visual chatgpt
1.0.0
Visual ChatGPT conecta ChatGPT y una serie de modelos de Visual Foundation para permitir enviar y recibir imágenes durante el chat.
Vea nuestro artículo: Visual ChatGPT: hablar, dibujar y editar con modelos de Visual Foundation
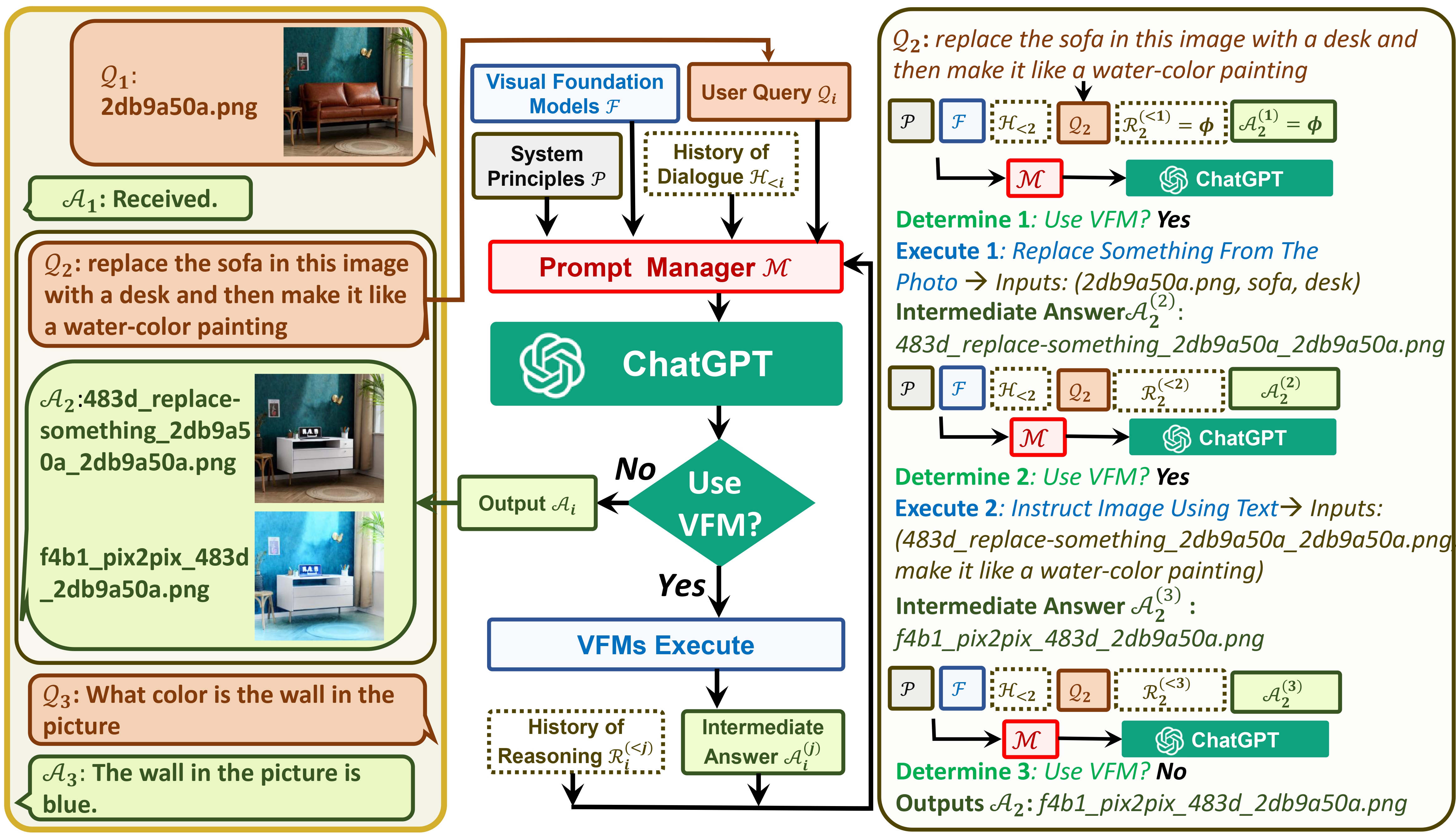
Por un lado, ChatGPT (o LLM) sirve como una interfaz general que proporciona una comprensión amplia y diversa de una amplia gama de temas. Por otro lado, los Foundation Models actúan como expertos en el dominio al proporcionar un conocimiento profundo en dominios específicos. Al aprovechar el conocimiento general y profundo , nuestro objetivo es construir una IA que sea capaz de manejar una variedad de tareas.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Aquí enumeramos el uso de memoria GPU de cada modelo de base visual, puedes especificar cuál te gusta:
| Modelo de cimentación | Memoria GPU (MB) |
|---|---|
| Edición de imágenes | 3981 |
| InstruirPix2Pix | 2827 |
| Texto2Imagen | 3385 |
| Subtítulos de imágenes | 1209 |
| Imagen2Canny | 0 |
| CannyText2Imagen | 3531 |
| Imagen2Linea | 0 |
| LíneaTexto2Imagen | 3529 |
| Imagen2Hed | 0 |
| HedText2Imagen | 3529 |
| Imagen2garabato | 0 |
| ScribbleText2Imagen | 3531 |
| Imagen2Pose | 0 |
| PoseTexto2Imagen | 3529 |
| Imagen2Seg | 919 |
| SegText2Imagen | 3529 |
| Imagen2Profundidad | 0 |
| ProfundidadTexto2Imagen | 3531 |
| Imagen2Normal | 0 |
| TextoNormal2Imagen | 3529 |
| VisualPreguntaRespondiendo | 1495 |
Apreciamos el código abierto de los siguientes proyectos:
Abrazando la cara LangChain Difusión estable ControlNet InstructPix2Pix CLIPSeg BLIP
Para obtener ayuda o problemas al utilizar Visual ChatGPT, envíe un problema de GitHub.
Para otras comunicaciones, comuníquese con Chenfei WU ([email protected]) o Nan DUAN ([email protected]).


