dsub
Release 0.5.0
dsub es una herramienta de línea de comandos que facilita el envío y ejecución de scripts por lotes en la nube.
La experiencia del usuario dsub se basa en los programadores de trabajos informáticos tradicionales de alto rendimiento como Grid Engine y Slurm. Usted escribe un script y luego lo envía a un programador de trabajos desde un indicador de shell en su máquina local.
Hoy en día, dsub admite Google Cloud como ejecutor de trabajos por lotes de backend, junto con un proveedor local para desarrollo y pruebas. Con la ayuda de la comunidad, nos gustaría agregar otros backends, como Grid Engine, Slurm, Amazon Batch y Azure Batch.
dsub está escrito en Python y requiere Python 3.7 o superior.
dsub 0.4.7.dsub 0.4.1.dsub 0.3.10.Esto es opcional, pero ya sea que instale desde PyPI o desde github, se recomienda encarecidamente utilizar un entorno virtual de Python.
Puede hacer esto en un directorio de su elección.
python3 -m venv dsub_libs
source dsub_libs/bin/activate
El uso de un entorno virtual Python aísla las dependencias de la biblioteca dsub de otras aplicaciones Python en su sistema.
Active este entorno virtual en cualquier sesión de shell antes de ejecutar dsub . Para desactivar el entorno virtual en su shell, ejecute el comando:
deactivate
Alternativamente, se proporciona un conjunto de scripts convenientes que activan virutalenv antes de llamar dsub , dstat y ddel . Están en el directorio bin. Puede utilizar estos scripts si no desea activar virtualenv explícitamente en su shell.
Si bien dsub no lo utiliza directamente para los proveedores google-batch o google-cls-v2 , es probable que desee instalar las herramientas de línea de comandos que se encuentran en el SDK de Google Cloud.
Si va a utilizar el proveedor local para un desarrollo laboral más rápido, deberá instalar el SDK de Google Cloud, que utiliza gsutil para garantizar que la semántica de operación de archivos sea coherente con los proveedores dsub de Google.
Instalar el SDK de Google Cloud
Correr
gcloud init
gcloud te pedirá que configures tu proyecto predeterminado y otorgues credenciales al SDK de Google Cloud.
dsubElija uno de los siguientes:
Si es necesario, instale la tubería.
instalar dsub
pip install dsub
Asegúrate de tener instalado git
Las instrucciones para su entorno se pueden encontrar en el sitio web de git.
Clona este repositorio.
git clone https://github.com/DataBiosphere/dsub
cd dsub
Instale dsub (esto también instalará las dependencias)
python -m pip install .
Configurar la finalización de la pestaña Bash (opcional).
source bash_tab_complete
Verifique mínimamente la instalación ejecutando:
dsub --help
(Opcional) Instale Docker.
Esto solo es necesario si va a crear sus propias imágenes de Docker o utilizar el proveedor local .
Después de clonar el repositorio dsub, también puedes usar Makefile ejecutando:
make
Esto creará un entorno virtual Python e instalará dsub en un directorio llamado dsub_libs .
Creemos que el proveedor local le resultará muy útil a la hora de crear sus tareas dsub . En lugar de enviar una solicitud para ejecutar su comando en una máquina virtual en la nube, el proveedor local ejecuta sus tareas dsub en su máquina local.
El proveedor local no está diseñado para funcionar a escala. Está diseñado para emular la ejecución en una máquina virtual en la nube, de modo que pueda iterar rápidamente. Obtendrá tiempos de respuesta más rápidos y no incurrirá en cargos de nube al usarlo.
Ejecute un trabajo dsub y espere a que se complete.
Aquí hay una prueba muy simple de "Hola mundo":
dsub
--provider local
--logging "${TMPDIR:-/tmp}/dsub-test/logging/"
--output OUT="${TMPDIR:-/tmp}/dsub-test/output/out.txt"
--command 'echo "Hello World" > "${OUT}"'
--wait
Nota: TMPDIR suele estar configurado en /tmp de forma predeterminada en la mayoría de los sistemas Unix, aunque a menudo también se deja sin configurar. En algunas versiones de MacOS, TMPDIR está configurado en una ubicación en /var/folders .
Nota: Se sabe que la sintaxis anterior ${TMPDIR:-/tmp} es compatible con Bash, zsh, ksh. El shell expandirá TMPDIR , pero si no está configurado, se usará /tmp .
Ver el archivo de salida.
cat "${TMPDIR:-/tmp}/dsub-test/output/out.txt"
Actualmente, dsub admite la API v2beta de Cloud Life Sciences de Google Cloud y está desarrollando soporte para la API Batch de Google Cloud.
dsub admite la API v2beta con el proveedor google-cls-v2 . google-cls-v2 es el proveedor predeterminado actual. dsub realizará la transición para que google-batch sea el predeterminado en las próximas versiones.
Los pasos para comenzar difieren ligeramente como se indica a continuación:
Regístrese para obtener una cuenta de Google y cree un proyecto.
Habilite las API:
v2beta (proveedor: google-cls-v2 ):Habilite las API de computación, almacenamiento y ciencias biológicas en la nube
batch (proveedor: google-batch ):Habilite las API de lote, almacenamiento y computación.
Proporcione credenciales para que dsub pueda llamar a las API de Google:
gcloud auth application-default login
Cree un depósito de Google Cloud Storage.
Los registros de dsub y los archivos de salida se escribirán en un depósito. Cree un depósito usando el navegador de almacenamiento o ejecute la utilidad de línea de comandos gsutil, incluida en Cloud SDK.
gsutil mb gs://my-bucket
Cambie my-bucket por un nombre único que siga las convenciones de nomenclatura de depósitos.
(De forma predeterminada, el depósito estará en EE. UU., pero puede cambiar o refinar la configuración de ubicación con la opción -l ).
Ejecute un trabajo dsub muy simple "Hello World" y espere a que finalice.
Para la API v2beta (proveedor: google-cls-v2 ):
dsub
--provider google-cls-v2
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Cambie my-cloud-project a su proyecto de Google Cloud y my-bucket al depósito que creó anteriormente.
Para la API batch (proveedor: google-batch ):
dsub
--provider google-batch
--project my-cloud-project
--regions us-central1
--logging gs://my-bucket/logging/
--output OUT=gs://my-bucket/output/out.txt
--command 'echo "Hello World" > "${OUT}"'
--wait
Cambie my-cloud-project a su proyecto de Google Cloud y my-bucket al depósito que creó anteriormente.
El resultado del comando de secuencia de comandos se escribirá en el archivo OUT en Cloud Storage que especifique.
Ver el archivo de salida.
gsutil cat gs://my-bucket/output/out.txt
Siempre que sea posible, dsub intenta ayudar a que los usuarios puedan desarrollar y probar localmente (para una iteración más rápida) y luego progresar para ejecutar a escala.
Con este fin, dsub proporciona múltiples "proveedores de backend", cada uno de los cuales implementa un entorno de ejecución consistente. Los proveedores actuales son:
Se pueden encontrar más detalles sobre el entorno de ejecución implementado por los proveedores de backend en proveedores de backend de dsub.
google-cls-v2 y google-batch El proveedor google-cls-v2 se basa en la API v2beta de Cloud Life Sciences. Esta API es muy similar a su predecesora, la API Genomics v2alpha1 . Los detalles de las diferencias se pueden encontrar en la Guía de migración.
El proveedor google-batch se basa en la API de Cloud Batch. Los detalles de Cloud Life Sciences frente a Batch se pueden encontrar en esta Guía de migración.
dsub oculta en gran medida las diferencias entre las API, pero hay algunas diferencias a tener en cuenta:
google-batch requiere que los trabajos se ejecuten en una región Los indicadores --regions y --zones para dsub especifican dónde deben ejecutarse las tareas. google-cls-v2 le permite especificar una región múltiple como US , múltiples regiones o múltiples zonas entre regiones. Con el proveedor google-batch , debe especificar una región o varias zonas dentro de una sola región.
dsubLas siguientes secciones muestran cómo ejecutar trabajos más complejos.
Puede proporcionar un comando de shell directamente en la línea de comandos de dsub, como en el ejemplo de saludo anterior.
También puedes guardar tu script en un archivo, como hello.sh . Entonces puedes ejecutar:
dsub
...
--script hello.sh
Si su secuencia de comandos tiene dependencias que no están almacenadas en su imagen de Docker, puede transferirlas al disco local. Consulte las instrucciones a continuación para trabajar con archivos y carpetas de entrada y salida.
Para comenzar más fácilmente, dsub utiliza una imagen estándar de Ubuntu Docker. Esta imagen predeterminada puede cambiar en cualquier momento en versiones futuras, por lo que para flujos de trabajo de producción reproducibles, siempre debe especificar la imagen explícitamente.
Puede cambiar la imagen pasando la bandera --image .
dsub
...
--image ubuntu:16.04
--script hello.sh
Nota: su --image debe incluir el intérprete de shell Bash.
Para obtener más información sobre el uso del indicador --image , consulte la sección de imágenes en Scripts, comandos y Docker.
Puede pasar variables de entorno a su script usando el indicador --env .
dsub
...
--env MESSAGE=hello
--command 'echo ${MESSAGE}'
A la variable de entorno MESSAGE se le asignará el valor hello cuando se ejecute su contenedor Docker.
Su script o comando puede hacer referencia a la variable como cualquier otra variable de entorno de Linux, como ${MESSAGE} .
Asegúrese de incluir la cadena de comando entre comillas simples y no entre comillas dobles. Si usa comillas dobles, el comando se expandirá en su shell local antes de pasarlo a dsub. Para obtener más información sobre el uso del indicador --command , consulte Scripts, comandos y Docker.
Para configurar múltiples variables de entorno, puede repetir la bandera:
--env VAR1=value1
--env VAR2=value2
También puedes configurar múltiples variables, delimitadas por espacios, con una sola bandera:
--env VAR1=value1 VAR2=value2
dsub imita el comportamiento de un sistema de archivos compartido utilizando rutas de depósitos de almacenamiento en la nube para archivos y carpetas de entrada y salida. Usted especifica la ruta del depósito de almacenamiento en la nube. Los caminos pueden ser:
gs://my-bucket/my-filegs://my-bucket/my-foldergs://my-bucket/my-folder/*Consulte la documentación de entradas y salidas para obtener más detalles.
Si su secuencia de comandos espera leer archivos de entrada locales que aún no están contenidos en su imagen de Docker, los archivos deben estar disponibles en Google Cloud Storage.
Si su secuencia de comandos tiene archivos dependientes, puede ponerlos a disposición de su secuencia de comandos de la siguiente manera:
Para cargar los archivos en Google Cloud Storage, puede utilizar el navegador de almacenamiento o gsutil. También puede ejecutar datos públicos o compartidos con su cuenta de servicio, una dirección de correo electrónico que puede encontrar en Google Cloud Console.
Para especificar archivos de entrada y salida, utilice los indicadores --input y --output :
dsub
...
--input INPUT_FILE_1=gs://my-bucket/my-input-file-1
--input INPUT_FILE_2=gs://my-bucket/my-input-file-2
--output OUTPUT_FILE=gs://my-bucket/my-output-file
--command 'cat "${INPUT_FILE_1}" "${INPUT_FILE_2}" > "${OUTPUT_FILE}"'
En este ejemplo:
gs://my-bucket/my-input-file-1 a una ruta en el disco de datos.${INPUT_FILE_1}gs://my-bucket/my-input-file-2 a una ruta en el disco de datos.${INPUT_FILE_2} El --command hacer referencia a las rutas de los archivos utilizando las variables de entorno.
También en este ejemplo:
${OUTPUT_FILE}${OUTPUT_FILE} Una vez que se complete el --command , el archivo de salida se copiará en la ruta del depósito gs://my-bucket/my-output-file
Se pueden especificar múltiples parámetros --input y --output y se pueden especificar en cualquier orden.
Para copiar carpetas en lugar de archivos, utilice los indicadores --input-recursive y output-recursive :
dsub
...
--input-recursive FOLDER=gs://my-bucket/my-folder
--command 'find ${FOLDER} -name "foo*"'
Se pueden especificar múltiples parámetros --input-recursive y --output-recursive y se pueden especificar en cualquier orden.
Si bien especificar explícitamente las entradas mejora el seguimiento de la procedencia de tus datos, hay casos en los que es posible que no desees localizar explícitamente todas las entradas de Cloud Storage a tu máquina virtual de trabajo.
Por ejemplo, si tienes:
O
O
entonces puede que le resulte más eficiente o conveniente acceder a estos datos montando el modo de solo lectura:
El proveedor google-cls-v2 y google-batch admite estos métodos para proporcionar acceso a datos de recursos.
El proveedor local admite la creación de un directorio local de manera similar para respaldar su desarrollo local.
Para que el proveedor google-cls-v2 o google-batch monte un depósito de Cloud Storage usando Cloud Storage FUSE, use la marca de línea de comando --mount :
--mount RESOURCES=gs://mybucket
El depósito se montará como de solo lectura en el contenedor Docker que ejecuta su --script o --command y la ubicación estará disponible a través de la variable de entorno ${RESOURCES} . Dentro de su secuencia de comandos, puede hacer referencia a la ruta montada utilizando la variable de entorno. Lea las diferencias clave con un sistema de archivos POSIX y la semántica antes de usar Cloud Storage FUSE.
Para que el proveedor google-cls-v2 o google-batch monte un disco persistente que haya creado y completado previamente, use la marca de línea de comando --mount y la URL del disco de origen:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/zones/your_disk_zone/disks/your-disk"
Para que el proveedor google-cls-v2 o google-batch monte un disco persistente creado a partir de una imagen, use el indicador de línea de comando --mount y la URL de la imagen de origen y el tamaño (en GB) del disco:
--mount RESOURCES="https://www.googleapis.com/compute/v1/projects/your-project/global/images/your-image 50"
La imagen se utilizará para crear un nuevo disco persistente, que se adjuntará a una VM de Compute Engine. El disco se montará en el contenedor Docker que ejecuta su --script o --command y la ubicación estará disponible mediante la variable de entorno ${RESOURCES} . Dentro de su secuencia de comandos, puede hacer referencia a la ruta montada utilizando la variable de entorno.
Para crear una imagen, consulte Creación de una imagen personalizada.
local ) Para que el proveedor local monte un directorio de solo lectura, use el indicador de línea de comando --mount y un prefijo file:// :
--mount RESOURCES=file://path/to/my/dir
El directorio local se montará en el contenedor Docker que ejecuta su --script o --command y la ubicación estará disponible a través de la variable de entorno ${RESOURCES} . Dentro de su secuencia de comandos, puede hacer referencia a la ruta montada utilizando la variable de entorno.
Las tareas dsub ejecutadas con el proveedor local utilizarán los recursos disponibles en su máquina local.
Las tareas dsub que se ejecutan con los proveedores google-cls-v2 o google-batch pueden aprovechar una amplia gama de opciones de CPU, RAM, disco y acelerador de hardware (por ejemplo, GPU).
Consulte la documentación de Compute Resources para obtener más detalles.
De forma predeterminada, dsub genera una job-id con la forma job-name--userid--timestamp donde el job-name se trunca a 10 caracteres y la timestamp tiene la forma YYMMDD-HHMMSS-XX , única en centésimas de segundo. . Si envía varios trabajos al mismo tiempo, aún puede encontrarse con situaciones en las que la job-id no sea única. Si necesita una job-id única para esta situación, puede usar el parámetro --unique-job-id .
Si se establece el parámetro --unique-job-id , job-id será un UUID único de 32 caracteres creado por https://docs.python.org/3/library/uuid.html. Debido a que algunos proveedores requieren que la job-id comience con una letra, dsub reemplazará cualquier dígito inicial con una letra de una manera que preserve la unicidad.
Cada uno de los ejemplos anteriores ha demostrado cómo enviar una única tarea con un único conjunto de variables, entradas y salidas. Si tiene un lote de entradas y desea ejecutar la misma operación sobre ellas, dsub le permite crear un trabajo por lotes.
En lugar de llamar dsub repetidamente, puede crear un archivo de valores separados por tabulaciones (TSV) que contenga las variables, entradas y salidas para cada tarea y luego llamar dsub una vez. El resultado será una única job-id con múltiples tareas. Las tareas se programarán y ejecutarán de forma independiente, pero se pueden monitorear y eliminar como grupo.
La primera línea del archivo TSV especifica los nombres y tipos de parámetros. Por ejemplo:
--env SAMPLE_ID<tab>--input VCF_FILE<tab>--output OUTPUT_PATH
Cada línea adicional en el archivo debe proporcionar los valores de variable, entrada y salida para cada tarea. Cada línea más allá del encabezado representa los valores de una tarea separada.
Se pueden especificar múltiples parámetros --env , --input y --output y se pueden especificar en cualquier orden. Por ejemplo:
--env SAMPLE<tab>--input A<tab>--input B<tab>--env REFNAME<tab>--output O
S1<tab>gs://path/A1.txt<tab>gs://path/B1.txt<tab>R1<tab>gs://path/O1.txt
S2<tab>gs://path/A2.txt<tab>gs://path/B2.txt<tab>R2<tab>gs://path/O2.txt
Pase el archivo TSV a dsub usando el parámetro --tasks . Este parámetro acepta tanto la ruta del archivo como, opcionalmente, una variedad de tareas para procesar. El archivo se puede leer desde el sistema de archivos local (en la máquina desde la que llama dsub ) o desde un depósito en Google Cloud Storage (el nombre del archivo comienza con "gs://").
Por ejemplo, supongamos que my-tasks.tsv contiene 101 líneas: un encabezado de una línea y 100 líneas de parámetros para que se ejecuten las tareas. Entonces:
dsub ... --tasks ./my-tasks.tsv
creará un trabajo con 100 tareas, mientras:
dsub ... --tasks ./my-tasks.tsv 1-10
creará un trabajo con 10 tareas, una para cada una de las líneas 2 a 11.
Los valores del rango de tareas pueden adoptar cualquiera de las siguientes formas:
m indica enviar la tarea m (línea m+1)m- indica enviar todas las tareas que comienzan con la tarea mmn indica enviar todas las tareas de m n (inclusive). El indicador --logging apunta a una ubicación para los archivos de registro de tareas dsub . Para obtener detalles sobre cómo especificar su ruta de registro, consulte Registro.
Es posible esperar a que se complete un trabajo antes de comenzar otro. Para obtener más información, consulte control de trabajos con dsub.
Es posible que dsub reintente automáticamente las tareas fallidas. Para obtener más información, consulte reintentos con dsub.
Puede agregar etiquetas personalizadas a trabajos y tareas, lo que le permite monitorear y cancelar tareas utilizando sus propios identificadores. Además, con los proveedores de Google, al etiquetar una tarea se etiquetarán los recursos informáticos asociados, como máquinas virtuales y discos.
Para obtener más detalles, consulte Comprobación del estado y solución de problemas de trabajos.
El comando dstat muestra el estado de los trabajos:
dstat --provider google-cls-v2 --project my-cloud-project
Sin argumentos adicionales, dstat mostrará una lista de trabajos en ejecución para el USER actual.
Para mostrar el estado de un trabajo específico, use el indicador --jobs :
dstat --provider google-cls-v2 --project my-cloud-project --jobs job-id
Para un trabajo por lotes, el resultado enumerará todas las tareas en ejecución .
Cada trabajo enviado por dsub recibe un conjunto de valores de metadatos que se pueden utilizar para la identificación y el control del trabajo. Los metadatos asociados con cada trabajo incluyen:
job-name : por defecto es el nombre de su archivo de script o la primera palabra de su comando de script; se puede configurar explícitamente con el parámetro --name .user-id : el valor de la variable de entorno USER .job-id : identificador del trabajo, que se puede utilizar en llamadas a dstat y ddel para monitorear y cancelar trabajos respectivamente. Consulte Identificadores de trabajo para obtener más detalles sobre el formato job-id .task-id : si el trabajo se envía con el parámetro --tasks , cada tarea obtiene un valor secuencial del formato "tarea -n " donde n está basado en 1.Tenga en cuenta que los valores de los metadatos del trabajo se modificarán para cumplir con las "Restricciones de etiquetas" enumeradas en la guía Comprobación del estado y solución de problemas de los trabajos.
Los metadatos se pueden utilizar para cancelar un trabajo o tareas individuales dentro de un trabajo por lotes.
Para obtener más detalles, consulte Comprobación del estado y solución de problemas de trabajos.
De forma predeterminada, dstat genera una línea por tarea. Si está utilizando un trabajo por lotes con muchas tareas, puede beneficiarse de --summary .
$ dstat --provider google-cls-v2 --project my-project --status '*' --summary
Job Name Status Task Count
------------- ------------- -------------
my-job-name RUNNING 2
my-job-name SUCCESS 1
En este modo, dstat imprime una línea por par (nombre del trabajo, estado de la tarea). Puede ver de un vistazo cuántas tareas han finalizado, cuántas aún se están ejecutando y cuántas han fallado/cancelado.
El comando ddel eliminará los trabajos en ejecución.
De forma predeterminada, sólo se eliminarán los trabajos enviados por el usuario actual. Utilice el indicador --users para especificar otros usuarios, o '*' para todos los usuarios.
Para eliminar un trabajo en ejecución:
ddel --provider google-cls-v2 --project my-cloud-project --jobs job-id
Si el trabajo es por lotes, se eliminarán todas las tareas en ejecución.
Para eliminar tareas específicas:
ddel
--provider google-cls-v2
--project my-cloud-project
--jobs job-id
--tasks task-id1 task-id2
Para eliminar todos los trabajos en ejecución para el usuario actual:
ddel --provider google-cls-v2 --project my-cloud-project --jobs '*'
Cuando ejecuta el comando dsub con el proveedor google-cls-v2 o google-batch , hay dos conjuntos diferentes de credenciales a considerar:
pipelines.run() para ejecutar su comando/script en una VM La cuenta utilizada para enviar la solicitud pipelines.run() suele ser sus credenciales de usuario final. Habrías configurado esto ejecutando:
gcloud auth application-default login
La cuenta utilizada en la VM es una cuenta de servicio. La siguiente imagen ilustra esto:
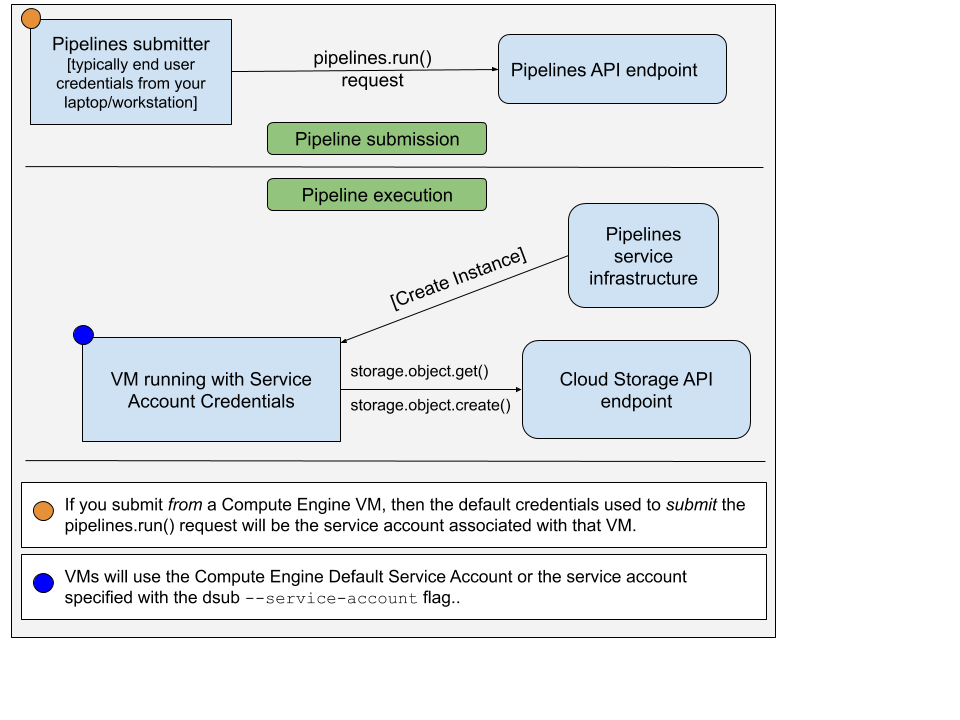
De forma predeterminada, dsub utilizará la cuenta de servicio predeterminada de Compute Engine como cuenta de servicio autorizada en la instancia de VM. Puede optar por especificar la dirección de correo electrónico de otra cuenta de servicio usando --service-account .
De forma predeterminada, dsub otorgará los siguientes alcances de acceso a la cuenta de servicio:
Además, la API siempre agregará este alcance:
Puede optar por especificar ámbitos utilizando --scopes .
Si bien es sencillo utilizar la cuenta de servicio predeterminada, esta cuenta también tiene amplios privilegios otorgados de forma predeterminada. Siguiendo el principio de privilegios mínimos, es posible que desee crear y utilizar una cuenta de servicio a la que solo se le concedan privilegios suficientes para ejecutar su comando/script dsub .
Para crear una nueva cuenta de servicio, siga los pasos a continuación:
Ejecute el comando gcloud iam service-accounts create . La dirección de correo electrónico de la cuenta de servicio será [email protected] .
gcloud iam service-accounts create "sa-name"
Otorgue acceso de IAM a depósitos, etc., a la cuenta de servicio.
gsutil iam ch serviceAccount:[email protected]:roles/storage.objectAdmin gs://bucket-name
Actualice su comando dsub para incluir --service-account
dsub
--service-account [email protected]
...
Vea los ejemplos:
Ver más documentación para:


