AI Guide and Demos zh_CN
1.0.0
Mirando hacia atrás en el proceso de aprendizaje pasado, los videos de los maestros Ng Enda y Li Hongyi me han brindado una gran ayuda en mi viaje de aprendizaje en profundidad. Sus divertidos métodos de explicación y sus explicaciones sencillas e intuitivas hacen que el aburrido aprendizaje teórico sea animado e interesante.
Sin embargo, en la práctica, muchos estudiantes inicialmente se preocuparán por cómo obtener la API de modelos extranjeros grandes. Aunque eventualmente pueden encontrar una solución, el miedo a las dificultades por primera vez siempre retrasará el progreso del aprendizaje y cambiará gradualmente. de “solo mirar el video”. A menudo veo discusiones similares en el área de comentarios, así que decidí usar mi tiempo libre para ayudar a los estudiantes a cruzar este umbral. Esta es también la intención original del proyecto.
Este proyecto no proporcionará tutoriales sobre el acceso científico a Internet ni se basará en interfaces personalizadas para la plataforma. En cambio, utilizará el SDK de OpenAI, más compatible, para ayudar a todos a adquirir conocimientos más generales.
El proyecto comenzará con llamadas API simples y lo llevará gradualmente al mundo de los modelos grandes. En el proceso, dominará habilidades como el resumen de videos con IA , el ajuste fino de LLM y la generación de imágenes con IA .
Se recomienda encarecidamente ver el curso del profesor Li Hongyi "Introducción a la inteligencia artificial generativa" para el aprendizaje simultáneo: acceso rápido a enlaces relacionados con el curso.
Ahora, el proyecto también ofrece CodePlayground. Puede configurar el entorno de acuerdo con la documentación, ejecutar el script con una línea de código y experimentar el encanto de la IA.
?Los ensayos de tesis se encuentran en PaperNotes y los artículos básicos relacionados con modelos grandes se cargarán gradualmente.
La imagen básica está lista. Si no ha configurado su propio entorno de aprendizaje profundo, también puede probar Docker.
¡Buen viaje!
--- : Conocimientos básicos, mírelo según sea necesario o sáltelo temporalmente. Los resultados del archivo de código se mostrarán en el artículo, pero aun así se recomienda ejecutar el código manualmente. Es posible que existan requisitos de memoria de video.API : El artículo solo utiliza la API de modelos grandes, no está sujeto a restricciones de dispositivo y se puede ejecutar sin una GPU.LLM : Práctica relacionada con modelos de lenguaje grandes, los archivos de código pueden tener requisitos de memoria de video.SD : Difusión Estable, una práctica relacionada con los diagramas vicencianos, y los archivos de código tienen requisitos de memoria de vídeo.File y el efecto de aprendizaje será el mismo.Setting -> Accelerator ->选择GPU .代码执行程序->更改运行时类型->选择GPU .| Guía | Etiqueta | Describir | Archivo | En línea |
|---|---|---|---|---|
| 00. Pasos para obtener la API de Alibaba Big Model | API | Te llevaremos paso a paso para obtener la API. Si es la primera vez que te registras, debes realizar una verificación de identidad (reconocimiento facial). | ||
| 01. Primera introducción a LLM API: configuración del entorno y demostración de diálogo de múltiples rondas | API | Esta es una configuración y demostración introductoria. El código de conversación se modifica de los documentos de desarrollo de Alibaba. | Código | Kaggle colaboración |
| 02. Fácil de comenzar: cree aplicaciones de IA a través de API y Gradio | API | Guía sobre cómo utilizar Gradio para crear una aplicación de IA sencilla. | Código | colaboración |
| 03. Guía avanzada: Personalice el mensaje para mejorar las capacidades de resolución de problemas de modelos grandes | API | Aprenderá a personalizar un mensaje para mejorar la capacidad de modelos grandes para resolver problemas matemáticos. También se proporcionarán versiones Gradio y no Gradio, y se mostrarán los detalles del código. | Código | Kaggle colaboración |
| 04. Entendiendo LoRA: de la capa lineal al mecanismo de atención | --- | Antes de comenzar oficialmente a practicar, necesita conocer los conceptos básicos de LoRA. Este artículo lo llevará desde la implementación de LoRA de capa lineal hasta el mecanismo de atención. | ||
05. Comprenda la serie AutoModel de Hugging Face: clases de carga automática de modelos para diferentes tareas | --- | El módulo que vamos a utilizar es AutoModel en Hugging Face. Este artículo también es un requisito previo (por supuesto, puede omitirlo y leerlo más tarde cuando tenga dudas). | Código | Kaggle colaboración |
| 06. Comience: implemente su modelo de primer idioma | LLM | Al implementar un modelo de lenguaje muy básico, el proyecto no tiene requisitos estrictos para GPU hasta el momento, puede continuar aprendiendo. | Código app_fastapi.py app_flask.py | |
| 07. Explore la relación entre los parámetros del modelo y la memoria de video y el impacto de diferentes precisiones. | --- | Comprender la correspondencia entre los parámetros del modelo y la memoria de video y dominar los métodos de importación de diferentes precisiones hará que su selección de modelo sea más hábil. | ||
| 08. Intente perfeccionar el LLM: déjelo escribir poesía Tang | LLM | Este artículo es el mismo que 03. Guía avanzada: Personalización del mensaje para mejorar las capacidades de resolución de problemas de modelos grandes. Básicamente se centra en "usar" en lugar de "escribir". Puede comprender el proceso general como antes. sección de hiperparámetros para ver el impacto en el ajuste fino. | Código | Kaggle colaboración |
| 09. Comprensión profunda de Beam Search: principios, ejemplos e implementación de código | --- | Pasar de ejemplos a demostraciones de código, explicar las matemáticas de Beam Search, esto debería aclarar cierta confusión de la lectura anterior y, finalmente, proporcionar un ejemplo simple del uso de la biblioteca Hugging Face Transformers (puede probarla si se saltó el artículo anterior). . | Código | Kaggle colaboración |
| 10. Top-K vs Top-P: estrategia de muestreo y la influencia de la temperatura en modelos generativos | --- | Además, para mostrarle otras estrategias de generación. | Código | Kaggle colaboración |
| 11. Ejemplo de ajuste fino de DPO: optimización del modelo de lenguaje grande LLM según las preferencias humanas | LLM | Un ejemplo de ajuste fino usando DPO. | Código | Kaggle colaboración |
| 12. Atribución de funciones de Inseq: interprete visualmente el resultado de LLM | LLM | Ejemplos visuales de tareas de traducción y generación de texto (completar espacios en blanco). | Código | Kaggle colaboración |
| 13. Comprender los posibles sesgos en la IA | LLM | No es necesario comprender el código y puede utilizarse como una exploración divertida durante el tiempo libre. | Código | Kaggle colaboración |
| 14. PEFT: aplique LoRA rápidamente a modelos grandes | --- | Aprenda cómo agregar capas LoRA después de importar el modelo. | Código | Kaggle colaboración |
| 15. Utilice API para implementar un resumen de video de IA: cree su propio asistente de video de IA | API y LLM | Aprenderá los principios detrás de los asistentes de resumen de video de IA comunes y comenzará a implementar el resumen de video de IA. | Código - versión completa Código - Versión Lite ?guion | Kaggle colaboración |
| 16. Utilice LoRA para ajustar la difusión estable: desmonte el horno de alquimia e implemente su primera pintura de IA | DAKOTA DEL SUR | Utilice LoRA para ajustar el modelo de diagrama de Vincent y ahora también podrá proporcionar sus archivos LoRA a otras personas. | Código Código - Versión Lite | Kaggle colaboración |
| 17. Una breve discusión sobre la cuantificación del modelo RTN: asimétrico versus simétrico.md | --- | Para comprender mejor el comportamiento de cuantificación del modelo RTN, este artículo utiliza INT8 como ejemplo para explicarlo. | Código | Kaggle colaboración |
| 18. Descripción general de la tecnología de cuantificación de modelos y análisis del formato de archivo GGUF/GGML | --- | Este es un artículo de descripción general que puede resolver algunas de sus dudas al usar GGUF/GGML. | ||
| 19a De la carga a la conversación: ejecutar modelos grandes LLM cuantificados (GPTQ y AWQ) localmente usando Transformers. 19b De la carga a la conversación: ejecutar modelos grandes LLM cuantificados (GGUF) localmente usando Llama-cpp-python. | LLM | Implementará un modelo cuantitativo con 7 mil millones (7B) de parámetros en su computadora. Tenga en cuenta que este artículo no requiere una tarjeta gráfica. 19 a Uso de Transformers, que implica la carga de modelos en formatos GPTQ y AWQ. 19 b Usando Llama-cpp-python, involucrando la carga del modelo en formato GGUF. Además, también completará la función de interacción de diálogo de modelo grande local. | Transformadores de código Código-Llama-cpp-python ?guion | |
| 20. Práctica introductoria de RAG: desde la división de documentos hasta la base de datos vectorial y la construcción de preguntas y respuestas | LLM | Prácticas relacionadas con RAG. Descubra cómo funciona la fragmentación recursiva de texto. | Código | |
| 21. BPE vs WordPiece: comprenda el principio de funcionamiento de Tokenizer y el método de segmentación de subpalabras | --- | Operaciones básicas de Tokenizer. Conozca los métodos comunes de segmentación de subpalabras: BPE y WordPieza. Comprenda la máscara de atención (Máscara de atención) y los ID de tipo de token (ID de tipo de token). | Código | Kaggle colaboración |
| 22. Tarea: Bert perfecciona la respuesta a preguntas extractivas | Esta es una tarea que utiliza BERT para ajustar las tareas posteriores de preguntas y respuestas. Puede probarla e intentar unirse a la "competencia" de Kaggle. Después de una semana, se le proporcionará un artículo guía con todos los consejos. o déjalo para más tarde. El artículo introductorio no cubrirá la descripción de la tarea y se cargarán dos versiones del código para aprender, así que no se preocupe. Aquí no habrá fecha límite. | Código - Asignación | Kaggle colaboración |
Consejo
Si prefiere extraer el almacén para leer .md localmente, cuando se produzca un error de fórmula, utilice Ctrl+F o Command+F , busque \_ y reemplace todo con _ .
Lectura adicional:
| Guía | Describir |
|---|---|
| a Utilice HFD para acelerar la descarga de modelos y conjuntos de datos de Hugging Face. | Si cree que la descarga del modelo es demasiado lenta, puede consultar este artículo para configurarlo. Si encuentra errores 443 relacionados con el proxy, también puede intentar consultar este artículo. |
| b. Comprobación rápida de los comandos básicos de la línea de comandos (aplicable a Linux/Mac) | Una verificación rápida de comandos de línea de comando básicamente contiene todos los comandos involucrados en el almacén actual. Compruébelo cuando esté confundido. |
| c. Soluciones a algunos problemas | Aquí resolveremos algunos problemas que pueden surgir durante la operación del proyecto. - ¿Cómo extraer el almacén remoto para sobrescribir todas las modificaciones locales? - ¿Cómo ver y eliminar archivos descargados por Hugging Face y cómo modificar la ruta de guardado? |
| d. Cómo cargar el modelo GGUF (solución para Shared/Shared/Split/00001-of-0000...) | - Conoce las nuevas características de Transformers sobre GGUF. - Utilice Transformers/Llama-cpp-python/Ollama para cargar archivos de modelo en formato GGUF. - Aprenda a fusionar archivos GGUF fragmentados. - Resuelve el problema de que LLama-cpp-python no se puede descargar. |
| e. Mejora de datos: análisis de métodos comunes de torchvision.transforms | - Comprender los métodos de mejora de datos de imágenes comúnmente utilizados. Código | |
| f Función de pérdida de entropía cruzada nn.CrossEntropyLoss() explicación detallada y recordatorio de puntos clave (PyTorch) | - Comprender los principios matemáticos de la pérdida de entropía cruzada y la implementación de PyTorch. - Aprenda a qué prestar atención al usarlo por primera vez. |
| g.Incrustar capa nn.Embedding() explicación detallada y recordatorio de puntos clave (PyTorch) | - Comprender los conceptos de incrustación de capas e incrustación de palabras. - Visualice la incrustación utilizando modelos previamente entrenados. Código | |
| h. Utilice Docker para configurar rápidamente el entorno de aprendizaje profundo (Linux). h. Introducción a los comandos básicos de Docker y resolución de errores comunes. | - Utilice dos líneas de comandos para configurar el entorno de aprendizaje profundo. - Introducción a los comandos básicos de Docker - Resuelve tres errores comunes durante el uso. |
Explicación de la carpeta:
Población
Todos los archivos de código se almacenarán allí.
datos
No es necesario prestar atención a esta carpeta para almacenar pequeños datos que pueden usarse en el código.
GenAI_PDF
Aquí están los archivos PDF de las tareas del curso [Introducción a la Inteligencia Artificial Generativa]. Los subí porque originalmente estaban guardados en Google Drive.
Guía
Todos los documentos de orientación se almacenarán allí.
activos
Aquí están las imágenes utilizadas en el archivo .md. No es necesario prestar atención a esta carpeta.
Notas de papel
Ensayo de tesis.
Código de juegos
Algunos ejemplos interesantes de scripts de código (versión Toy).
LÉAME.md
resumen.py?script
Resumen de vídeo/audio/subtítulos con IA.
chat.py?script
Conversación de IA.
Introducción a los recursos de aprendizaje de inteligencia artificial generativa
Página de inicio del curso
Vídeo oficial | Autorizado: YouTube |
La producción y el intercambio de la versión en espejo chino han sido autorizados por el maestro Li Hongyi. ¡Gracias al maestro por compartir desinteresadamente sus conocimientos!
La imagen china de PD realizará completamente todas las funciones del código de trabajo (operación local). Kaggle es una plataforma en línea que se puede conectar directamente en China. El contenido de Colab chino y Kaggle es el mismo que el del trabajo original. Simplemente elija uno de ellos para completar el estudio.
Según las necesidades reales, seleccione un método a continuación para preparar el entorno de aprendizaje, haga clic en ► o envíe un mensaje de texto para expandir .
Kaggle (conexión directa nacional, recomendada): lea el artículo "Kaggle: Guía gratuita de uso de GPU, una alternativa ideal a Colab" para obtener más información.
Colab (requiere acceso científico a Internet)
Los archivos de código del proyecto están sincronizados en ambas plataformas.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install gitMacOS :
Instale Homebrew primero:
/bin/bash -c " $( curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh ) "Luego ejecuta:
brew install gitVentanas :
Descargue e instale desde Git para Windows.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install wget curlMacOS :
brew install wget curlVentanas :
Descargue e instale desde los sitios web oficiales de Wget para Windows y Curl.
Visite el sitio web oficial de Anaconda, ingrese su dirección de correo electrónico y verifique su correo electrónico. Debería poder ver:
Haga clic en Download Now , seleccione la versión adecuada y descárguela (tanto Anaconda como Miniconda están disponibles):

Linux (Ubuntu) :
Instalar Anaconda
Visite repo.anaconda.com para seleccionar la versión.
# 下载 Anaconda 安装脚本(以最新版本为例)
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda3-2024.10-1-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcInstalar Miniconda (recomendado)
Visite repo.anaconda.com/miniconda para seleccionar la versión. Miniconda es una versión simplificada de Anaconda, que contiene solo Conda y Python.
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcMacOS :
Reemplace correspondientemente la URL en el comando de Linux.
Instalar Anaconda
Visite repo.anaconda.com para seleccionar la versión.
Instalar Miniconda (recomendado)
Visite repo.anaconda.com/miniconda para seleccionar la versión.
Ingrese el siguiente comando en la terminal. Si se muestra la información de la versión, la instalación se realizó correctamente.
conda --versioncat << ' EOF ' > ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirror.nju.edu.cn/anaconda/pkgs/main
- https://mirror.nju.edu.cn/anaconda/pkgs/r
- https://mirror.nju.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirror.nju.edu.cn/anaconda/cloud
pytorch: https://mirror.nju.edu.cn/anaconda/cloud
EOF[!nota]
Muchas fuentes espejo que estaban disponibles el año pasado ya no lo están. Para la configuración actual de otros sitios espejo, puede consultar este excelente documento de NTU: Ayuda sobre el uso de espejos.
Nota : Si Anaconda o Miniconda ya están instalados, se incluirá pip en el sistema y no se requiere instalación adicional.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install python3-pipMacOS :
brew install python3Ventanas :
Descargue e instale Python, asegurándose de que la opción "Agregar Python a PATH" esté marcada.
Abra un símbolo del sistema e ingrese:
python -m ensurepip --upgradeIngrese el siguiente comando en la terminal. Si se muestra la información de la versión, la instalación se realizó correctamente.
pip --versionpip config set global.index-url https://mirrors.aliyun.com/pypi/simpleTire del proyecto con el siguiente comando:
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNNo hay límite de versión, puede ser superior:
conda create -n aigc python=3.9 Presione y e ingrese para continuar. Una vez completada la creación, active el entorno virtual:
conda activate aigcA continuación, debe instalar las dependencias básicas. Consulte el sitio web oficial de PyTorch, tomando CUDA 11.8 como ejemplo (si la tarjeta gráfica no es compatible con 11.8, debe cambiar el comando), elija uno de los dos para instalar:
# pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# conda
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaAhora hemos configurado con éxito todos los entornos necesarios y estamos listos para comenzar a aprender :) Las dependencias restantes se enumerarán por separado en cada artículo.
[!nota]
Las imágenes de Docker tienen dependencias preinstaladas, por lo que no es necesario reinstalarlas.
Primero instale jupyter-lab , que es mucho más fácil de usar que jupyter notebook .
pip install jupyterlabUna vez completada la instalación, ejecute el siguiente comando:
jupyter-lab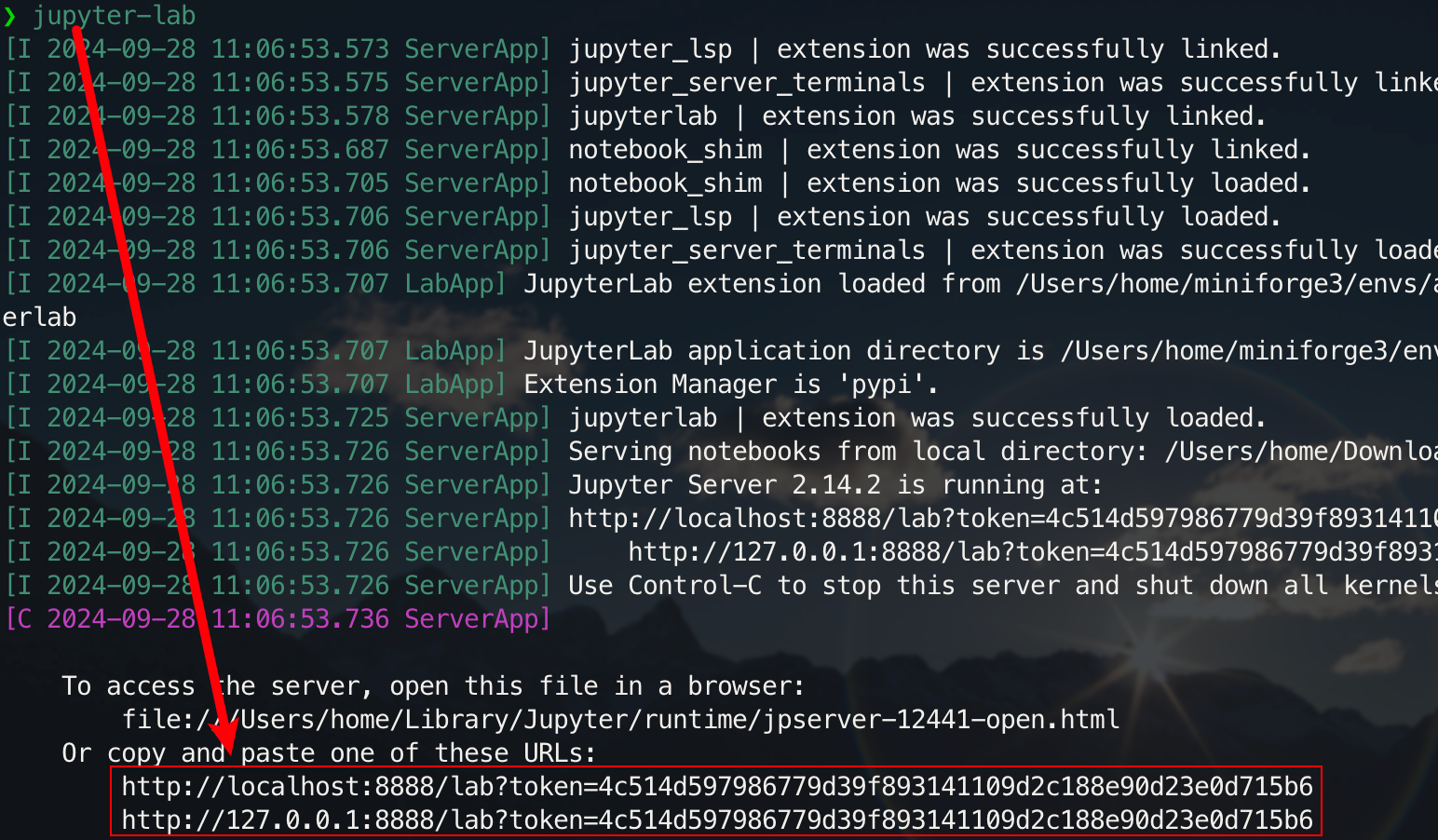
Ahora podrás acceder a él a través del enlace emergente, normalmente ubicado en el puerto 8888. Para la interfaz gráfica, mantenga presionada Ctrl en Windows/Linux, mantenga presionada la tecla Command en Mac y luego haga clic en el enlace para saltar directamente. En este punto, obtendrá la imagen completa del proyecto:
Los estudiantes que no hayan instalado Docker pueden leer el artículo "Utilice Docker para configurar rápidamente un entorno de aprendizaje profundo (Linux)". Se recomienda a los principiantes que lean "Introducción a los comandos básicos de Docker y resolución de errores comunes".
Todas las versiones vienen preinstaladas con herramientas comunes como sudo , pip , conda , wget , curl y vim , y se han configurado las fuentes de imágenes domésticas de pip y conda . Al mismo tiempo, integra zsh y algunos complementos prácticos de línea de comandos (comandos de autocompletado, resaltado de sintaxis y herramienta de salto de directorio z ). Además, se han preinstalado jupyter notebook y jupyter lab , y el terminal predeterminado está configurado en zsh para facilitar el desarrollo del aprendizaje profundo. La visualización china en el contenedor se ha optimizado para evitar caracteres confusos. La dirección espejo doméstica de Hugging Face también está preconfigurada.
pytorch/pytorch:2.5.1-cuda11.8-cudnn9-devel . La versión predeterminada python es 3.11.10. La versión se puede modificar directamente a través de conda install python==版本号.Instalación adecuada :
wget , curl : herramientas de descarga de línea de comandovim , nano : editor de textogit : herramienta de control de versionesgit-lfs : Git LFS (almacenamiento de archivos grandes)zip , unzip : herramientas de compresión y descompresión de archivoshtop : herramienta de monitoreo del sistematmux , screen : herramientas de gestión de sesionesbuild-essential : herramientas de compilación (como gcc , g++ )iputils-ping , iproute2 , net-tools : herramientas de red (que proporcionan comandos como ping , ip , ifconfig , netstat , etc.)ssh : herramienta de conexión remotarsync : herramienta de sincronización de archivostree : muestra árboles de archivos y directorioslsof : Ver archivos actualmente abiertos en el sistemaaria2 : herramienta de descarga multiprocesolibssl-dev : biblioteca de desarrollo OpenSSLinstalación de pipa :
jupyter notebook , jupyter lab : entorno de desarrollo interactivovirtualenv : herramienta de gestión del entorno virtual de Python, puede utilizar conda directamentetensorboard : herramienta de visualización de entrenamiento de aprendizaje profundoipywidgets : biblioteca de widgets de Jupyter para mostrar las barras de progreso correctamenteComplemento :
zsh-autosuggestions : autocompletado de comandoszsh-syntax-highlighting : resaltado de sintaxisz : salta rápidamente al directorioLa versión dl (Deep Learning) se basa en base y además instala herramientas y bibliotecas básicas que pueden usarse en aprendizaje profundo:
Instalación adecuada :
ffmpeg : herramienta de procesamiento de audio y videolibgl1-mesa-glx : Dependencia de la biblioteca de gráficos (resuelva algunos problemas relacionados con los gráficos del marco de aprendizaje profundo)instalación de pipa :
numpy , scipy : cálculos numéricos y cálculos científicospandas : análisis de datosmatplotlib , seaborn : visualización de datosscikit-learn : herramientas de aprendizaje automáticotensorflow , tensorflow-addons : otro marco popular de aprendizaje profundotf-keras : implementación de TensorFlow de la interfaz Kerastransformers , datasets : herramientas de PNL proporcionadas por Hugging Facenltk , spacy : herramientas de procesamiento del lenguaje naturalSi se necesitan bibliotecas adicionales, se pueden instalar manualmente con el siguiente comando:
pip install --timeout 120 <替换成库名> Aquí --timeout 120 establece un tiempo de espera de 120 segundos para garantizar que todavía haya suficiente tiempo para la instalación incluso si la red es deficiente. Si no lo configura, puede encontrarse con una situación en la que el paquete de instalación falle debido al tiempo de espera de descarga en un entorno doméstico.
Tenga en cuenta que no todas las imágenes extraerán el almacén por adelantado.
Suponiendo que haya instalado y configurado Docker, solo necesita dos líneas de comando para completar la configuración del entorno de aprendizaje profundo. Para el proyecto actual, puede hacer una selección después de ver la descripción de la versión. La image_name:tag correspondiente de las dos es la siguiente. sigue:
hoperj/quickstart:base-torch2.5.1-cuda11.8-cudnn9-develhoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develEl comando de extracción es:
docker pull < image_name:tag >A continuación se utiliza la versión dl como ejemplo para demostrar el comando. Elija uno de los métodos para completar.
docker pull dockerpull.org/hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develdocker pull hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develLos archivos se pueden descargar a través de Baidu Cloud Disk (Alibaba Cloud Disk no admite compartir archivos comprimidos de gran tamaño).
Los archivos con el mismo nombre tienen el mismo contenido.
.tar.gzes una versión comprimida. Después de descargarlo, descomprímalo con el siguiente comando:gzip -d dl.tar.gz
Suponiendo dl.tar se descargue en ~/Downloads , luego cambie al directorio correspondiente:
cd ~ /DownloadsLuego carga la imagen:
docker load -i dl.tarEn este modo, el contenedor utilizará directamente la configuración de red del host y todos los puertos serán iguales a los puertos del host sin una asignación separada. Si solo necesita asignar un puerto específico, reemplace
--network hostcon-p port:port.
docker run --gpus all -it --name ai --network host hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel /bin/zsh Para los estudiantes que necesitan usar un proxy, agregue -e para configurar las variables de entorno. También puede consultar el artículo ampliado a:
Supongamos que el número de puerto HTTP/HTTPS del proxy es 7890 y SOCKS5 es 7891:
-e http_proxy=http://127.0.0.1:7890-e https_proxy=http://127.0.0.1:7890-e all_proxy=socks5://127.0.0.1:7891Integrado en el comando anterior:
docker run --gpus all -it
--name ai
--network host
-e http_proxy=http://127.0.0.1:7890
-e https_proxy=http://127.0.0.1:7890
-e all_proxy=socks5://127.0.0.1:7891
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
/bin/zsh[!consejo]
Consulte con antelación las operaciones habituales :
- Inicie el contenedor :
docker start <容器名>- Ejecute el contenedor :
docker exec -it <容器名> /bin/zsh
- Salir dentro del contenedor :
Ctrl + Doexit.- Detener el contenedor :
docker stop <容器名>- Eliminar un contenedor :
docker rm <容器名>
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNjupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root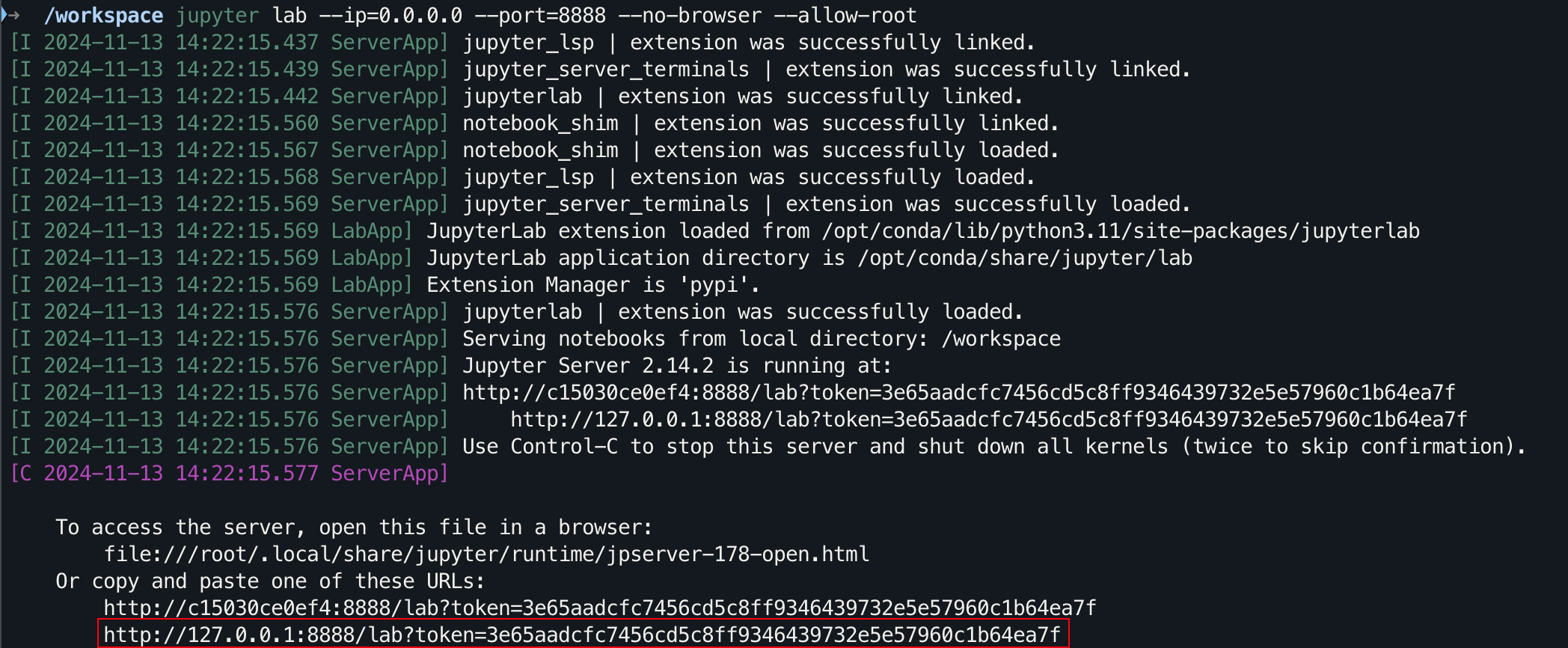
Para la interfaz gráfica, mantenga presionada Ctrl en Windows/Linux, mantenga presionada la tecla Command en Mac y luego haga clic en el enlace para saltar directamente.
¿Gracias por tu ESTRELLA?, espero que esto ayude.


