bulk
1.0.0
Bulk es una herramienta de desarrollo rápida para aplicar algunas etiquetas masivas. Dado un conjunto de datos preparado con incrustaciones 2D, puede generar una interfaz que le permite agregar rápidamente algunas anotaciones masivas, aunque menos precisas.
python -m pip install --upgrade pip
python -m pip install bulk
El futuro del volumen es ofrecer widgets que puedan ayudarle en el cuaderno. Por el momento, BaseTextExplorer es el principal widget compatible. Dados algunos datos preprocesados, puede utilizar el explorador para explorar un UMAP 2D de incrustaciones de texto.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Para usar el widget, sólo necesitas ejecutar esto:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Esto nos permitirá explorar rápidamente los clusters que aparecen en nuestros datos. Puede mantener presionado el cursor del mouse para ingresar al modo de selección y cuando seleccione elementos verá aparecer un subconjunto aleatorio a la derecha. Puede volver a muestrear su selección haciendo clic en el botón volver a muestrear.
Cuando realiza selecciones, puede ver el widget en la actualización correcta, pero también puede obtener los datos de un atributo de Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeSer capaz de explorar estos grupos es genial, pero parece que podríamos explorarlo todo más fácilmente si tuviéramos más herramientas a nuestra disposición. En particular, queremos tener un codificador disponible para poder utilizar consultas en nuestro espacio integrado. La interfaz de usuario a continuación nos permitirá explorar de manera mucho más interactiva actualizando los colores con un mensaje de texto.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Gracias a herramientas como ipywidget y anywidget, realmente podemos comenzar a crear algunas herramientas para que la computadora portátil sea el lugar al que acudir para sus necesidades de datos. Con algunos widgets adecuados, ¡nunca podrás superar a un cuaderno Jupyter!
El interés principal de este proyecto es trabajar en herramientas para la calidad de los datos. Poder seleccionar puntos de datos de forma masiva parece un excelente punto de partida. Tal vez puedas encontrar un subconjunto interesante para anotar primero, tal vez te sorprendas cuando veas dos grupos distintos que deberían ser uno. ¡Todas esas cosas buenas pueden suceder en el cuaderno!
Bulk también viene con una pequeña aplicación web que utiliza Bokeh para brindarle interfaces de anotación basadas en representaciones UMAP de incrustaciones. Ofrece una interfaz para texto. Esta interfaz fue la interfaz/característica original de este proyecto.
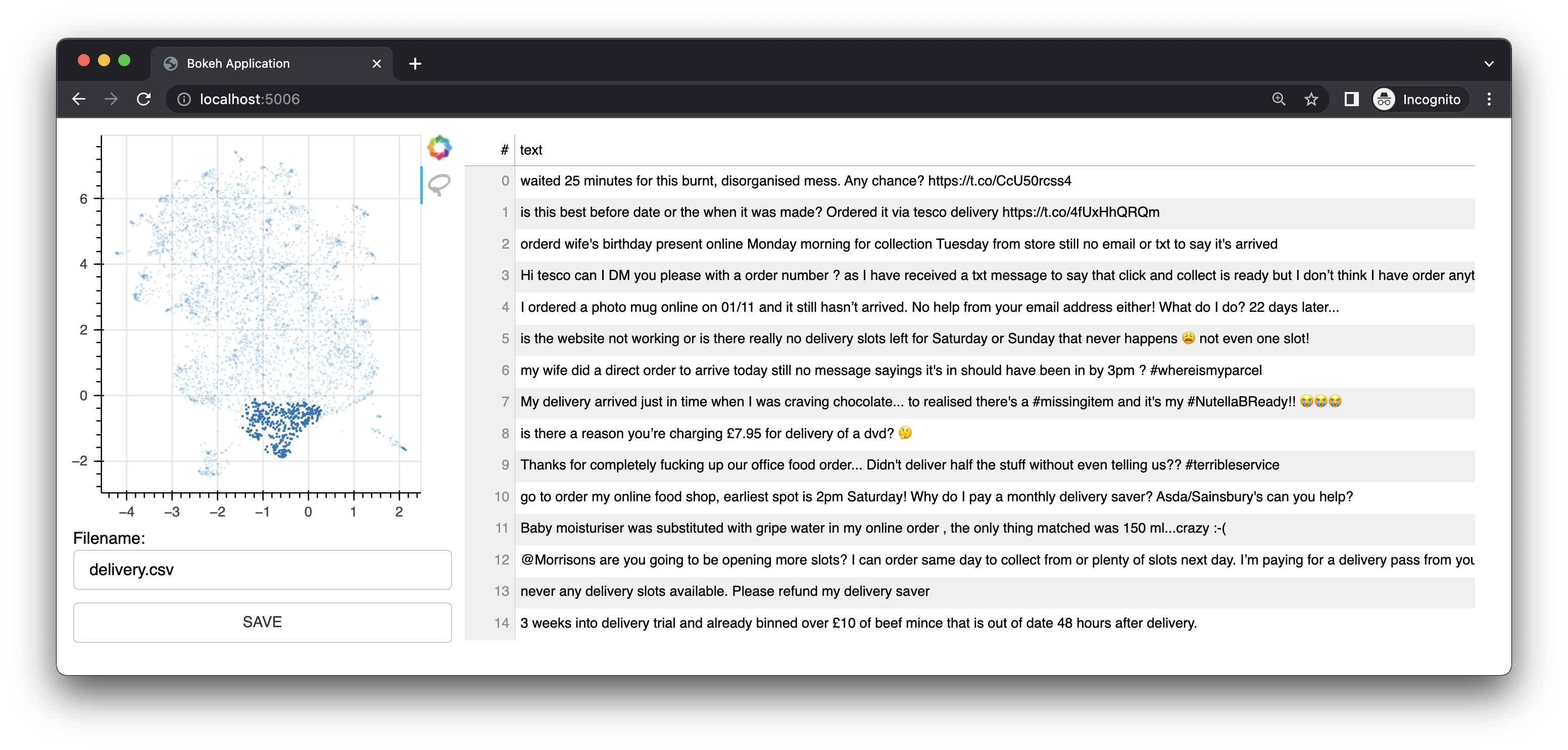
También cuenta con una interfaz de imágenes.
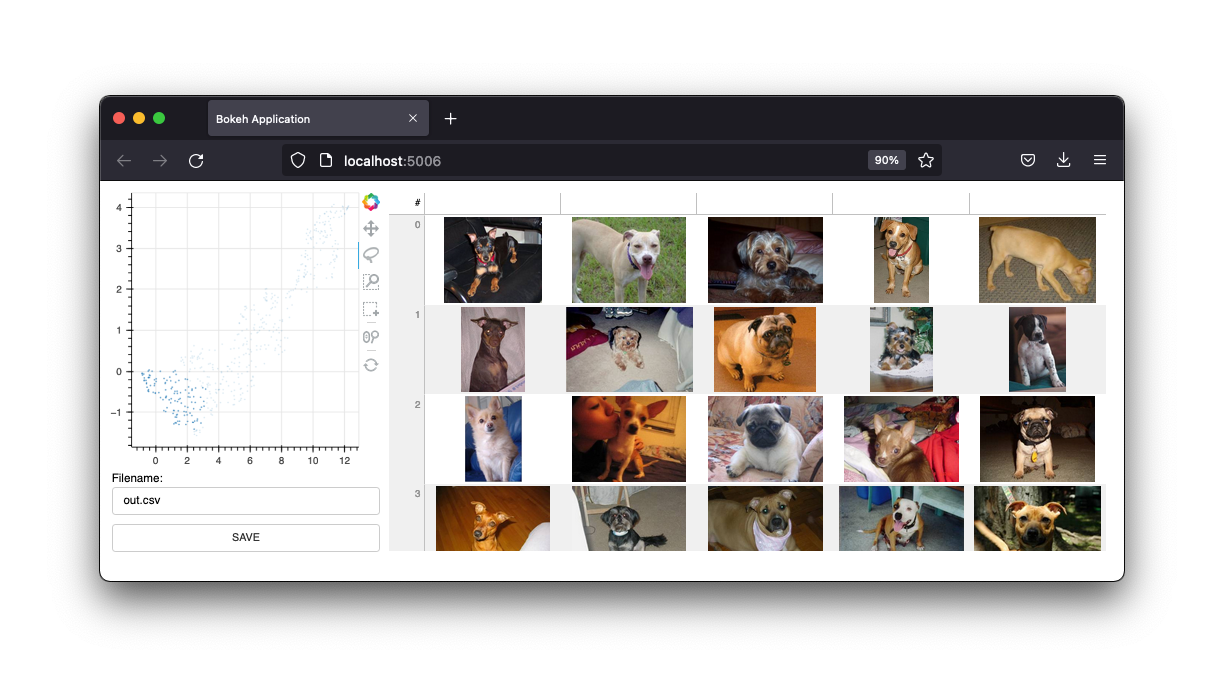
Mantendremos estas interfaces, pero el futuro de este proyecto serán los widgets de una computadora portátil Jupyter. Sin embargo, la aplicación web sigue siendo útil.
Si tiene curiosidad por obtener más información, puede apreciar este video en YouTube para texto y este video en YouTube para visión por computadora.
Para usar texto en masa, primero deberá preparar un archivo csv.
Nota
El siguiente ejemplo utiliza embetter para generar las incrustaciones y umap para reducir las dimensiones. Pero eres totalmente libre de utilizar cualquier herramienta de incrustación de texto que desees. Deberá instalar estas herramientas por separado. Tenga en cuenta que embetter utiliza transformadores de oraciones bajo el capó.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Ahora puede utilizar este archivo ready.csv para aplicar algunas etiquetas masivas.
python -m bulk text ready.csv
Si está buscando un archivo de ejemplo para jugar, puede descargar el archivo .csv de demostración en este repositorio. Este conjunto de datos contiene un subconjunto de un conjunto de datos que se encuentra en Kaggle. Puedes encontrar el original aquí.
También puedes pasar una columna adicional a tu archivo csv llamada "color". Esta columna luego se usará para colorear los puntos en la interfaz.
También puedes pasar --keywords a la aplicación de línea de comando para resaltar elementos que contienen palabras clave específicas.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
El siguiente ejemplo utiliza la biblioteca embetter para crear un conjunto de datos para etiquetar imágenes de forma masiva.
Nota
El siguiente ejemplo utiliza embetter para generar las incrustaciones y umap para reducir las dimensiones. Pero eres totalmente libre de utilizar cualquier herramienta de incrustación de texto que desees. Deberá instalar estas herramientas por separado. Tenga en cuenta que embetter utiliza TIMM bajo el capó.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )Esto genera un archivo csv que se puede cargar de forma masiva mediante;
python -m bulk image ready.csv
También puedes generar un conjunto de miniaturas para tus imágenes. Esto puede resultar útil si trabaja con un conjunto de datos grande.
python -m bulk util resize ready.csv ready2.csv temp
Esto creará una carpeta llamada temp con todas las imágenes redimensionadas. Luego puede usar esta carpeta como argumento --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
También puedes usar de forma masiva para descargar algunos conjuntos de datos con los que jugar. Para más información:
python -m bulk download --help
La interfaz puede ayudarle a etiquetar muy rápidamente, pero las etiquetas en sí pueden ser bastante ruidosas. El caso de uso previsto para esta herramienta es preparar subconjuntos interesantes para utilizarlos más adelante en prodi.gy.


