DeepKE
DeepKE 2.2.7
Inglés | 简体中文
Un kit de herramientas de extracción de conocimientos basado en el aprendizaje profundo
para la construcción de gráficos de conocimiento
DeepKE es un conjunto de herramientas de extracción de conocimiento para la construcción de gráficos de conocimiento que admite escenarios cnSchema , de bajos recursos , a nivel de documento y multimodales para la extracción de entidades , relaciones y atributos . Proporcionamos documentos, demostraciones en línea, papel, diapositivas y carteles para principiantes.
\ en las rutas de los archivos;wisemodel o modescape .Si encuentra algún problema durante la instalación de DeepKE y DeepKE-LLM, consulte Sugerencias o envíe un problema de inmediato y lo ayudaremos a resolver el problema.
April, 2024 Lanzamos un nuevo modelo de extracción de información basado en esquemas bilingüe (chino e inglés) llamado OneKE basado en Chinese-Alpaca-2-13B.Feb, 2024 Lanzamos un conjunto de datos de instrucciones de extracción de información (IE) bilingüe (chino e inglés) de alta calidad y a gran escala (0,32 mil millones de tokens) llamado IEPile, junto con dos modelos entrenados con IEPile , baichuan2-13b-iepile-lora y llama2. -13b-iepile-lora.Sep 2023 se lanzó un conjunto de datos de instrucciones bilingües de extracción de información (IE) en chino e inglés llamado InstructIE para la tarea de construcción de gráficos de conocimiento basada en instrucciones (KGC basado en instrucciones), como se detalla aquí.June, 2023 Actualizamos DeepKE-LLM para admitir la extracción de conocimientos con KnowLM, ChatGLM, series LLaMA, series GPT, etc.Apr, 2023 Hemos agregado nuevos modelos, incluidos CP-NER (IJCAI'23), ASP (EMNLP'22), PRGC (ACL'21), PURE (NAACL'21), capacidades de extracción de eventos proporcionadas (chino e inglés). y ofrecía compatibilidad con versiones superiores de paquetes de Python (por ejemplo, Transformers).Feb, 2023 Admitimos el uso de LLM (GPT-3) con aprendizaje en contexto (basado en EasyInstruct) y generación de datos, agregamos un modelo NER W2NER (AAAI'22). Nov, 2022 Agregue instrucciones de anotación de datos para el reconocimiento de entidades y extracción de relaciones, etiquetado automático de datos débilmente supervisados (extracción de entidades y extracción de relaciones) y optimice el entrenamiento con múltiples GPU.
Sept, 2022 El artículo DeepKE: un kit de herramientas de extracción de conocimientos basado en aprendizaje profundo para la población de la base de conocimientos ha sido aceptado por la vía de demostración del sistema EMNLP 2022.
Aug, 2022 Hemos agregado soporte de aumento de datos (chino, inglés) para la extracción de relaciones de bajos recursos.
June, 2022 Hemos agregado soporte multimodal para extracción de entidades y relaciones.
May, 2022 Hemos lanzado DeepKE-cnschema con modelos de extracción de conocimientos disponibles en el mercado.
Jan, 2022 Hemos publicado un artículo DeepKE: un kit de herramientas de extracción de conocimientos basado en aprendizaje profundo para la población de la base de conocimientos.
Dec, 2021 Hemos agregado dockerfile para crear el entorno automáticamente.
Nov, 2021 Se lanzó la demostración de DeepKE, que admite la extracción en tiempo real sin implementación ni capacitación.
Se ha publicado la documentación de DeepKE, que contiene los detalles de DeepKE, como códigos fuente y conjuntos de datos.
Oct, 2021 pip install deepke
Se han publicado los códigos de deepke-v2.0.
Aug, 2019 Se han publicado los códigos de deepke-v1.0.
Aug, 2018 Se lanzaron el inicio del proyecto DeepKE y los códigos de deepke-v0.1.
Hay una demostración de predicción. El archivo GIF es creado por Terminalizer. Obtén el código. 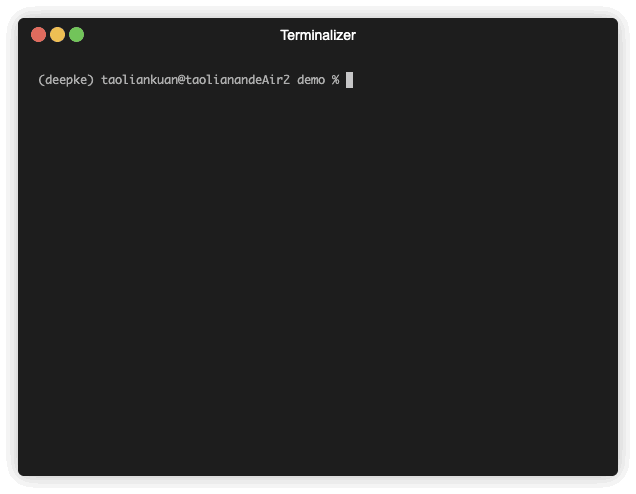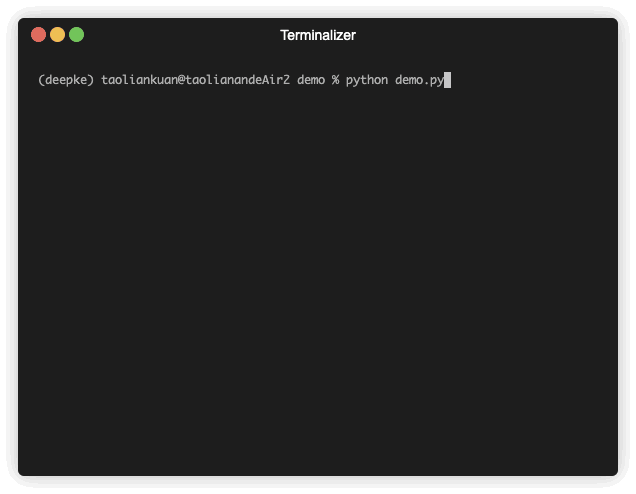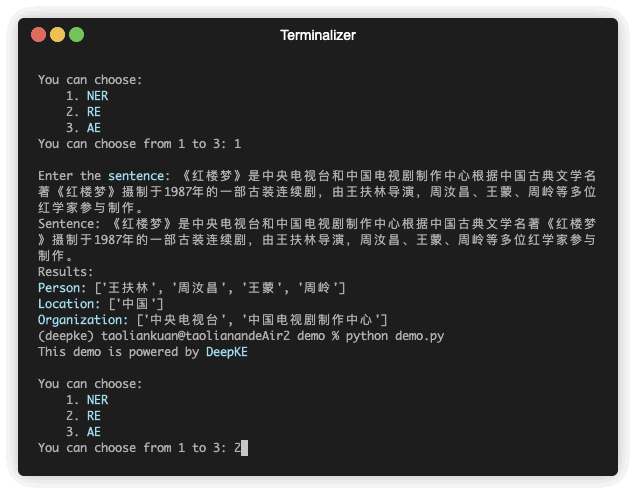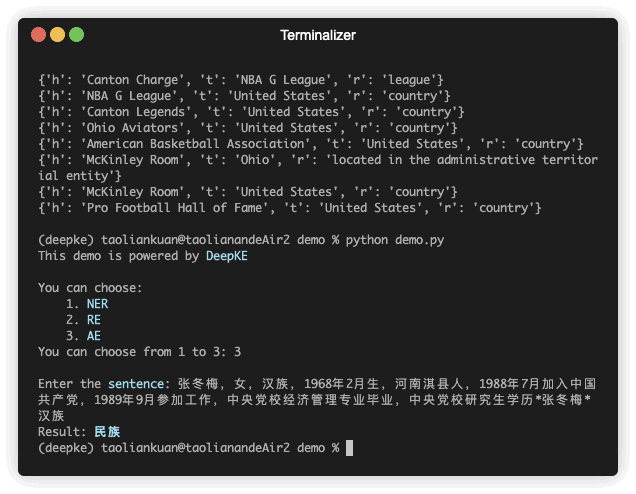
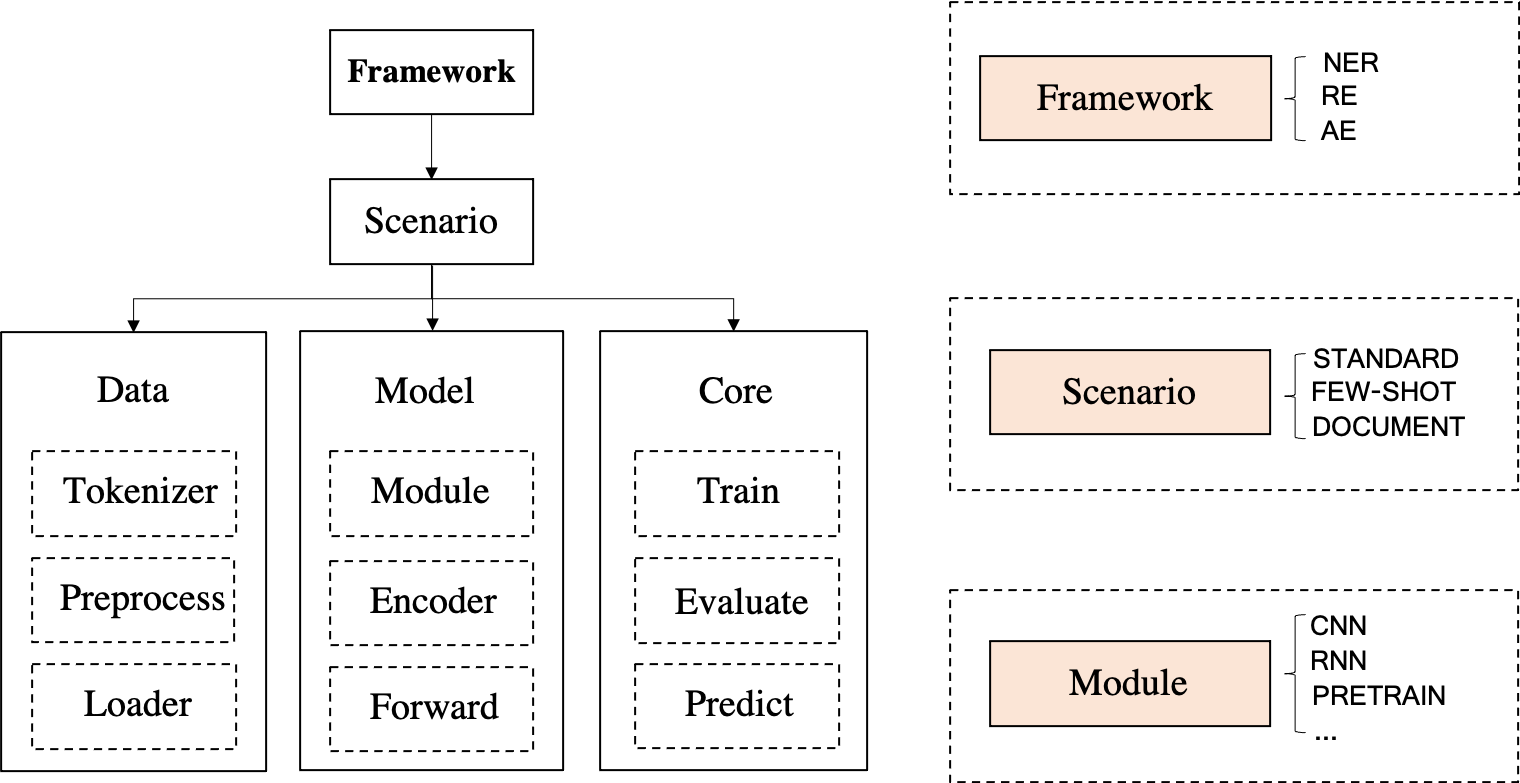
En la era de los modelos grandes, DeepKE-LLM utiliza una dependencia del entorno completamente nueva.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Tenga en cuenta que el archivo requirements.txt se encuentra en la carpeta example/llm .
pip install deepke .Paso 1 Descarga el código básico
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Paso 2 Cree un entorno virtual usando Anaconda e ingréselo.
conda create -n deepke python=3.8
conda activate deepkeInstale DeepKE con el código fuente
pip install -r requirements.txt
python setup.py install
python setup.py develop Instale DeepKE con pip ( ¡NO recomendado! )
pip install deepkePaso 3 Ingrese al directorio de tareas
cd DeepKE/example/re/standardPaso 4 Descargue el conjunto de datos o siga las instrucciones de anotación para obtener datos
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzSe admiten muchos tipos de formatos de datos y los detalles se encuentran en cada parte.
Paso 5 Entrenamiento (Los parámetros para el entrenamiento se pueden cambiar en la carpeta conf )
Admitimos el ajuste de parámetros visuales mediante el uso de wandb .
python run.py Predicción del paso 6 (los parámetros de predicción se pueden cambiar en la carpeta conf )
Modifique la ruta del modelo entrenado en predict.yaml . Es necesario utilizar la ruta absoluta del modelo, como xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyPaso 1 Instale el cliente Docker
Instale Docker e inicie el servicio Docker.
Paso 2 Extraiga la imagen de la ventana acoplable y ejecute el contenedor
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashLos pasos restantes son los mismos que el Paso 3 y siguientes en Configuración manual del entorno .
pitón == 3.8
El reconocimiento de entidades nombradas busca localizar y clasificar entidades nombradas mencionadas en texto no estructurado en categorías predefinidas, como nombres de personas, organizaciones, ubicaciones, organizaciones, etc.
Los datos se almacenan en archivos .txt . Algunos casos son los siguientes (los usuarios pueden etiquetar datos basándose en las herramientas Doccano, MarkTool o pueden usar la supervisión débil con DeepKE para obtener datos automáticamente):
| Oración | Persona | Ubicación | Organización |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行. | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | 王扶林,周汝昌,王蒙,周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一. | 秦始皇 | 陕西省,西安市 |
Lea el proceso detallado en README específico
ESTÁNDAR (Totalmente supervisado)
Respaldamos LLM y proporcionamos el modelo listo para usar, DeepKE-cnSchema-NER, que extraerá entidades en cnSchema sin capacitación.
Paso 1 Ingrese DeepKE/example/ner/standard . Descargue el conjunto de datos.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Entrenamiento Paso 2
El conjunto de datos y los parámetros se pueden personalizar en la carpeta data y la carpeta conf respectivamente.
python run.pyPredicción del paso 3
python predict.pyPOCOS DISPAROS
Paso 1 Ingrese DeepKE/example/ner/few-shot . Descargue el conjunto de datos.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Paso 2 Capacitación en entornos de bajos recursos
El directorio donde se carga y guarda el modelo y los parámetros de configuración se pueden personalizar en la carpeta conf .
python run.py +train=few_shot Los usuarios pueden modificar load_path en conf/train/few_shot.yaml para usar el modelo cargado existente.
Paso 3 Agregar - predict a conf/config.yaml , modificar loda_path como ruta del modelo y write_path como la ruta donde se guardan los resultados pronosticados en conf/predict.yaml , y luego ejecutar python predict.py
python predict.pyMULTIMODAL
Paso 1 Ingrese DeepKE/example/ner/multimodal . Descargue el conjunto de datos.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzUsamos objetos detectados por RCNN y objetos de conexión a tierra visual de imágenes originales como información local visual, donde RCNN a través de fast_rcnn y conexión a tierra visual a través de onestage_grounding.
Paso 2 Capacitación en el entorno multimodal
data y la carpeta conf respectivamente.load_path en conf/train.yaml como la ruta donde se guardó el modelo entrenado la última vez. Y los registros de guardado de rutas generados en el entrenamiento se pueden personalizar mediante log_dir . python run.pyPredicción del paso 3
python predict.pyLa extracción de relaciones es la tarea de extraer relaciones semánticas entre entidades de un texto no estructurado.
Los datos se almacenan en archivos .csv . Algunos casos son los siguientes (los usuarios pueden etiquetar datos basándose en las herramientas Doccano, MarkTool o pueden usar la supervisión débil con DeepKE para obtener datos automáticamente):
| Oración | Relación | Cabeza | Desplazamiento_cabezal | Cola | Desplazamiento_cola |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景,西湖总是第一个映入脑海的词语. | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!NOTA: Si hay varios tipos de entidad para una relación, los tipos de entidad pueden tener el prefijo de la relación como entradas.
Lea el proceso detallado en README específico
ESTÁNDAR (Totalmente supervisado)
Respaldamos LLM y proporcionamos el modelo listo para usar, DeepKE-cnSchema-RE, que extraerá relaciones en cnSchema sin capacitación.
Paso 1 Ingrese a la carpeta DeepKE/example/re/standard . Descargue el conjunto de datos.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Entrenamiento Paso 2
El conjunto de datos y los parámetros se pueden personalizar en la carpeta data y la carpeta conf respectivamente.
python run.pyPredicción del paso 3
python predict.pyPOCOS DISPAROS
Paso 1 Ingrese DeepKE/example/re/few-shot . Descargue el conjunto de datos.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz Paso 2 Entrenamiento
data y la carpeta conf respectivamente.train_from_saved_model en conf/train.yaml como la ruta donde se guardó el modelo entrenado la última vez. Y los registros de guardado de rutas generados en el entrenamiento se pueden personalizar mediante log_dir . python run.pyPredicción del paso 3
python predict.py DOCUMENTO
Paso 1 Ingrese DeepKE/example/re/document . Descargue el conjunto de datos.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Entrenamiento Paso 2
data y la carpeta conf respectivamente.train_from_saved_model en conf/train.yaml como la ruta donde se guardó el modelo entrenado la última vez. Y los registros de guardado de rutas generados durante el entrenamiento se pueden personalizar mediante log_dir . python run.pyPredicción del paso 3
python predict.pyMULTIMODAL
Paso 1 Ingrese DeepKE/example/re/multimodal . Descargue el conjunto de datos.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzUsamos objetos detectados por RCNN y objetos de conexión a tierra visual de imágenes originales como información local visual, donde RCNN a través de fast_rcnn y conexión a tierra visual a través de onestage_grounding.
Entrenamiento Paso 2
data y la carpeta conf respectivamente.load_path en conf/train.yaml como la ruta donde se guardó el modelo entrenado la última vez. Y los registros de guardado de rutas generados en el entrenamiento se pueden personalizar mediante log_dir . python run.pyPredicción del paso 3
python predict.pyLa extracción de atributos consiste en extraer atributos de entidades en un texto no estructurado.
Los datos se almacenan en archivos .csv . Algunos casos como los siguientes:
| Oración | atención | ent | Ent_offset | vale | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三国时期杰出的军事家、文学家、发明家。 | 朝代 | 诸葛亮 | 0 | 三国时期 | 8 |
| 2014年10月1日许鞍华执导的电影《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 2014年10月1日 | 0 |
Lea el proceso detallado en README específico
ESTÁNDAR (Totalmente supervisado)
Paso 1 Ingrese a la carpeta DeepKE/example/ae/standard . Descargue el conjunto de datos.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Entrenamiento Paso 2
El conjunto de datos y los parámetros se pueden personalizar en la carpeta data y la carpeta conf respectivamente.
python run.pyPredicción del paso 3
python predict.py.tsv , algunos casos son los siguientes:| Oración | Tipo de evento | Desencadenar | Role | Argumento | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天. | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 中国外运2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | 股权 | ||||
| 美国亚特兰大航展13日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡. | 灾害/意外-坠机 | 坠机 | 时间 | 13日 | |
| 地点 | 美国亚特兰 | ||||
Lea el proceso detallado en README específico
ESTÁNDAR (Totalmente supervisado)
Paso 1 Ingrese a la carpeta DeepKE/example/ee/standard . Descargue el conjunto de datos.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipPaso 2 Entrenamiento
El conjunto de datos y los parámetros se pueden personalizar en la carpeta data y la carpeta conf respectivamente.
python run.pyPaso 3 Predicción
python predict.py 1. Using nearest mirror , JUE en China, acelerará la instalación de Anaconda ; Aliyun en China acelerará pip install XXX .
2.Cuando encuentre ModuleNotFoundError: No module named 'past' , ejecute pip install future .
3. La instalación en línea de los modelos de lenguaje previamente entrenados es lenta. Se recomienda descargar modelos previamente entrenados antes de usarlos y guardarlos en la carpeta pretrained . Lea README.md en cada directorio de tareas para verificar los requisitos específicos para guardar modelos previamente entrenados.
4.La versión anterior de DeepKE se encuentra en la rama deepke-v1.0. Los usuarios pueden cambiar la rama para usar la versión anterior. La versión anterior se ha transferido totalmente a la extracción de relaciones estándar (ejemplo/re/estándar).
5.Si desea modificar el código fuente, se recomienda instalar DeepKE con los códigos fuente. De lo contrario, la modificación no funcionará. Ver edición
6. Se pueden encontrar más trabajos relacionados con la extracción de conocimientos de bajos recursos en Extracción de conocimientos en escenarios de bajos recursos: encuesta y perspectiva.
7.Asegúrese de que las versiones exactas de los requisitos estén en requirements.txt .
En la próxima versión, planeamos lanzar un LLM más sólido para KE.
Mientras tanto, ofreceremos mantenimiento a largo plazo para corregir errores , resolver problemas y satisfacer nuevas solicitudes . Entonces, si tiene algún problema, díganoslo.
Construcción de gráficos de conocimiento eficiente en datos, 高效知识图谱构建 (Tutorial sobre CCKS 2022) [diapositivas]
Construcción de gráficos de conocimiento eficiente y sólido (tutorial sobre AACL-IJCNLP 2022) [diapositivas]
Familia PromptKG: una galería de trabajos de investigación, kits de herramientas y listas de artículos relacionados con Prompt Learning y KG [Recursos]
Extracción de conocimientos en escenarios de bajos recursos: encuesta y perspectiva [Encuesta][Lista de artículos]
Doccano, MarkTool, LabelStudio: kits de herramientas de anotación de datos
LambdaKG: una biblioteca y punto de referencia para incorporaciones de KG basadas en PLM
EasyInstruct: un marco fácil de usar para enseñar modelos de lenguaje grandes
Materiales de lectura :
Construcción de gráficos de conocimiento eficiente en datos, 高效知识图谱构建 (Tutorial sobre CCKS 2022) [diapositivas]
Construcción de gráficos de conocimiento eficiente y sólido (tutorial sobre AACL-IJCNLP 2022) [diapositivas]
Familia PromptKG: una galería de trabajos de investigación, kits de herramientas y listas de artículos relacionados con Prompt Learning y KG [Recursos]
Extracción de conocimientos en escenarios de bajos recursos: encuesta y perspectiva [Encuesta][Lista de artículos]
Kit de herramientas relacionado :
Doccano, MarkTool, LabelStudio: kits de herramientas de anotación de datos
LambdaKG: una biblioteca y punto de referencia para incorporaciones de KG basadas en PLM
EasyInstruct: un marco fácil de usar para enseñar modelos de lenguaje grandes
Cite nuestro artículo si utiliza DeepKE en su trabajo.
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
Colaboradores de la comunidad: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


