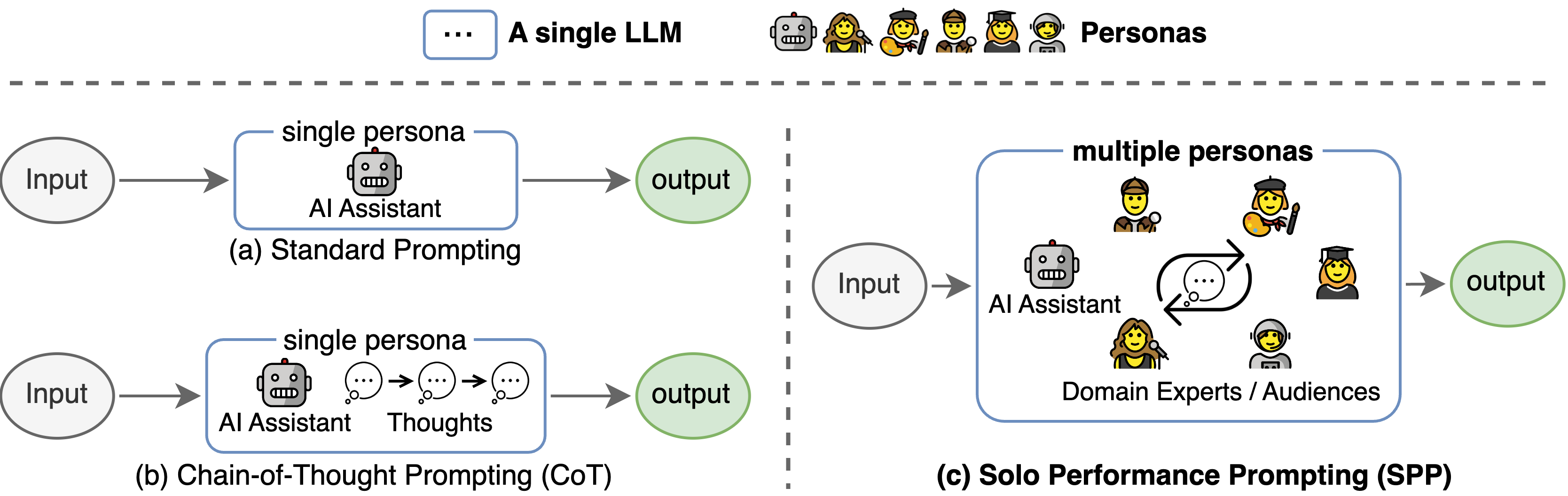
5/8/2024 : Actualización del código de inferencia GPT-3.5 y LLama2 y los resultados de la Figura 6, que muestra la naturaleza emergente de la sinergia cognitiva.3/15/2024 : ¡Este artículo ha sido aceptado como artículo principal de la conferencia en NAACL2024! pip install -r requirements.txt
config_template.sh y ejecute source config_template.sh para configurar las variables env (tenga en cuenta que estamos usando la API de Azure en nuestros experimentos) Proporcionamos scripts en ejecución para cada una de las tres tareas; consulte los comentarios en los scripts ".sh" para obtener más información:
bash scripts/trivia_creative_writing.shbash scripts/codenames_collaborative.shbash scripts/logic_grid_puzzle.sh Todos los mensajes se pueden encontrar en la carpeta prompts/ .
Todos los conjuntos de datos se pueden encontrar en la carpeta data/ .
Los resultados experimentales en el documento para cada tarea se pueden encontrar en la carpeta logs/ . gpt4_w_sys_mes y gpt4_wo_sys_mes contienen resultados correspondientes a la Tabla 2 de nuestro artículo. También incluimos los resultados de gpt-3.5 y llama2-13b correspondientes a los resultados de la Figura 6, donde los hiperparámetros, como si agregar o no un mensaje del sistema, siguen las opciones de mejor rendimiento en los experimentos de gpt4.
"test_output_infos" : contiene métricas de evaluación para cada instancia, por ejemplo, # respuestas correctas mencionadas."*raw_responses" : respuestas sin procesar de cada llamada a la API."*parsing_flag" : si la respuesta sin formato se analizó correctamente. (para la tarea de nombres en clave, este campo está separado en "parsing_success_flag_spymaster" y "parsing_success_flag_guesser")"unwrapped_output" : salida analizada que se utilizará para calcular las métricas de evaluación. (para la tarea de nombres en clave, este campo está separado en "spymaster_output" y "guesser_output"; hay un campo adicional llamado "hint_word" que se analiza a partir de la salida de spymaster y se inserta en la entrada de Guesser; la métrica de evaluación se calcula en función de " adivinador_salida")"task data" : datos para la instancia de la tarea actual, por ejemplo, preguntas, respuestas, palabras objetivo, etc."usage" : registro de la cantidad de tokens y el costo gastado hasta el momento.Cite el artículo y destaque este repositorio si encuentra este trabajo interesante/útil.
@article{wang2023unleashing,
title={Unleashing Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration},
author={Wang, Zhenhailong and Mao, Shaoguang and Wu, Wenshan and Ge, Tao and Wei, Furu and Ji, Heng},
journal={arXiv preprint arXiv:2307.05300},
year={2023}
}
Esta base de código hacía referencia a la estructura del repositorio oficial de Tree-of-thinking. Agradecemos a los autores por sus esfuerzos de código abierto.


