CQN
1.0.0
Una reimplementación de Q-Network (CQN) de grueso a fino , un algoritmo RL basado en valores eficiente en muestras para control continuo, introducido en:
Control continuo con aprendizaje por refuerzo de grueso a fino
Younggyo Seo, Jafar Uruç, Stephen James
Nuestra idea clave es aprender agentes de RL que se acerquen al espacio de acción continua de manera gruesa a fina, lo que nos permitirá entrenar agentes de RL basados en valores para un control continuo con pocas acciones discretas en cada nivel.
Consulte la página web de nuestro proyecto https://younggyo.me/cqn/ para obtener más información.
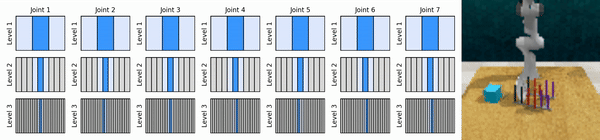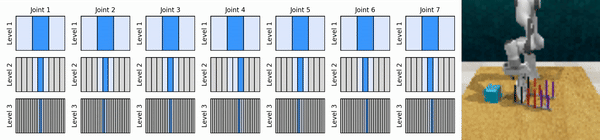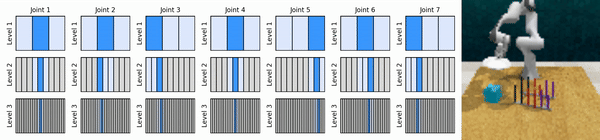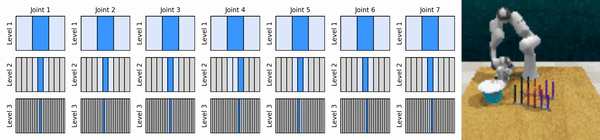
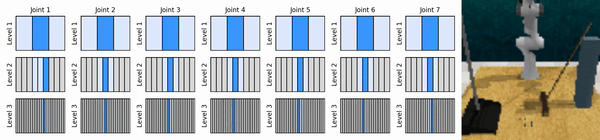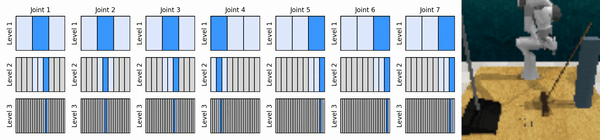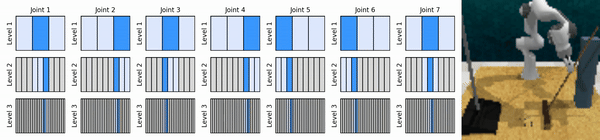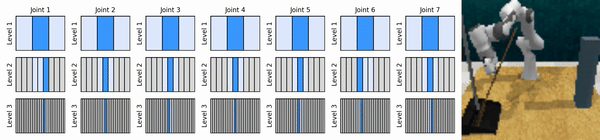
Instalar el entorno conda:
conda env create -f conda_env.yml
conda activate cqn
Instale RLBench y PyRep (se deben utilizar las últimas versiones con fecha del 10 de julio de 2024). Siga la guía en los repositorios originales para (1) instalar RLBench y PyRep y (2) habilitar el modo sin cabeza. (Consulte README en RLBench y Robobase para obtener información sobre cómo instalar RLBench).
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
Demostraciones previas a la recogida
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
Ejecutar experimentos (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Ejecute experimentos de referencia (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Ejecutar experimentos:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
Advertencia: CQN no se prueba exhaustivamente en DMC
Este repositorio se basa en la implementación pública de DrQ-v2.
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


