storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| Vista previa de la investigación | Papel TORMENTA | Papel Co-TORMENTA | Sitio web |
Últimas noticias
[2024/09] La base de código de Co-STORM ya se lanzó y se integra en el paquete Python knowledge-storm v1.0.0. Ejecute pip install knowledge-storm --upgrade para comprobarlo.
[2024/09] ¡Presentamos la colaboración STORM (Co-STORM) para apoyar la curación colaborativa de conocimientos entre humanos y IA! El artículo Co-STORM ha sido aceptado en la conferencia principal de EMNLP 2024.
[2024/07] ¡Ahora puede instalar nuestro paquete con pip install knowledge-storm !
[2024/07] Agregamos VectorRM para admitir la base de datos en documentos proporcionados por el usuario, complementando el soporte existente de los motores de búsqueda ( YouRM , BingSearch ). (mira el n.° 58)
[2024/07] Lanzamos una versión de demostración ligera para desarrolladores, una interfaz de usuario mínima creada con un marco optimizado en Python, útil para el desarrollo local y el alojamiento de demostraciones (consulte n.° 54)
[2024/06] ¡Presentaremos STORM en NAACL 2024! Encuéntranos en la Sesión de Pósteres 2 el 17 de junio o consulta nuestro material de presentación.
[2024/05] Agregamos compatibilidad con Bing Search en rm.py. Pruebe STORM con GPT-4o : ahora configuramos la parte de generación de artículos en nuestra demostración usando el modelo GPT-4o .
[2024/04] ¡Lanzamos una versión refactorizada del código base de STORM! Definimos la interfaz para la canalización STORM y reimplementamos STORM-wiki (consulte src/storm_wiki ) para demostrar cómo crear una instancia de la canalización. Proporcionamos API para admitir la personalización de diferentes modelos de lenguaje y la integración de recuperación/búsqueda.
Si bien el sistema no puede producir artículos listos para su publicación que a menudo requieren una cantidad significativa de ediciones, los editores experimentados de Wikipedia lo han encontrado útil en su etapa previa a la escritura.
Más de 70.000 personas han probado nuestra vista previa de investigación en vivo. Pruébelo para ver cómo STORM puede ayudarlo en su viaje de exploración de conocimientos y envíenos sus comentarios para ayudarnos a mejorar el sistema.
STORM divide la generación de artículos largos con citas en dos pasos:
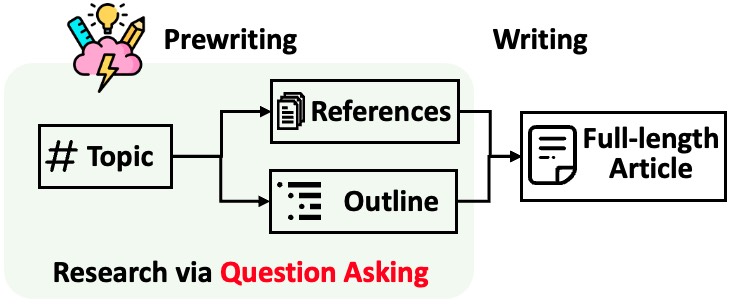
STORM identifica que el núcleo de la automatización del proceso de investigación es generar automáticamente buenas preguntas para hacer. Solicitar directamente al modelo de lenguaje que haga preguntas no funciona bien. Para mejorar la profundidad y amplitud de las preguntas, STORM adopta dos estrategias:
Co-STORM propone un protocolo de discurso colaborativo que implementa una política de gestión de turnos para respaldar una colaboración fluida entre
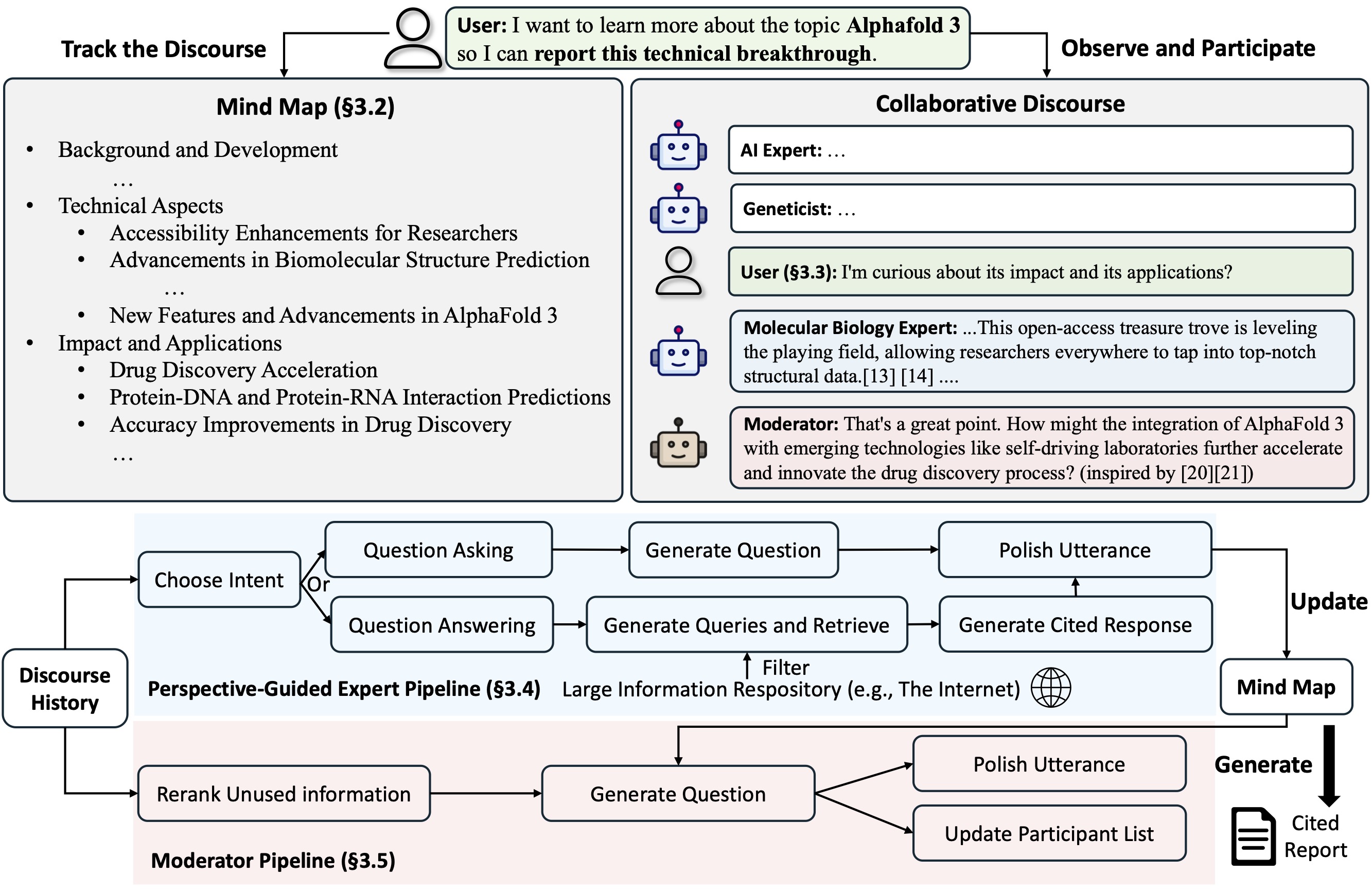
Co-STORM también mantiene un mapa mental dinámico y actualizado, que organiza la información recopilada en una estructura conceptual jerárquica, con el objetivo de construir un espacio conceptual compartido entre el usuario humano y el sistema . Se ha demostrado que el mapa mental ayuda a reducir la carga mental cuando el discurso es largo y profundo.
Tanto STORM como Co-STORM se implementan de forma altamente modular utilizando dspy.
Para instalar la biblioteca de Knowledge Storm, utilice pip install knowledge-storm .
También puedes instalar el código fuente que te permite modificar el comportamiento del motor STORM directamente.
Clona el repositorio de git.
git clone https://github.com/stanford-oval/storm.git
cd stormInstale los paquetes necesarios.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtActualmente, nuestro paquete admite:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel como componentes del modelo de lenguajeYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch y AzureAISearch como componentes del módulo de recuperación? ¡Se agradecen mucho las relaciones públicas por integrar más modelos de lenguaje en Knowledge_storm/lm.py y motores de búsqueda/retrievers en Knowledge_storm/rm.py!
Tanto STORM como Co-STORM están trabajando en la capa de curación de información, es necesario configurar el módulo de recuperación de información y el módulo de modelo de lenguaje para crear sus clases Runner respectivamente.
El motor de curación de conocimientos STORM se define como una clase simple de Python STORMWikiRunner . A continuación se muestra un ejemplo del uso del motor de búsqueda You.com y los modelos OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) La instancia STORMWikiRunner se puede evocar con el método run simple:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : si es Verdadero, simula conversaciones con diferentes perspectivas para recopilar información sobre el tema; de lo contrario, cargue los resultados.do_generate_outline : si es Verdadero, genera un esquema para el tema; de lo contrario, cargue los resultados.do_generate_article : si es Verdadero, genera un artículo para el tema basado en el esquema y la información recopilada; de lo contrario, cargue los resultados.do_polish_article : si es Verdadero, pule el artículo agregando una sección de resumen y (opcionalmente) eliminando contenido duplicado; de lo contrario, cargue los resultados. El motor de curación de conocimientos Co-STORM se define como una clase simple de Python CoStormRunner . A continuación se muestra un ejemplo del uso del motor de búsqueda Bing y modelos OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) La instancia CoStormRunner se puede evocar con los métodos warmstart() y step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Proporcionamos scripts en nuestra carpeta de ejemplos como inicio rápido para ejecutar STORM y Co-STORM con diferentes configuraciones.
Sugerimos usar secrets.toml para configurar las claves API. Cree un archivo secrets.toml en el directorio raíz y agregue el siguiente contenido:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " Para ejecutar STORM con modelos de la familia gpt con configuraciones predeterminadas:
Ejecute el siguiente comando.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articlePara ejecutar STORM utilizando sus modelos de lenguaje favoritos o basándose en su propio corpus: consulte ejemplos/storm_examples/README.md.
Para ejecutar Co-STORM con modelos de la familia gpt con configuraciones predeterminadas,
BING_SEARCH_API_KEY="xxx" y ENCODER_API_TYPE="xxx" a secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingSi ha instalado el código fuente, puede personalizar STORM según su propio caso de uso. El motor STORM consta de 4 módulos:
La interfaz para cada módulo se define en knowledge_storm/interface.py , mientras que sus implementaciones se crean instancias en knowledge_storm/storm_wiki/modules/* . Estos módulos se pueden personalizar según sus requisitos específicos (por ejemplo, generando secciones en formato de viñetas en lugar de párrafos completos).
Si ha instalado el código fuente, puede personalizar Co-STORM según su propio caso de uso.
knowledge_storm/interface.py , mientras que su implementación se crea una instancia en knowledge_storm/collaborative_storm/modules/co_storm_agents.py . Se pueden personalizar diferentes políticas de agentes de LLM.DiscourseManager en knowledge_storm/collaborative_storm/engine.py . Se puede personalizar y mejorar aún más. Para facilitar el estudio de la curación automática de conocimientos y la búsqueda de información compleja, nuestro proyecto publica los siguientes conjuntos de datos:
El conjunto de datos FreshWiki es una colección de 100 artículos de Wikipedia de alta calidad que se centran en las páginas más editadas desde febrero de 2022 hasta septiembre de 2023. Consulte la Sección 2.1 del artículo STORM para obtener más detalles.
Puede descargar el conjunto de datos directamente desde huggingface. Para aliviar el problema de la contaminación de datos, archivamos el código fuente del proceso de construcción de datos que se puede repetir en fechas futuras.
Para estudiar los intereses de los usuarios en tareas complejas de búsqueda de información en la naturaleza, utilizamos datos recopilados de la vista previa de la investigación web para crear el conjunto de datos WildSeek. Redujimos las muestras de los datos para garantizar la diversidad de los temas y la calidad de los datos. Cada punto de datos es un par que comprende un tema y el objetivo del usuario de realizar una búsqueda profunda sobre el tema. Para obtener más detalles, consulte la Sección 2.2 y el Apéndice A del documento Co-STORM.
El conjunto de datos de WildSeek está disponible aquí.
Para experimentos en papel STORM, cambie a la rama NAACL-2024-code-backup aquí.
Para experimentos en papel de Co-STORM, cambie a la rama EMNLP-2024-code-backup (el marcador de posición por ahora se actualizará pronto).
Nuestro equipo está trabajando activamente en:
Si tiene alguna pregunta o sugerencia, no dude en abrir un problema o una solicitud de extracción. ¡Agradecemos contribuciones para mejorar el sistema y el código base!
Persona de contacto: Yijia Shao y Yucheng Jiang
Nos gustaría agradecer a Wikipedia por su excelente contenido de código abierto. El conjunto de datos de FreshWiki proviene de Wikipedia, bajo la licencia Creative Commons Attribution-ShareAlike (CC BY-SA).
Estamos muy agradecidos con Michelle Lam por diseñar el logotipo de este proyecto y con Dekun Ma por liderar el desarrollo de la interfaz de usuario.
Cite nuestro artículo si utiliza este código o parte de él en su trabajo:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

