gpt neox
GPT-NeoX 2.0
Este repositorio registra la biblioteca de EleutherAI para entrenar modelos de lenguaje a gran escala en GPU. Nuestro marco actual se basa en el modelo de lenguaje Megatron de NVIDIA y se ha ampliado con técnicas de DeepSpeed, así como algunas optimizaciones novedosas. Nuestro objetivo es hacer de este repositorio un lugar centralizado y accesible para recopilar técnicas para entrenar modelos de lenguaje autorregresivos a gran escala y acelerar la investigación sobre capacitación a gran escala. Esta biblioteca se utiliza ampliamente en laboratorios académicos, industriales y gubernamentales, incluidos investigadores del Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, la Universidad de Corea, la Universidad Carnegie Mellon y la Universidad de Tokio, entre otros. Únicamente entre bibliotecas similares, GPT-NeoX admite una amplia variedad de sistemas y hardware, incluido el lanzamiento a través de Slurm, MPI e IBM Job Step Manager, y se ha ejecutado a escala en AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI y otros.
Si no está buscando entrenar modelos con miles de millones de parámetros desde cero, es probable que esta sea la biblioteca incorrecta. Para necesidades de inferencia genéricas, le recomendamos que utilice la biblioteca transformers Hugging Face, que admite modelos GPT-NeoX.
GPT-NeoX aprovecha muchas de las mismas características y tecnologías que la popular biblioteca Megatron-DeepSpeed, pero con una usabilidad sustancialmente mayor y optimizaciones novedosas. Las características principales incluyen:
[9/9/2024] Ahora admitimos el aprendizaje de preferencias a través de DPO, KTO y modelos de recompensa
[9/9/2024] Ahora admitimos la integración con Comet ML, una plataforma de monitoreo de aprendizaje automático
[21/05/2024] ¡Ahora admitimos RWKV con paralelismo de canalización!. Consulte los RP para RWKV y RWKV+pipeline
[21/03/2024] Ahora apoyamos la combinación de expertos (MoE)
[17/03/2024] Ahora admitimos GPU AMD MI250X
[15/03/2024] ¡Ahora admitimos Mamba con paralelismo tensorial! Ver las relaciones públicas
[10/8/2023] ¡Ahora admitimos puntos de control con AWS S3! Activar con la opción de configuración s3_path (para más detalles, consulte el PR)
[20/9/2023] A partir del n.º 1035, hemos dejado de utilizar Flash Attention 0.xy 1.x, y hemos migrado la compatibilidad con Flash Attention 2.x. No creemos que esto cause problemas, pero si tiene un caso de uso específico que requiere compatibilidad con flash antiguo utilizando el último GPT-NeoX, plantee un problema.
[10/8/2023] Contamos con soporte experimental para LLaMA 2 y Flash Attention v2 en nuestro proyecto math-lm que se actualizará a finales de este mes.
[17/05/2023] Después de corregir algunos errores varios, ahora somos totalmente compatibles con bf16.
[11/04/2023] Hemos actualizado nuestra implementación de Flash Attention para que ahora admita incrustaciones posicionales de Alibi.
[9/03/2023] Hemos lanzado GPT-NeoX 2.0.0, una versión mejorada basada en el último DeepSpeed que se sincronizará periódicamente en el futuro.
Antes del 9/3/2023, GPT-NeoX dependía de DeeperSpeed, que se basaba en una versión antigua de DeepSpeed (0.3.15). Para migrar a la última versión ascendente de DeepSpeed y al mismo tiempo permitir a los usuarios acceder a las versiones antiguas de GPT-NeoX y DeeperSpeed, hemos introducido dos versiones versionadas para ambas bibliotecas:
Esta base de código se ha desarrollado y probado principalmente para Python 3.8-3.10 y PyTorch 1.8-2.0. Este no es un requisito estricto y pueden funcionar otras versiones y combinaciones de bibliotecas.
Para instalar las dependencias básicas restantes, ejecute:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometdesde la raíz del repositorio.
Advertencia
Nuestro código base se basa en DeeperSpeed, nuestra bifurcación de la biblioteca DeepSpeed con algunos cambios adicionales. Recomendamos encarecidamente utilizar Anaconda, una máquina virtual o alguna otra forma de aislamiento del entorno antes de continuar. De lo contrario, es posible que otros repositorios que dependen de DeepSpeed fallen.
Ahora admitimos GPU AMD (MI100, MI250X) a través de la compilación de núcleo fusionado JIT. Los núcleos fusionados se construirán y cargarán según sea necesario. Para evitar esperas durante el inicio del trabajo, también puede hacer lo siguiente para la compilación previa manual:
python
from megatron . fused_kernels import load
load () Esto adaptará automáticamente el proceso de construcción entre diferentes proveedores de GPU (AMD, NVIDIA) sin cambios de código específicos de la plataforma. Para probar más los núcleos fusionados usando pytest , use pytest tests/model/test_fused_kernels.py
Para usar Flash-Attention, instale las dependencias adicionales en ./requirements/requirements-flashattention.txt y establezca el tipo de atención en su configuración en consecuencia (consulte configuraciones). Esto puede proporcionar importantes aceleraciones con respecto a la atención habitual en determinadas arquitecturas de GPU, incluidas las GPU Ampere (como las A100); consulte el repositorio para obtener más detalles.
NeoX y Deep(er)Speed admiten la capacitación en múltiples nodos diferentes y usted tiene la opción de usar una variedad de lanzadores diferentes para organizar trabajos de múltiples nodos.
En general, es necesario que haya un "archivo host" en algún lugar accesible con el formato:
node1_ip slots=8
node2_ip slots=8 donde la primera columna contiene la dirección IP de cada nodo en su configuración y la cantidad de ranuras es la cantidad de GPU a las que tiene acceso ese nodo. En su configuración debe pasar la ruta al archivo host con "hostfile": "/path/to/hostfile" . Alternativamente, la ruta al archivo host puede estar en la variable de entorno DLTS_HOSTFILE .
pdsh es el iniciador predeterminado, y si está utilizando pdsh , todo lo que debe hacer (además de asegurarse de que pdsh esté instalado en su entorno) es configurar {"launcher": "pdsh"} en sus archivos de configuración.
Si usa MPI, debe especificar la biblioteca MPI (DeepSpeed/GPT-NeoX actualmente admite mvapich , openmpi , mpich e impi , aunque openmpi es la más utilizada y probada), así como pasar el indicador deepspeed_mpi en su archivo de configuración:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Con su entorno configurado correctamente y los archivos de configuración correctos, puede usar deepy.py como un script de Python normal e iniciar (por ejemplo) un trabajo de capacitación con:
python3 deepy.py train.py /path/to/configs/my_model.yml
Usar Slurm puede ser un poco más complicado. Al igual que con MPI, debes agregar lo siguiente a tu configuración:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Si no tiene acceso ssh a los nodos de computación en su clúster Slurm, debe agregar {"no_ssh_check": true}
Hay muchos casos en los que las opciones de inicio predeterminadas anteriores no son suficientes.
En estos casos, deberá modificar la utilidad del ejecutor multinodo DeepSpeed para que sea compatible con su caso de uso. En términos generales, estas mejoras se dividen en dos categorías:
En este caso, debe agregar una nueva clase de corredor multinodo a deepspeed/launcher/multinode_runner.py y exponerla como una opción de configuración en GPT-NeoX. Ejemplos de cómo hicimos esto para Summit JSRun se encuentran en este compromiso de DeeperSpeed y este compromiso de GPT-NeoX, respectivamente.
Hemos encontrado muchos casos en los que deseamos modificar el comando de ejecución de MPI/Slurm para una optimización o para depurar (por ejemplo, para modificar el enlace de CPU de Slurm srun o etiquetar los registros de MPI con el rango). En este caso, debe modificar el comando de ejecución de la clase de ejecución multinodo bajo su método get_cmd (por ejemplo, mpirun_cmd para OpenMPI). En esta rama de DeeperSpeed se encuentran ejemplos de cómo hicimos esto para proporcionar comandos de ejecución optimizados y etiquetados con rango usando Slurm y OpenMPI para el clúster de Estabilidad.
En general, no podrá tener un solo archivo host fijo, por lo que necesitará tener un script para generar uno dinámicamente cuando comience su trabajo. Un script de ejemplo para generar dinámicamente un archivo host usando Slurm y 8 GPU por nodo es:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID y $SLURM_NODELIST son variables de entorno que Slurm creará para usted. Consulte la documentación de sbatch para obtener una lista completa de las variables de entorno de Slurm disponibles configuradas en el momento de la creación del trabajo.
Luego puede crear un script sbatch desde el cual iniciar su trabajo GPT-NeoX. Un script sbatch básico en un clúster basado en Slurm con 8 GPU por nodo se vería así:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Luego puedes iniciar una carrera de entrenamiento con sbatch my_sbatch_script.sh
También proporcionamos una configuración Dockerfile y docker-compose si prefiere ejecutar NeoX en un contenedor.
Los requisitos para ejecutar el contenedor son tener controladores de GPU adecuados, una instalación actualizada de Docker y nvidia-container-toolkit instalado. Para probar si su instalación es buena, puede utilizar su "carga de trabajo de muestra", que es:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Siempre que se ejecute, debe exportar NEOX_DATA_PATH y NEOX_CHECKPOINT_PATH en su entorno para especificar su directorio de datos y el directorio para almacenar y cargar puntos de control:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
Y luego, desde el directorio gpt-neox, puede crear la imagen y ejecutar un shell en un contenedor con
docker compose run gpt-neox bash
Después de la compilación, deberías poder hacer esto:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Para un trabajo de larga duración, debe ejecutar
docker compose up -d
para ejecutar el contenedor en modo separado y luego, en una sesión de terminal separada, ejecutar
docker compose exec gpt-neox bash
Luego puede ejecutar cualquier trabajo que desee desde el interior del contenedor.
Las preocupaciones cuando se ejecuta durante mucho tiempo o en modo independiente incluyen
Si prefiere ejecutar la imagen del contenedor prediseñada desde dockerhub, puede ejecutar los comandos de docker compose con -f docker-compose-dockerhub.yml en su lugar, por ejemplo,
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Todas las funciones deben iniciarse utilizando deepy.py , un contenedor del iniciador deepspeed .
Actualmente ofrecemos tres funciones principales:
train.py se utiliza para entrenar y ajustar modelos.eval.py se utiliza para evaluar un modelo entrenado utilizando el arnés de evaluación del modelo de lenguaje.generate.py se utiliza para muestrear texto de un modelo entrenado.que se puede iniciar con:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Por ejemplo, para iniciar el entrenamiento puedes ejecutar
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlPara obtener más detalles sobre cada punto de entrada, consulte Capacitación y Ajuste, Inferencia y Evaluación respectivamente.
Los parámetros de GPT-NeoX se definen en un archivo de configuración YAML que se pasa al iniciador deepy.py. Hemos proporcionado algunos archivos .yml de ejemplo en las configuraciones, que muestran una amplia gama de características y tamaños de modelos.
Estos archivos generalmente están completos, pero no son óptimos. Por ejemplo, dependiendo de su configuración específica de GPU, es posible que necesite cambiar algunas configuraciones como pipe-parallel-size , model-parallel-size para aumentar o disminuir el grado de paralelización, train_micro_batch_size_per_gpu o gradient-accumulation-steps para modificar el tamaño del lote. configuraciones relacionadas, o el dictado zero_optimization para modificar cómo se paralelizan los estados del optimizador entre los trabajadores.
Para obtener una guía más detallada sobre las funciones disponibles y cómo configurarlas, consulte el archivo README de configuración, y para obtener documentación de cada argumento posible, consulte configs/neox_arguments.md.
GPT-NeoX incluye múltiples implementaciones expertas para MoE. Para seleccionar entre ellos, especifique moe_type de megablocks (predeterminado) o deepspeed .
Ambos se basan en el marco de paralelismo DeepSpeed MoE, que admite el paralelismo de datos tensoriales-expertos. Ambos le permiten alternar entre token-drop y dropless (predeterminado, y para esto se diseñó Megablocks). ¡La ruta Sinkhorn llegará pronto!
Para ver un ejemplo de una configuración básica completa, consulte configs/125M-dmoe.yml (para Megablocks dropless) o configs/125M-moe.yml.
La mayoría de los argumentos de configuración relacionados con MoE tienen el prefijo moe . Algunos parámetros de configuración comunes y sus valores predeterminados son los siguientes:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed se puede configurar aún más con lo siguiente:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Una capa MoE está presente en cada capa del transformador expert_interval , incluida la primera, por lo que hay 12 capas en total:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Los expertos estarían en estas capas:
0, 2, 4, 6, 8, 10
De forma predeterminada, utilizamos el paralelismo de datos expertos, por lo que cualquier paralelismo tensorial disponible ( model_parallel_size ) se utilizará para el enrutamiento experto. Por ejemplo, dado lo siguiente:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
Con 32 GPU, el comportamiento será el siguiente:
expert_parallel_size == model_parallel_size . La configuración enable_expert_tensor_parallelism habilita el paralelismo tensorial-experto-datos (TED). La forma de interpretar lo anterior sería entonces:
expert_parallel_size == 1 o model_parallel_size == 1 .Tenga en cuenta que DP debe ser divisible por (MP * EP). Para obtener más detalles, consulte el artículo TED.
El paralelismo de canalización aún no es compatible, ¡próximamente!
Hay varios conjuntos de datos preconfigurados disponibles, incluida la mayoría de los componentes de Pile, así como el propio conjunto de trenes de Pile, para una tokenización sencilla utilizando el punto de entrada prepare_data.py .
Por ejemplo, para descargar y tokenizar el conjunto de datos enwik8 con el tokenizador GPT2, guardarlos en ./data puede ejecutar:
python prepare_data.py -d ./data
o un solo fragmento de la pila ( pile_subset ) con el tokenizador GPT-NeoX-20B (suponiendo que lo tenga guardado en ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Los datos tokenizados se guardarán en dos archivos: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin y [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Deberá agregar el prefijo que ambos archivos comparten a su archivo de configuración de entrenamiento en el campo data-path . P.EJ:
" data-path " : " ./data/enwik8/enwik8_text_document " , Para preparar su propio conjunto de datos para el entrenamiento con datos personalizados, formatéelo como un archivo grande con formato jsonl y cada elemento de la lista de diccionarios sea un documento independiente. El texto del documento debe agruparse bajo una clave JSON, es decir, "text" . No se utilizarán datos auxiliares almacenados en otros campos.
A continuación, asegúrese de descargar el vocabulario del tokenizador GPT2 y fusionar archivos desde los siguientes enlaces:
O use el tokenizador 20B (para el cual solo se necesita un archivo Vocab):
(Como alternativa, puede proporcionar cualquier archivo tokenizador que pueda cargar la biblioteca de tokenizadores de Hugging Face con el comando Tokenizer.from_pretrained() )
Ahora puede pretokenizar sus datos usando tools/datasets/preprocess_data.py , cuyos argumentos se detallan a continuación:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Por ejemplo:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodLuego ejecutará la capacitación con las siguientes configuraciones agregadas a su archivo de configuración:
" data-path " : " data/mydataset_text_document " , El entrenamiento se inicia utilizando deepy.py , un contenedor del iniciador de DeepSpeed, que lanza el mismo script en paralelo en muchas GPU/nodos.
El patrón de uso general es:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Puede pasar una cantidad arbitraria de configuraciones que se fusionarán en tiempo de ejecución.
Opcionalmente, también puede pasar un prefijo de configuración, lo que asumirá que todas sus configuraciones están en la misma carpeta y agregará ese prefijo a su ruta.
Por ejemplo:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Esto implementará el script train.py en todos los nodos con un proceso por GPU. Los nodos trabajadores y la cantidad de GPU se especifican en el archivo /job/hostfile (consulte la documentación de parámetros), o simplemente se pueden pasar como el argumento num_gpus si se ejecuta en una configuración de un solo nodo.
Aunque esto no es estrictamente necesario, nos resulta útil definir los parámetros del modelo en un archivo de configuración (por ejemplo, configs/125M.yml ) y los parámetros de la ruta de datos en otro (por ejemplo, configs/local_setup.yml ).
GPT-NeoX-20B es un modelo de lenguaje autorregresivo de 20 mil millones de parámetros entrenado en Pile. Los detalles técnicos sobre GPT-NeoX-20B se pueden encontrar en el documento asociado. El archivo de configuración para este modelo está disponible en ./configs/20B.yml y se incluye en los enlaces de descarga a continuación.
Pesos delgados: (sin estados de optimizador, para inferencia o ajuste, 39 GB)
Para descargar desde la línea de comando a una carpeta llamada 20B_checkpoints , use el siguiente comando:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsPesos completos: (incluidos los estados del optimizador, 268 GB)
Para descargar desde la línea de comando a una carpeta llamada 20B_checkpoints , use el siguiente comando:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsAlternativamente, los pesos se pueden descargar utilizando un cliente BitTorrent. Los archivos torrent se pueden descargar aquí: pesas delgadas, pesas completas.
También tenemos 150 puntos de control guardados durante el entrenamiento, uno cada 1.000 pasos. Estamos trabajando para descubrir cómo atenderlos mejor a escala, pero mientras tanto, las personas interesadas en trabajar con los puntos de control parcialmente capacitados pueden enviarnos un correo electrónico a [email protected] para organizar el acceso.
Pythia Scaling Suite es un conjunto de modelos que van desde 70M de parámetros hasta 12B de parámetros entrenados en Pile con el objetivo de promover la investigación sobre la interpretabilidad y la dinámica de entrenamiento de grandes modelos de lenguaje. Se pueden encontrar más detalles sobre el proyecto y enlaces a los modelos en el artículo y en el GitHub del proyecto.
El Proyecto Polyglot es un esfuerzo para entrenar potentes modelos de lenguajes previamente entrenados distintos del inglés para promover la accesibilidad de esta tecnología a investigadores fuera de las potencias dominantes del aprendizaje automático. EleutherAI ha entrenado y lanzado modelos de idioma coreano con parámetros 1.3B, 3.8B y 5.8B, el mayor de los cuales supera a todos los demás modelos de idioma disponibles públicamente en tareas de idioma coreano. Puede encontrar más detalles sobre el proyecto y enlaces a los modelos aquí.
Para la mayoría de los usos, recomendamos implementar modelos entrenados con la biblioteca GPT-NeoX a través de la biblioteca Hugging Face Transformers, que está mejor optimizada para la inferencia.
Admitimos tres tipos de generación a partir de un modelo previamente entrenado:
Los tres tipos de generación de texto se pueden iniciar a través de python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml con los valores apropiados establecidos en configs/text_generation.yml .
GPT-NeoX admite la evaluación de tareas posteriores a través del arnés de evaluación del modelo de lenguaje.
Para evaluar un modelo entrenado en el arnés de evaluación, simplemente ejecute:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn donde --eval_tasks es una lista de tareas de evaluación seguidas de espacios, por ejemplo --eval_tasks lambada hellaswag piqa sciq . Para obtener detalles de todas las tareas disponibles, consulte el repositorio lm-evaluación-arnés.
GPT-NeoX está fuertemente optimizado solo para entrenamiento, y los puntos de control del modelo GPT-NeoX no son compatibles de fábrica con otras bibliotecas de aprendizaje profundo. Para hacer que los modelos se puedan cargar y compartir fácilmente con los usuarios finales, y para exportarlos aún más a otros marcos, GPT-NeoX admite la conversión de puntos de control al formato Hugging Face Transformers.
Aunque NeoX admite varias configuraciones arquitectónicas diferentes, incluidas las incrustaciones posicionales de AliBi, no todas estas configuraciones se asignan claramente a las configuraciones admitidas dentro de Hugging Face Transformers.
NeoX admite la exportación de modelos compatibles a las siguientes arquitecturas:
Entrenar un modelo que no se ajuste limpiamente a una de estas arquitecturas de Hugging Face Transformers requerirá escribir un código de modelado personalizado para el modelo exportado.
Para convertir un punto de control de la biblioteca GPT-NeoX al formato cargable Hugging Face, ejecute:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Luego, para cargar un modelo en Hugging Face Hub, ejecute:
huggingface-cli login
python ./tools/ckpts/upload.pye ingrese la información solicitada, incluido el token de usuario del concentrador HF.
NeoX proporciona varias utilidades para convertir un punto de control de modelo previamente entrenado a un formato que pueda entrenarse dentro de la biblioteca.
Los siguientes modelos o familias de modelos se pueden cargar en GPT-NeoX:
Proporcionamos dos utilidades para convertir desde dos formatos de puntos de control diferentes a un formato compatible con GPT-NeoX.
Para convertir un punto de control Llama 1 o Llama 2 distribuido por Meta AI desde su formato de archivo original (descargable aquí o aquí) a la biblioteca GPT-NeoX, ejecute
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Para convertir de un modelo Hugging Face a uno cargable por NeoX, ejecute tools/ckpts/convert_hf_to_sequential.py . Consulte la documentación dentro de ese archivo para obtener más opciones.
Además de almacenar registros localmente, brindamos soporte integrado para dos marcos de monitoreo de experimentos populares: Weights & Biases, TensorBoard y Comet.
Weights & Biases para registrar nuestros experimentos es una plataforma de monitoreo de aprendizaje automático. Para usar wandb para monitorear sus experimentos con gpt-neox:
wandb login ; sus carreras se registrarán automáticamente../requirements/requirements-wandb.txt . Se proporciona una configuración de ejemplo en ./configs/local_setup_wandb.yml .wandb_group le permite nombrar el grupo de carreras y wandb_team le permite asignar sus carreras a una organización o cuenta de equipo. Se proporciona una configuración de ejemplo en ./configs/local_setup_wandb.yml . Admitimos el uso de TensorBoard a través del campo tensorboard-dir . Las dependencias necesarias para la supervisión de TensorBoard se pueden encontrar e instalar desde ./requirements/requirements-tensorboard.txt .
Comet es una plataforma de monitoreo de aprendizaje automático. Para utilizar comet para monitorear sus experimentos con gpt-neox:
comet login o pasando export COMET_API_KEY=<your-key-here>comet_ml y cualquier biblioteca de dependencia a través de pip install -r requirements/requirements-comet.txtuse_comet: True . También puede personalizar dónde se registran los datos con comet_workspace y comet_project . Se proporciona un ejemplo completo de configuración con el cometa habilitado en configs/local_setup_comet.yml . Si necesita proporcionar un archivo host para usarlo con el iniciador DeepSpeed basado en MPI, puede configurar la variable de entorno DLTS_HOSTFILE para que apunte al archivo host.
Admitimos la creación de perfiles con Nsight Systems, PyTorch Profiler y PyTorch Memory Profiling.
Para utilizar la creación de perfiles de Nsight Systems, establezca las opciones de configuración profile , profile_step_start y profile_step_stop (consulte aquí para conocer el uso de argumentos y aquí para ver una configuración de muestra).
Para completar las métricas de nsys, inicie la capacitación con:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
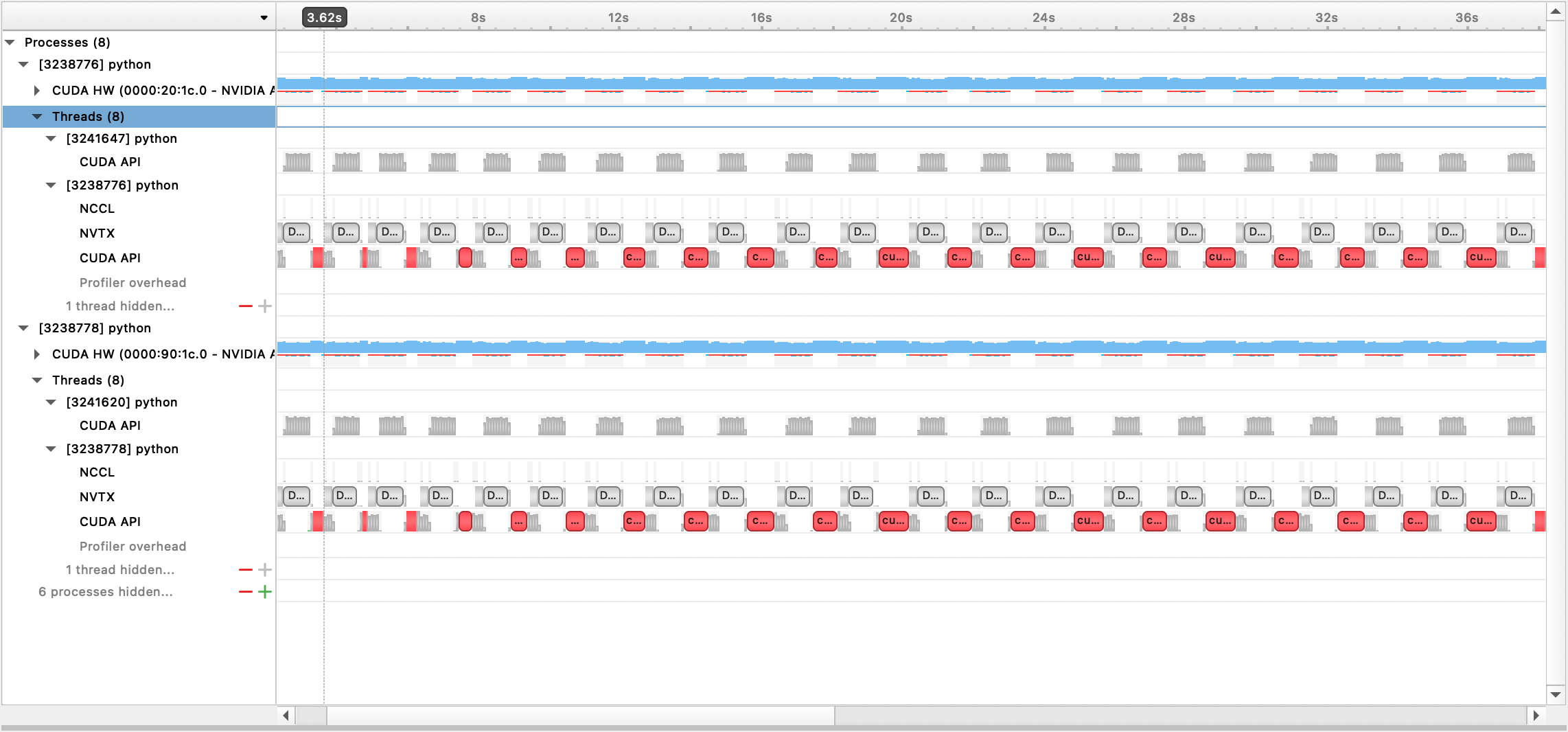
El archivo de salida generado se puede ver con la GUI de Nsight Systems:
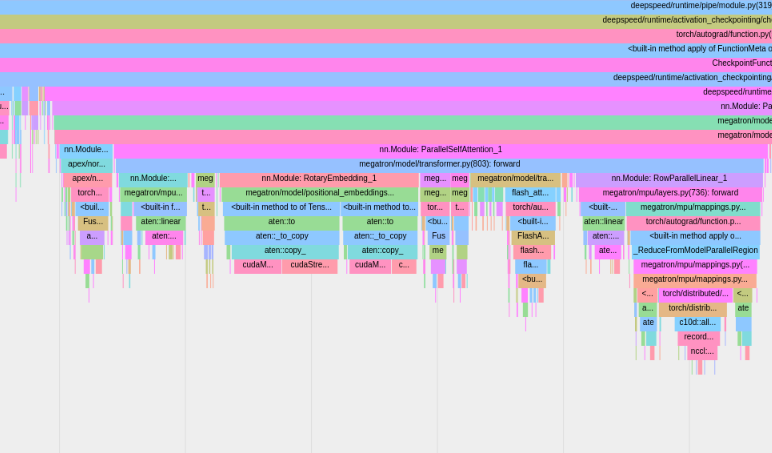
Para usar el generador de perfiles PyTorch integrado, configure las opciones de configuración profile , profile_step_start y profile_step_stop (consulte aquí para conocer el uso de argumentos y aquí para ver una configuración de muestra).
El generador de perfiles de PyTorch guardará los rastros en el directorio de registro de su tensorboard . Puede ver estos seguimientos dentro de TensorBoard siguiendo los pasos aquí.
Para usar PyTorch Memory Profiling, configure las opciones de configuración memory_profiling y memory_profiling_path (consulte aquí para conocer el uso de argumentos y aquí para ver una configuración de muestra).
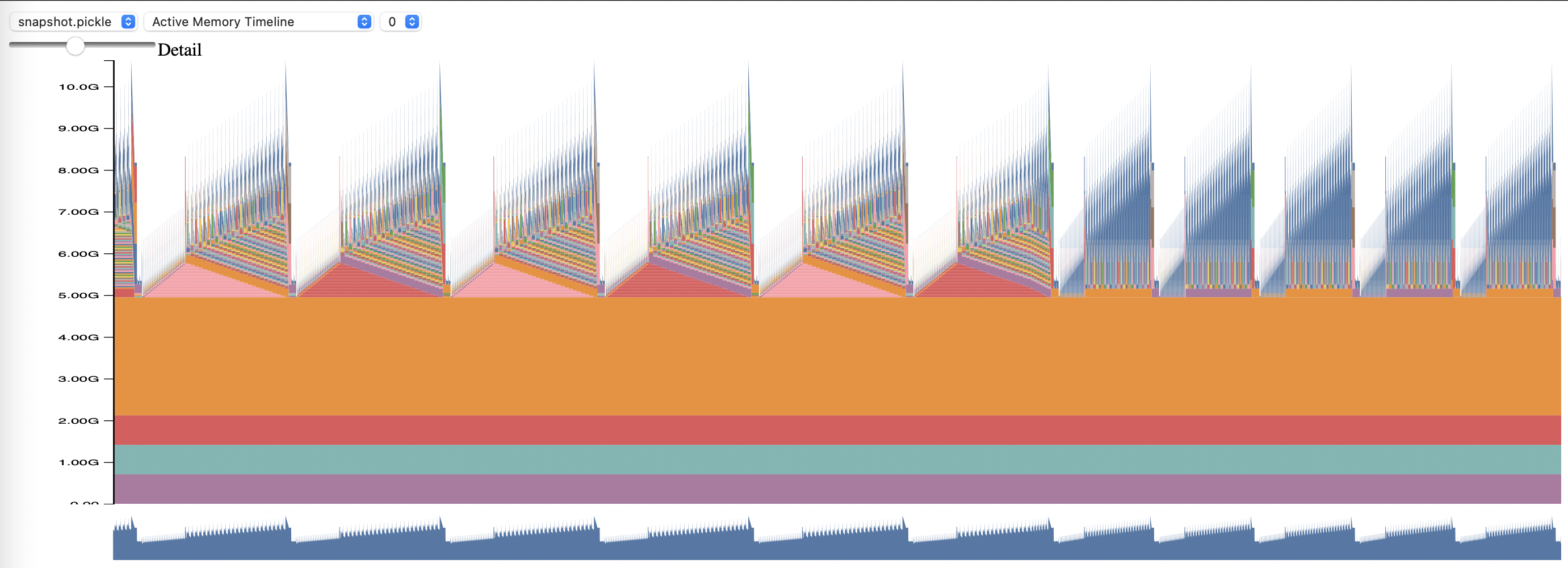
Vea el perfil generado con el script Memory_viz.py. Ejecutar con:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
La biblioteca GPT-NeoX fue ampliamente adoptada por investigadores académicos y de la industria y trasladada a muchos sistemas HPC.
Si esta biblioteca le ha resultado útil en su investigación, ¡comuníquese con nosotros y háganoslo saber! Nos encantaría agregarte a nuestras listas.
EleutherAI y nuestros colaboradores lo han utilizado en las siguientes publicaciones:
Las siguientes publicaciones de otros grupos de investigación utilizan esta biblioteca:


