TEMPO
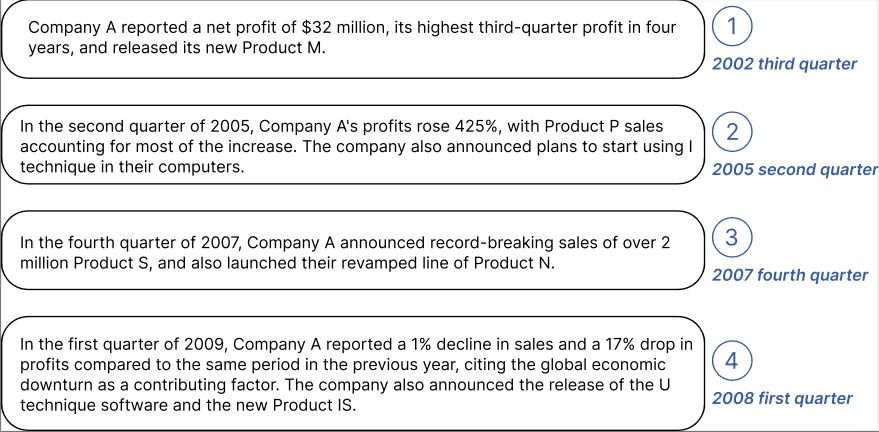
1.0.0

El código oficial para ["TEMPO: Transformador generativo preentrenado basado en indicaciones para pronóstico de series temporales (ICLR 2024)"].
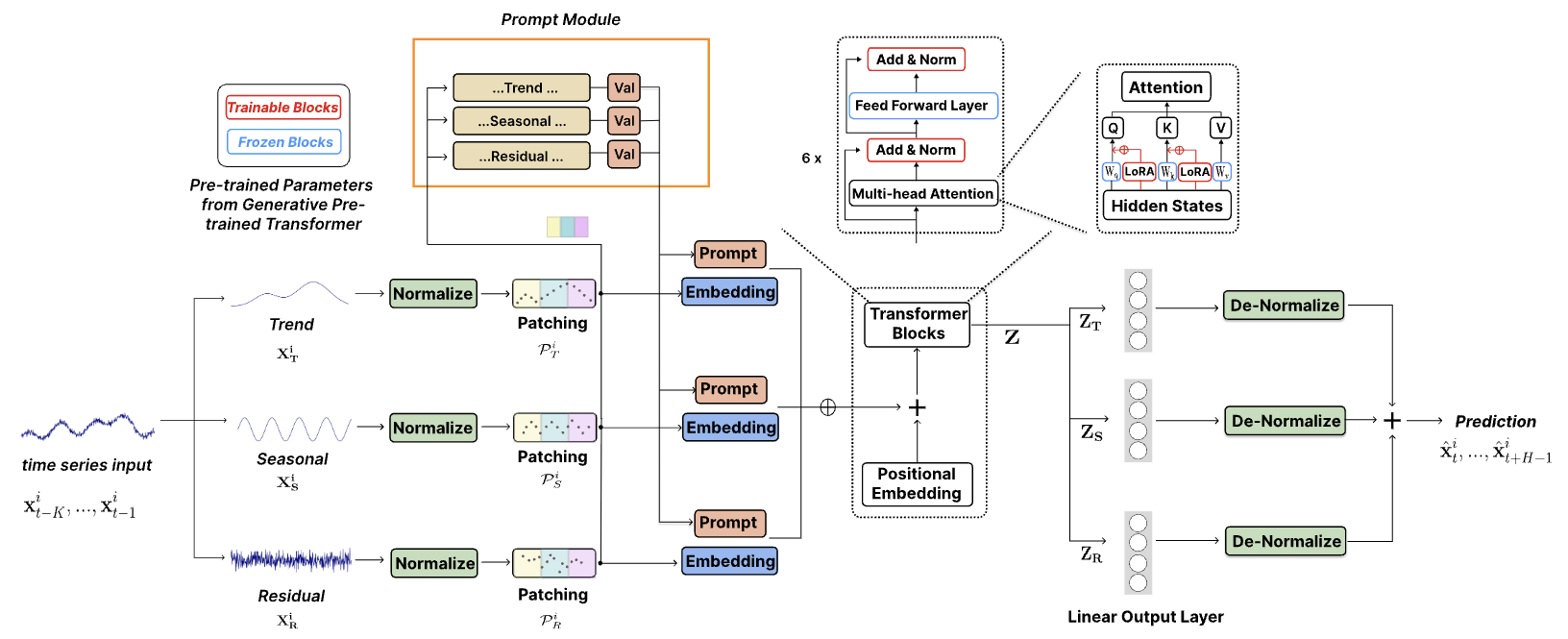
TEMPO es uno de los primeros modelos básicos de series temporales de código abierto para la versión 1.0 de tareas de pronóstico.
Octubre de 2024 : Hemos optimizado nuestra estructura de código, lo que permite a los usuarios descargar el modelo previamente entrenado y realizar inferencias cero con una sola línea de código. Consulte nuestra demostración para obtener más detalles. ¡Ahora se puede rastrear el recuento de descargas de nuestro modelo en HuggingFace!
Junio de 2024 : agregamos demostraciones para reproducir experimentos de disparo cero en Colab. También agregamos la demostración de cómo construir el conjunto de datos del cliente y hacer la inferencia directamente a través de nuestro modelo básico previamente entrenado: Colab.
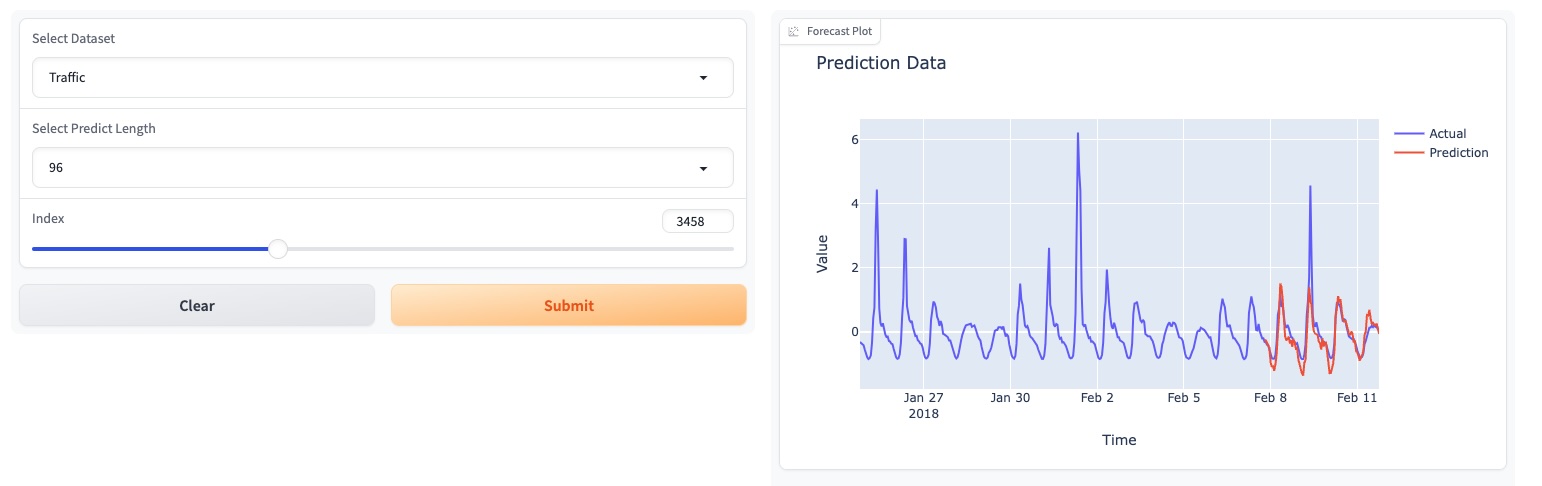
Mayo de 2024 : TEMPO ha lanzado una demostración en línea basada en GUI que permite a los usuarios interactuar directamente con nuestro modelo básico.
Mayo de 2024 : ¡TEMPO publicó el modelo de base previamente entrenado de 80M en HuggingFace!
Mayo de 2024 : ? Agregamos el código para los modelos TEMPO de inferencia y preentrenamiento. Puede encontrar una demostración de script previo al entrenamiento en esta carpeta. También agregamos un script para la demostración de inferencia.
Marzo de 2024 : ? Conjunto de datos TETS publicado del S&P 500 utilizado en experimentos multimodales en TEMPO.
Marzo de 2024 : ? ¡TEMPO publicó en línea el código del proyecto y el punto de control previamente entrenado!
Enero de 2024 : ¡ICLR acepta el artículo TEMPO!
Octubre de 2023 : ¡Se publica el artículo TEMPO en Arxiv!
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
Un ejemplo simplificado que muestra cómo realizar pronósticos usando TEMPO:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )Intente reproducir los experimentos de disparo cero en ETTh2 [aquí en Colab].
Usamos la siguiente página de Colab para mostrar la demostración de cómo crear el conjunto de datos del cliente y hacer la inferencia directamente a través de nuestro modelo básico previamente entrenado: [Colab]
Pruebe nuestra demostración del modelo básico [aquí].
También actualizamos nuestros modelos en HuggingFace: [Melady/TEMPO].
Descargue los datos de [Google Drive] o [Baidu Drive] y coloque los datos descargados en la carpeta ./dataset . También puede descargar los resultados de STL desde [Google Drive] y colocar los datos descargados en la carpeta ./stl .
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
Después del entrenamiento, podemos probar el modelo TEMPO en la configuración de disparo cero:
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
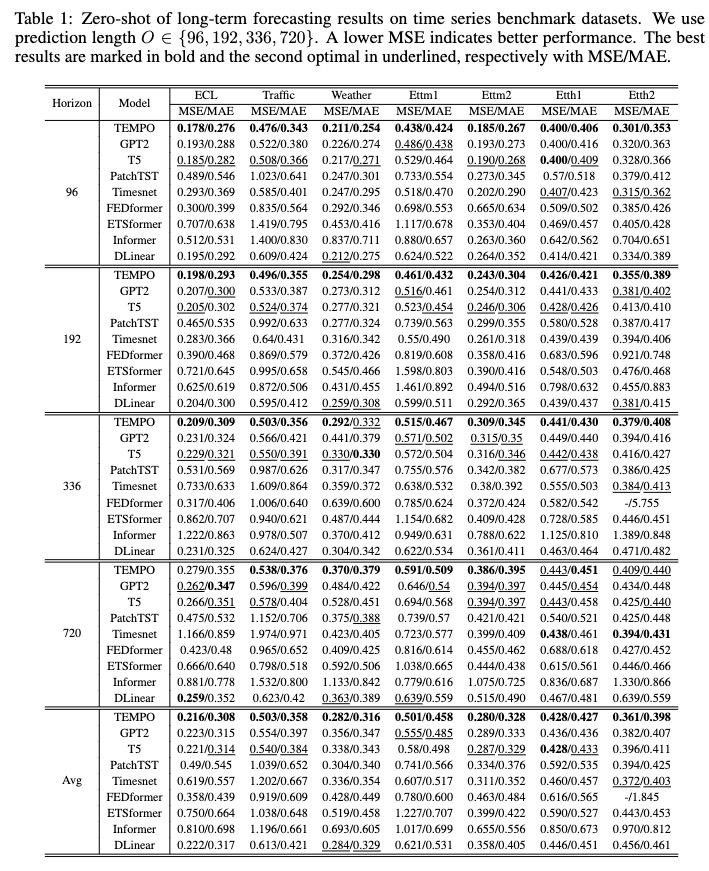
Puede descargar el modelo previamente entrenado desde [Google Drive] y luego ejecutar el script de prueba por diversión.
Aquí se muestran las indicaciones que se utilizan para generar la información textual correspondiente de series temporales a través de [OPENAI ChatGPT-3.5 API]

Los datos de la serie temporal provienen del [S&P 500]. Aquí está el caso de EBITDA de una empresa del conjunto de datos:
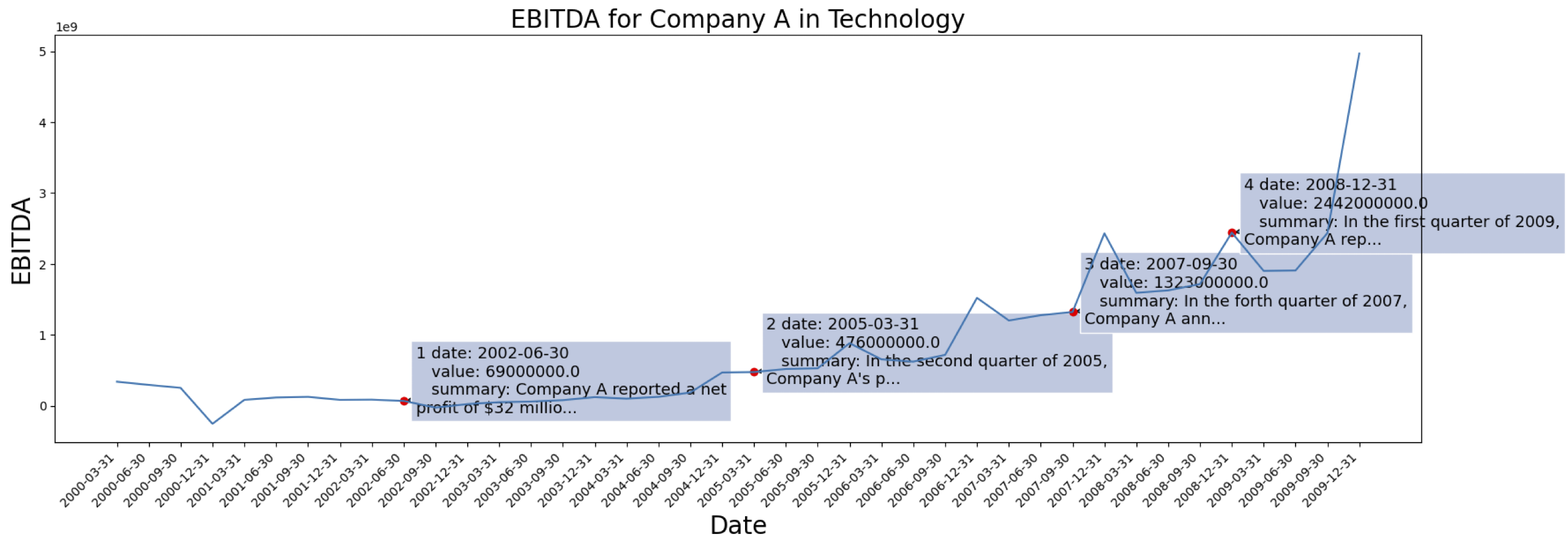
Ejemplo de información contextual generada para la Empresa marcada arriba:
Puede descargar los datos procesados con incrustación de texto desde GPT2 desde: [TETS].
No dude en conectarse con [email protected] / [email protected] si está interesado en aplicar TEMPO a su aplicación del mundo real.
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


