SOLIDER
1.0.0

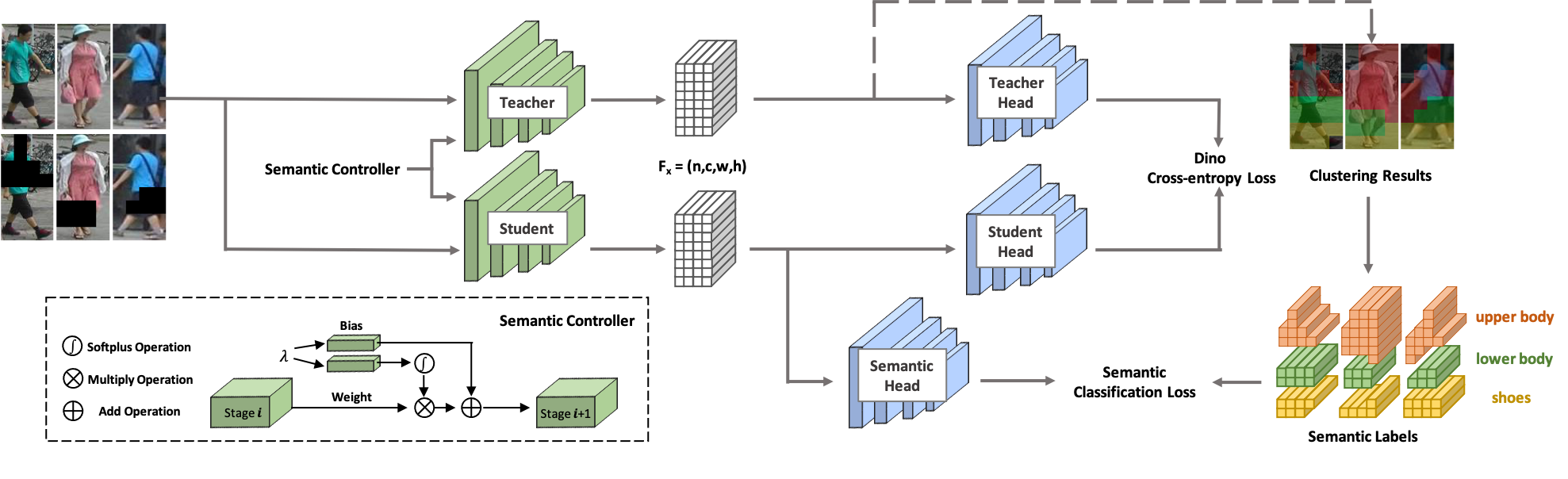
¡Bienvenido a SOLDADO ! SOLIDER es un marco de aprendizaje autosupervisado y controlable semántico para aprender representaciones humanas generales a partir de imágenes humanas masivas sin etiquetar que pueden beneficiar al máximo las tareas posteriores centradas en el ser humano. A diferencia de los métodos de aprendizaje autosupervisados existentes, en SOLIDER se utiliza el conocimiento previo de imágenes humanas para crear etiquetas pseudosemánticas e importar más información semántica a la representación aprendida. Mientras tanto, diferentes tareas posteriores siempre requieren diferentes proporciones de información semántica e información de apariencia, y una única representación aprendida no puede satisfacer todos los requisitos. Para resolver este problema, SOLIDER introduce una red condicional con un controlador semántico, que puede adaptarse a diferentes necesidades de tareas posteriores. Para obtener más detalles, consulte nuestro artículo Más allá de la apariencia: un marco de aprendizaje semántico controlable y autosupervisado para tareas visuales centradas en el ser humano.
Este código base ha sido desarrollado con Python versión 3.7, PyTorch versión 1.7.1, CUDA 10.1 y torchvision 0.8.2.
Usamos LUPerson como nuestros datos de entrenamiento, que consisten en imágenes humanas sin etiquetar. Descarga LUPerson desde su enlace oficial y descomprímelo.
sh run_solider.shsh run_dino.sh
sh resume_solider.shHay una demostración para ejecutar el modelo SOLIDER entrenado, que se puede integrar en la inferencia o en el ajuste fino de la tarea posterior.
python demo.pyUtilizamos Swin-Transformer como nuestra columna vertebral, lo que muestra grandes ventajas en muchas tareas de CV.
| Tarea | Conjunto de datos | Nadar pequeño (Enlace) | Nadar pequeño (Enlace) | Base de natación (Enlace) |
|---|---|---|---|---|
| Reidentificación de personas (mAP/R1) sin reclasificación | Mercado1501 | 91,6/96,1 | 93,3/96,6 | 93,9/96,9 |
| MSMT17 | 67,4/85,9 | 76,9/90,8 | 77,1/90,7 | |
| Reidentificación de personas (mAP/R1) con reclasificación | Mercado1501 | 95,3/96,6 | 95,4/96,4 | 95,6/96,7 |
| MSMT17 | 81,5/89,2 | 86,5/91,7 | 86,5/91,7 | |
| Reconocimiento de atributos (mA) | PETA_ZS | 74,37 | 76,21 | 76,43 |
| RAP_ZS | 74,23 | 75,95 | 76,42 | |
| PA100K | 84.14 | 86,25 | 86,37 | |
| Búsqueda de personas (mAP/R1) | CUHK-SYSU | 94,9/95,7 | 95,5/95,8 | 94,9/95,5 |
| PRW | 56,8/86,8 | 59,8/86,7 | 59,7/86,8 | |
| Detección de peatones (MR-2) | CiudadPersonas | 10,3/40,8 | 10,0/39,2 | 9,7/39,4 |
| Análisis humano (mIOU) | LABIO | 57,52 | 60.21 | 60.50 |
| Estimación de pose (AP/AR) | PALMA DE COCO | 74,4/79,6 | 76,3/81,3 | 76,6/81,5 |
Nuestra implementación se basa principalmente en las siguientes bases de código. Agradecemos con gratitud a los autores por sus maravillosos trabajos.
Si utiliza SOLIDER en su investigación, cite nuestro trabajo utilizando la siguiente entrada BibTeX:
@inproceedings{chen2023beyond,
title={Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks},
author={Weihua Chen and Xianzhe Xu and Jian Jia and Hao Luo and Yaohua Wang and Fan Wang and Rong Jin and Xiuyu Sun},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023},
}


