
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 Universidad China de Hong Kong * Contribución igual # Líder del proyecto
Los conjuntos de datos de video juegan un papel crucial en la generación de videos como Sora. Sin embargo, los conjuntos de datos de texto y vídeo existentes a menudo se quedan cortos cuando se trata de manejar secuencias de vídeo largas y capturar transiciones de tomas . Para abordar estas limitaciones, presentamos MiraData , un conjunto de datos de video diseñado específicamente para tareas largas de generación de videos. Además, para evaluar mejor la coherencia temporal y la intensidad del movimiento en la generación de vídeo, presentamos MiraBench , que mejora los puntos de referencia existentes añadiendo coherencia 3D y métricas de intensidad del movimiento basadas en el seguimiento. Puede encontrar más detalles en nuestro artículo de investigación.
Lanzamos cuatro versiones de MiraData, que contienen datos de 330K, 93K, 42K y 9K.
El metaarchivo para esta versión de MiraData se proporciona en Google Drive y HuggingFace Dataset. Además, para una mejor y más rápida comprensión de la composición de nuestros metaarchivos, tomamos muestras aleatorias de un conjunto de 100 videoclips, a los que se puede acceder aquí. El metaarchivo contiene la siguiente información de índice:
{download_id}.{clip_id}Para descargar los videos y dividirlos en clips, comience descargando los metaarchivos de Google Drive o HuggingFace Dataset. Una vez que tenga los metaarchivos, puede utilizar los siguientes scripts para descargar los ejemplos de vídeo:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Eliminaremos las muestras de vídeo de nuestro conjunto de datos/Github/página web del proyecto siempre que lo necesite. Por favor contáctenos para la solicitud.
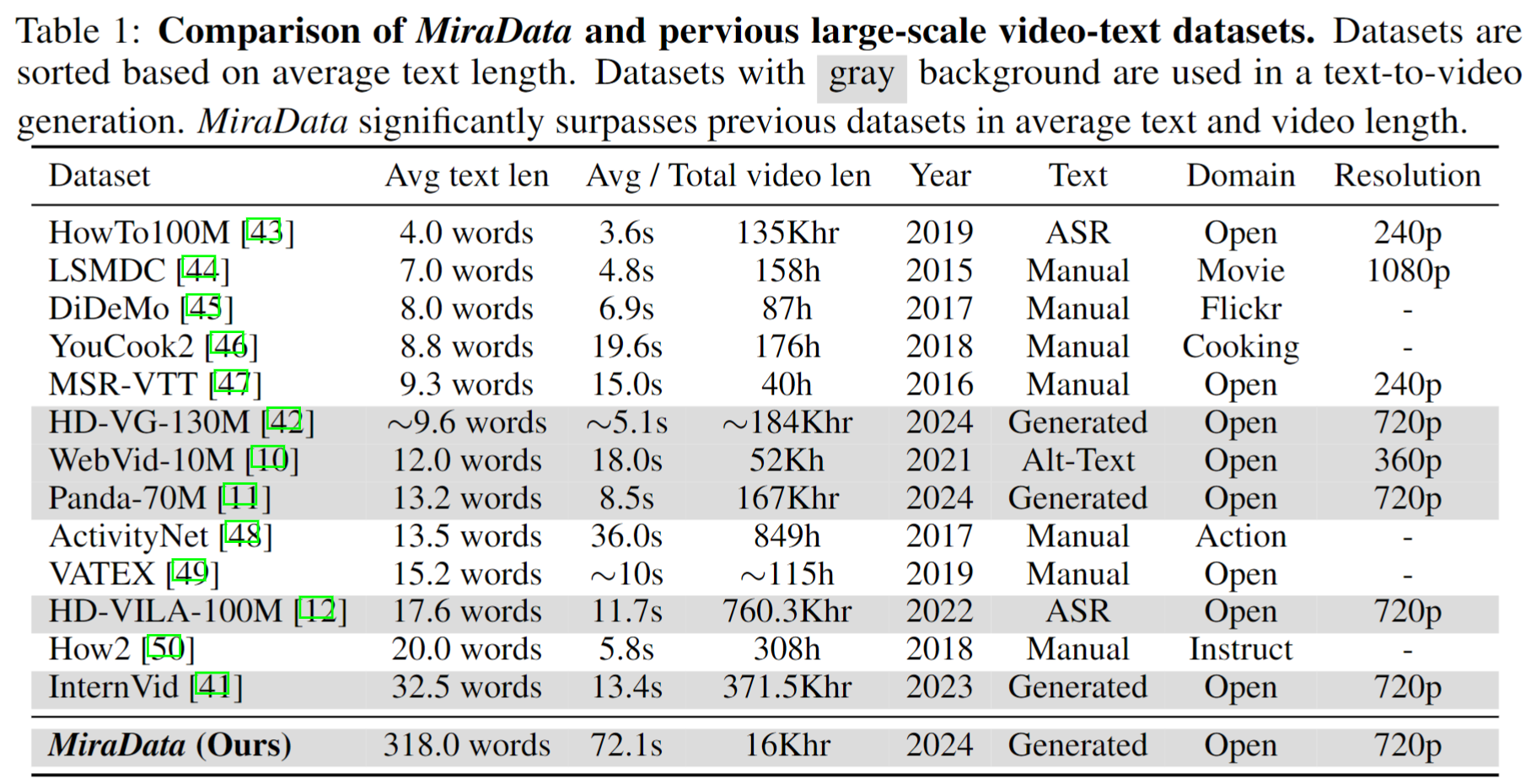
Para recopilar MiraData, primero seleccionamos manualmente los canales de YouTube en diferentes escenarios e incluimos videos de HD-VILA-100M, Videovo, Pixabay y Pexels. Luego, todos los videos en los canales correspondientes se descargan y dividen usando PySceneDetect. Luego utilizamos varios modelos para unir los clips cortos y filtrar los videos de baja calidad. A continuación, seleccionamos videoclips de larga duración. Finalmente, subtitulamos todos los videoclips usando GPT-4V.

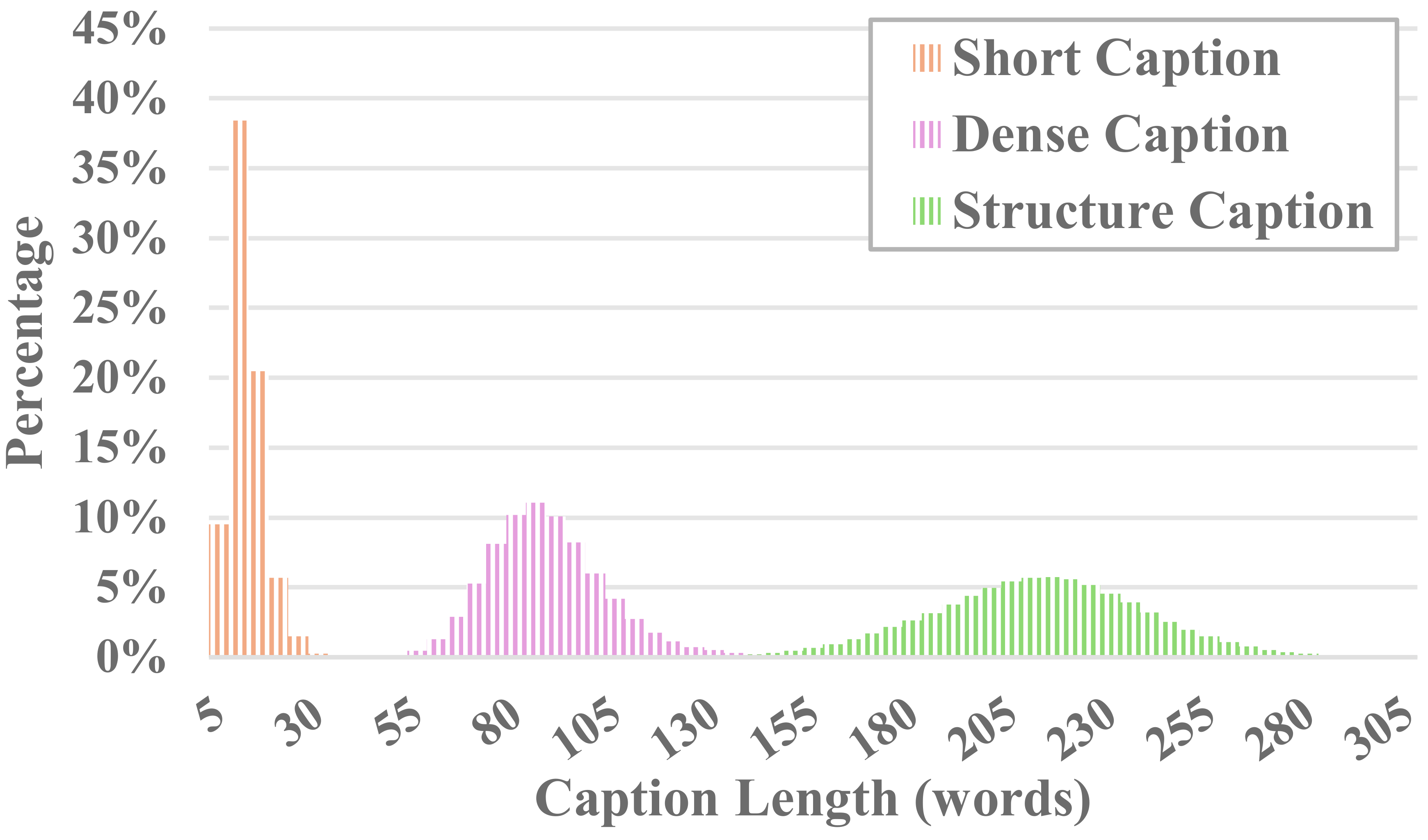
Cada vídeo de MiraData va acompañado de subtítulos estructurados. Estos subtítulos proporcionan descripciones detalladas desde varias perspectivas, mejorando la riqueza del conjunto de datos.
Seis tipos de subtítulos
Probamos los métodos LLM visuales de código abierto existentes y GPT-4V, y descubrimos que los subtítulos de GPT-4V muestran una mayor precisión y coherencia en la comprensión semántica en términos de secuencia temporal.
Para equilibrar los costos de anotación y la precisión de los subtítulos, tomamos muestras uniformes de 8 cuadros para cada video y los organizamos en una cuadrícula de 2x4 de una imagen grande. Luego, utilizamos el modelo de subtítulos de Panda-70M para anotar cada video con un subtítulo de una oración, que sirve como pista para el contenido principal, y lo ingresamos en nuestro mensaje optimizado. Al enviar el mensaje ajustado y una imagen grande de 2x4 a GPT-4V, podemos generar subtítulos de manera eficiente para múltiples dimensiones en una sola ronda de conversación. El contenido del mensaje específico se puede encontrar en caption_gpt4v.py, y invitamos a todos a contribuir a obtener datos de texto y video de mayor calidad. ?

Para evaluar la generación de videos largos, diseñamos 17 métricas de evaluación en MiraBench desde 6 perspectivas, incluida la consistencia temporal, la intensidad del movimiento temporal, la consistencia 3D, la calidad visual, la alineación de texto y video y la consistencia de la distribución. Estas métricas abarcan la mayoría de los estándares de evaluación comunes utilizados en modelos de generación de video anteriores y puntos de referencia de texto a video.
Para evaluar los videos generados, primero configure el entorno Python a través de:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Luego, ejecute la evaluación a través de:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Puede seguir el ejemplo en data/evaluation_example para evaluar sus propios videos generados.
Por favor consulte LICENCIA.
Si encuentra que este proyecto es útil para su investigación, cite nuestro artículo. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
Para cualquier consulta, envíe un correo electrónico [email protected] .
MiraData está bajo la licencia GPL-v3 y es compatible con uso comercial. Si necesita una licencia comercial para MiraData, no dude en contactarnos.


