Awesome Attention Heads
vey on LLM attention heads
Importante
Acerca de este repositorio. Esta es una plataforma para obtener las últimas investigaciones sobre diferentes tipos de jefes de atención de LLM. Además, publicamos una encuesta basada en estos fantásticos trabajos.
Si quieres citar nuestro trabajo , aquí tienes nuestra entrada bibtex: CITATION.bib.
Si solo desea ver la lista de artículos relacionados, vaya directamente a aquí.
Si desea contribuir a este repositorio, consulte aquí.
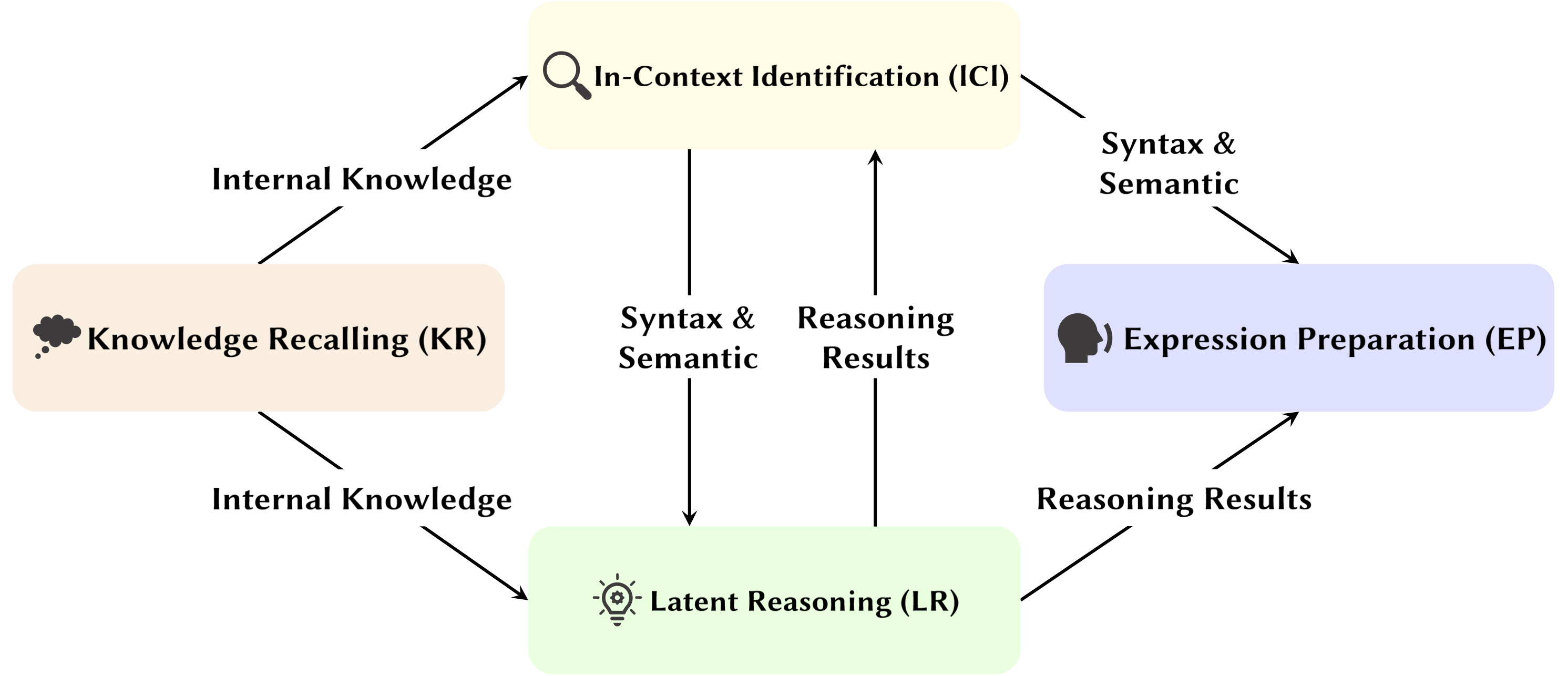
Con el desarrollo del modelo de lenguaje grande (LLM), se está estudiando exhaustivamente su estructura de red subyacente, el transformador. Investigar la estructura del Transformador nos ayuda a mejorar nuestra comprensión de esta "caja negra" y mejorar la interpretabilidad del modelo. Recientemente, ha habido un creciente conjunto de trabajos que sugieren que el modelo contiene dos particiones distintas: mecanismos de atención utilizados para el comportamiento, inferencia y análisis, y redes Feed-Forward (FFN) para el almacenamiento de conocimiento. Lo primero es crucial para revelar las capacidades funcionales del modelo, lo que lleva a una serie de estudios que exploran varias funciones dentro de los mecanismos de atención, lo que hemos denominado Attention Head Mining .
En esta encuesta, profundizamos en los mecanismos potenciales de cómo las cabezas de atención en los LLM contribuyen al proceso de razonamiento.
Reflejos:
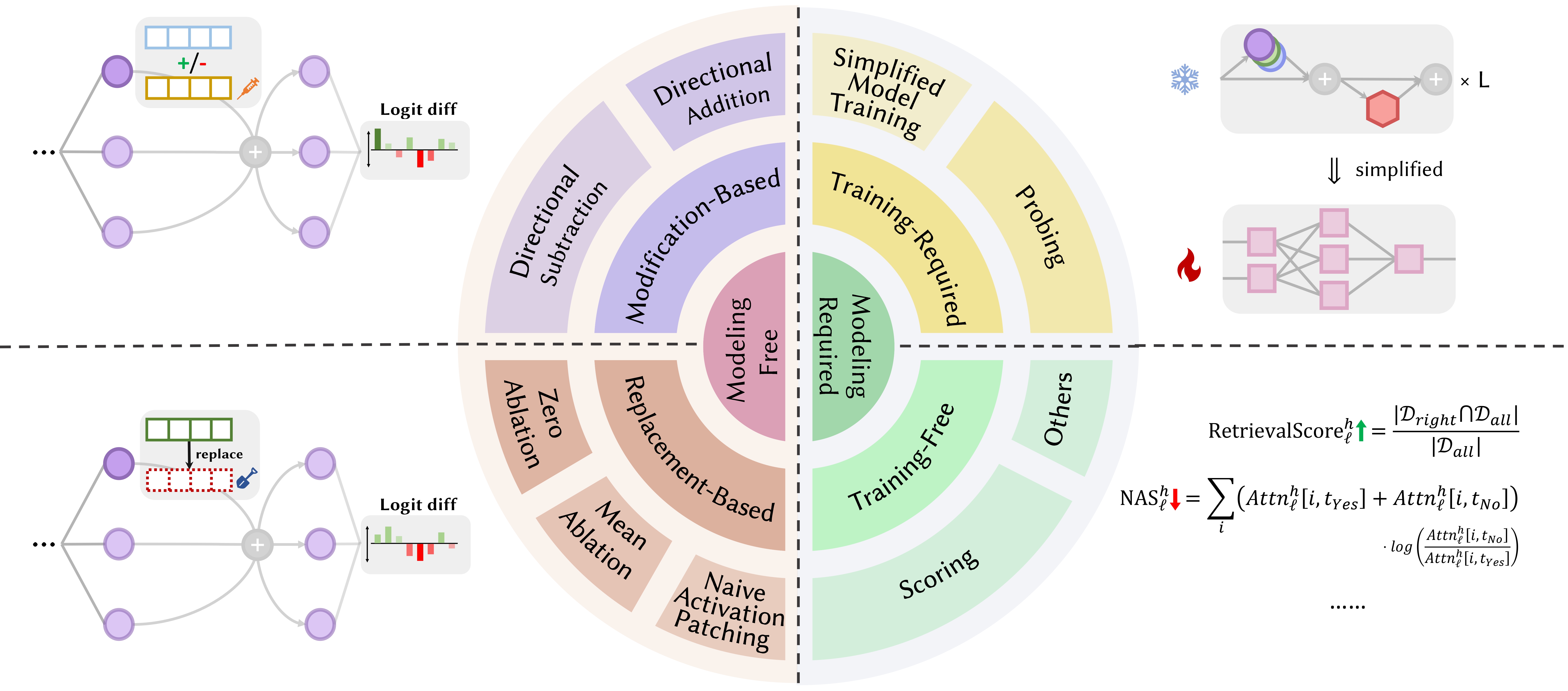
Los artículos a continuación están ordenados por fecha de publicación :
Año 2024
| Fecha | Documento y resumen | Etiquetas | Campo de golf |
| 2024-11-15 | SEEKR: Retención selectiva de conocimientos guiada por atención para el aprendizaje continuo de modelos de lenguaje grandes | ||
| • Propone SEEKR, un método de retención de conocimientos guiado por la atención selectiva para el aprendizaje continuo en LLM, centrándose en las cabezas de atención clave para una destilación eficiente. • Evaluado en los puntos de referencia de aprendizaje continuo TRACE y SuperNI. • SEEKR logró un rendimiento comparable o mejor con sólo el 1% de los datos de repetición en comparación con otros métodos. | |||
| 2024-11-06 | Cómo los transformadores resuelven problemas de lógica proposicional: un análisis mecanicista | ||
| • Identifica circuitos de atención específicos en transformadores que resuelven problemas de lógica proposicional, centrándose en mecanismos de "planificación" y "razonamiento". • Analicé pequeños transformadores y Mistral-7B, usando parches de activación para descubrir vías de razonamiento. • Encontré cabezas de atención distintas que se especializan en localización de reglas, procesamiento de hechos y toma de decisiones en razonamiento lógico. | |||
| 2024-11-01 | Rastreador de atención: detección de ataques de inyección rápidos en LLM | ||
| • Proposed Attention Tracker, una guardia simple pero eficaz sin entrenamiento que detecta ataques de inyección rápidos basados en cabezas importantes identificadas. • Identificó los encabezados importantes utilizando simplemente un pequeño conjunto de oraciones aleatorias generadas por LLM combinadas con un ingenuo ataque de ignorar. • Attention Tracker es eficaz tanto en LM pequeños como grandes, y aborda una limitación importante de los métodos de detección anteriores sin entrenamiento. | |||
| 2024-10-28 | Aritmética sin algoritmos: los modelos de lenguaje resuelven matemáticas con una bolsa de heurísticas | ||
| • Identificó un subconjunto del modelo (un circuito) que explica la mayor parte del comportamiento del modelo para la lógica aritmética básica y examinó su funcionalidad. • Analizaron patrones de atención usando indicaciones aritméticas de dos operandos con números arábigos y los cuatro operadores básicos (+, −, ×, ÷). • Para suma, resta y división, 6 cabezas de atención producen una alta fidelidad (97% en promedio), mientras que la multiplicación requiere 20 cabezas para superar el 90% de fidelidad. | |||
| 2024-10-21 | Una evaluación psicolingüística de la sensibilidad de los modelos lingüísticos a los roles argumentales | ||
| • Cabeza del sujeto observada en un entorno más generalizado. • Análisis de patrones de atención bajo la condición de argumentos de intercambio y argumentos de reemplazo. • A pesar de ser capaces de distinguir roles, los modelos pueden tener dificultades para utilizar correctamente la información argumental sobre roles, ya que el problema radica en cómo esta información se codifica en representaciones verbales, lo que resulta en una sensibilidad de roles más débil. | |||
| 2024-10-17 | Cabezas de atención activa-inactiva: desmitificando mecánicamente los fenómenos de tokens extremos en los LLM | ||
| • Se demostró que los fenómenos simbólicos extremos surgen de un mecanismo activo-latente en las cabezas de atención, junto con un mecanismo de refuerzo mutuo durante el preentrenamiento. • Usar transformadores simples entrenados en la tarea Bigram-Backcopy (BB) para analizar fenómenos simbólicos extremos y extenderlo a LLM previamente capacitados. • Muchas de las propiedades estáticas y dinámicas de los fenómenos de tokens extremos predichos por la tarea BB se alinean con las observaciones en LLM previamente entrenados. | |||
| 2024-10-17 | Sobre el papel de las cabezas de atención en la seguridad de los modelos de lenguaje grande | ||
| • Propuso una métrica novedosa adaptada a la atención de múltiples cabezales, Safety Head ImPortant Score (Ships), para evaluar las contribuciones de los cabezales individuales a la seguridad del modelo. • Realización de análisis sobre la funcionalidad de estos cabezales de atención de seguridad, explorando sus características y mecanismos. • Ciertos cabezales de atención son cruciales para la seguridad, los cabezales de seguridad se superponen en los modelos ajustados y la ablación de estos cabezales afecta mínimamente la utilidad. | |||
| 2024-10-14 | DuoAttention: inferencia eficiente de LLM de contexto largo con cabezales de recuperación y transmisión | ||
| • Se presentó DuoAttention, un marco que reduce la decodificación y la memoria de prellenado y la latencia de LLM sin comprometer sus capacidades de contexto largo, basado en el descubrimiento de Retrieval Heads y Streaming Heads dentro de LLM. • Probar el impacto del marco en el desempeño de LLM en tareas de contexto corto y largo, así como su eficiencia de inferencia. • Al aplicar una caché KV completa sólo a los cabezales de recuperación, DuoAttention reduce significativamente el uso de memoria y la latencia tanto para la decodificación como para el precargado en aplicaciones de contexto largo. | |||
| 2024-10-14 | Bloqueando la seguridad de los LLM perfeccionados | ||
| • Se presentó SafetyLock, un método novedoso y eficiente para mantener la seguridad de grandes modelos de lenguaje ajustados en varios niveles de riesgo y escenarios de ataque, basado en el descubrimiento de Safety Heads dentro de LLM. • Evaluar la eficacia de SafetyLock para mejorar la seguridad del modelo y la eficiencia de inferencia. • Al aplicar vectores de intervención a los cabezales de seguridad, SafetyLock puede modificar las activaciones internas del modelo para que sean inofensivas durante la inferencia, logrando una alineación de seguridad precisa con un impacto mínimo en la respuesta. | |||
| 2024-10-11 | Lo mismo pero diferente: similitudes y diferencias estructurales en el modelado del lenguaje multilingüe | ||
| • Se llevó a cabo un estudio en profundidad de los componentes específicos en los que se basan los modelos multilingües cuando realizan tareas que requieren procesos morfológicos específicos del idioma. • Investigar las diferencias funcionales de los componentes internos del modelo al realizar tareas en inglés y chino. • El encabezado del texto tiene una frecuencia de activación igualmente alta en ambos idiomas, mientras que el encabezado del tiempo pasado sólo se activa con frecuencia en inglés. | |||
| 2024-10-08 | ¡Vueltas y vueltas vamos! ¿Qué hace que las codificaciones posicionales rotativas sean útiles? | ||
| • Proporcionó un análisis en profundidad de las partes internas de un modelo Gemma 7B entrenado para comprender cómo se utiliza RoPE a nivel mecánico. • Entendí el uso de diferentes frecuencias en las consultas y claves. • Se descubrió que Gemma 7B utiliza inteligentemente las frecuencias más altas en RoPE para construir cabezas de atención 'posicionales' especiales (cabezas diagonales, cabeza de ficha anterior), mientras que las frecuencias bajas son utilizadas por la cabeza Apostrophe. | |||
| 2024-10-06 | Revisando el circuito de inferencia de aprendizaje en contexto en modelos de lenguaje grandes | ||
| • Propuso un circuito de inferencia integral de 3 pasos para caracterizar el proceso de inferencia de ICL. • Divida ICL en tres etapas: Resumir, Fusión semántica y Recuperación y copia de funciones, analizando el papel que desempeña cada etapa en ICL y su mecanismo operativo. • Se descubrió que antes de los encabezados de inducción, los encabezados de tokens Forerunner primero fusionan las representaciones de texto de demostración del token precursor en sus tokens de etiqueta correspondientes, de manera selectiva según la compatibilidad entre la demostración y la semántica de la etiqueta. | |||
| 2024-10-01 | Descomposición de atención escasa aplicada al rastreo de circuitos | ||
| • Introduce la descomposición de atención dispersa, que utiliza SVD en matrices de cabeza de atención para rastrear rutas de comunicación en modelos GPT-2. • Aplicado al rastreo de circuitos en GPT-2 pequeño para la tarea de Identificación indirecta de objetos (IOI). • Se identificaron señales de comunicación escasas y funcionalmente significativas entre cabezas de atención, lo que mejoró la interpretabilidad. | |||
| 2024-09-09 | Presentación de cabezales de inducción: dinámica de entrenamiento demostrable y aprendizaje de funciones en transformadores | ||
| • El artículo presenta un mecanismo de cabeza de inducción generalizado y explica cómo los componentes del transformador colaboran para realizar aprendizaje en contexto (ICL) en cadenas de Markov de n-gramas. • Analiza un transformador de dos capas de atención con flujo gradiente para predecir tokens en cadenas de Markov. • El flujo de gradiente converge, lo que permite ICL a través de un mecanismo de cabezal de inducción basado en características aprendidas. | |||
| 2024-08-16 | Una interpretación mecanicista del razonamiento silogístico en modelos de lenguaje autorregresivos | ||
| • El estudio introduce una interpretación mecanicista del razonamiento silogístico en LM, identificando circuitos de razonamiento independientes del contenido. • Descubrimiento de circuitos para el razonamiento e investigación de la contaminación por sesgos de creencias en las cabezas de atención. • Identificó un circuito de razonamiento necesario transferible a través de esquemas silogísticos, pero susceptible a la contaminación por conocimiento mundial previamente entrenado. | |||
| 2024-08-01 | Mejora de la coherencia semántica de modelos de lenguaje grandes mediante la edición de modelos: un enfoque orientado a la interpretabilidad | ||
| • Introduce un enfoque de edición de modelos rentable que se centra en las cabezas de atención para mejorar la coherencia semántica en los LLM sin cambios extensos de parámetros. • Analicé cabezas de atención, inyecté sesgos y probé en conjuntos de datos NLU y NLG. • Logré mejoras notables en la coherencia semántica y el rendimiento de las tareas, con una fuerte generalización entre tareas adicionales. | |||
| 2024-07-31 | Corrección del sesgo negativo en modelos de lenguaje grandes mediante la alineación de la puntuación de atención negativa | ||
| • Se introdujo el puntaje de atención negativa (NAS, por sus siglas en inglés) para cuantificar y corregir el sesgo negativo en los modelos de lenguaje. • Se identificaron cabezas de atención con sesgos negativos y se propuso una alineación de puntuación de atención negativa (NASA) para realizar ajustes. • La NASA redujo efectivamente la brecha de precisión-recuerdo preservando al mismo tiempo la generalización en tareas de decisión binaria. | |||
| 2024-07-29 | Detectar y comprender vulnerabilidades en modelos de lenguaje mediante interpretabilidad mecanicista | ||
| • Introduce un método que utiliza Interpretabilidad Mecanística (MI) para detectar y comprender vulnerabilidades en LLM, particularmente ataques adversarios. • Analiza GPT-2 Small en busca de vulnerabilidades en la predicción de siglas de 3 letras. • Identifica y explica con éxito vulnerabilidades específicas en el modelo relacionadas con la tarea. | |||
| 2024-07-22 | RazorAttention: Compresión eficiente de caché KV a través de cabezales de recuperación | ||
| • Se presentó RazorAttention, una técnica de compresión de caché KV sin capacitación que utiliza cabezales de recuperación y tokens de compensación para preservar la información crítica de los tokens. • Se evaluó RazorAttention en modelos de lenguajes grandes (LLM) para determinar su eficiencia. • Se logró una reducción del tamaño de la caché KV de más del 70 % sin impacto notable en el rendimiento. | |||
| 2024-07-21 | Responda, reúna, as: comprenda cómo los transformadores responden preguntas de opción múltiple | ||
| • El artículo presenta la proyección de vocabulario y parches de activación para localizar estados ocultos que predicen las respuestas correctas de MCQA. • Se identificaron jefes de atención clave y capas responsables de la selección de respuestas en transformadores. • Las cabezas de atención de la capa intermedia son cruciales para una predicción precisa de las respuestas, y un conjunto escaso de cabezas desempeñan funciones únicas. | |||
| 2024-07-09 | Cabezas de inducción como mecanismo esencial para la coincidencia de patrones en el aprendizaje en contexto | ||
| • El artículo identifica los cabezales de inducción como cruciales para la coincidencia de patrones en el aprendizaje en contexto (ICL). • Evalué Llama-3-8B e InternLM2-20B en reconocimiento de patrones abstractos y tareas de PNL. • La ablación de los cabezales de inducción reduce el rendimiento de ICL hasta ~32%, acercándolo al azar para el reconocimiento de patrones. | |||
| 2024-07-02 | Interpretación del mecanismo aritmético en modelos de lenguaje grandes mediante análisis comparativo de neuronas | ||
| • Introduce el Análisis Comparativo de Neuronas (CNA) para mapear mecanismos aritméticos en cabezas de atención de modelos de lenguaje grandes. • Se analizó la capacidad aritmética, la poda de modelos para tareas aritméticas y la edición de modelos para reducir el sesgo de género. • Se identificaron neuronas específicas responsables de la aritmética, lo que permitió mejorar el rendimiento y mitigar el sesgo mediante la manipulación neuronal específica. | |||
| 2024-07-01 | Dirección de modelos de lenguajes grandes para la recuperación de información en varios idiomas | ||
| • Introduce la recuperación multilingüe dirigida por activación (ASMR), que utiliza activaciones de dirección para guiar a los LLM para mejorar la recuperación de información en varios idiomas. • Se identificaron cabezas de atención en LLM que afectan la precisión y la coherencia del lenguaje, y se aplicaron activaciones de dirección. • ASMR logró un rendimiento de vanguardia en puntos de referencia CLIR como XOR-TyDi QA y MKQA. | |||
| 2024-06-25 | Cómo los transformadores aprenden la estructura causal con el descenso de gradientes | ||
| • Proporcionó una explicación de cómo los transformadores aprenden estructuras causales a través de algoritmos de entrenamiento basados en gradientes. • Analicé el desempeño de transformadores de dos capas en una tarea llamada secuencias aleatorias con estructura causal. • El descenso de gradiente en un transformador simplificado de dos capas aprende a resolver esta tarea codificando el gráfico causal latente en la primera capa de atención. Como caso especial, cuando las secuencias se generan a partir de cadenas de Markov en contexto, los transformadores aprenden a desarrollar un cabezal de inducción. | |||
| 2024-06-21 | MoA: combinación de escasa atención para la compresión automática de modelos de lenguaje grande | ||
| • El artículo presenta la Mezcla de Atención (MoA), que adapta distintas configuraciones de atención dispersa para diferentes cabezales y capas, optimizando la memoria, el rendimiento y las compensaciones entre precisión y latencia. • MoA perfila modelos, explora configuraciones de atención y mejora la compresión LLM. • MoA aumenta la longitud efectiva del contexto en 3,9 veces, al tiempo que reduce el uso de memoria de la GPU entre 1,2 y 1,4 veces. | |||
| 2024-06-19 | Sobre la dificultad de un razonamiento fiel en cadena de pensamiento en modelos de lenguaje grandes | ||
| • Se introdujeron estrategias novedosas para el aprendizaje en contexto, el ajuste y la edición de activación para mejorar la fidelidad del razonamiento de la Cadena de Pensamiento (CoT) en los LLM. • Probé estas estrategias en múltiples puntos de referencia para evaluar su efectividad. • Solo se encontró un éxito limitado en mejorar la fidelidad de CoT, destacando el desafío de lograr un razonamiento verdaderamente fiel en los LLM. | |||
| 2024-06-04 | Cabezal de iteración: un estudio mecanicista de la cadena de pensamiento | ||
| • Introduce "cabezas de iteración", cabezas de atención especializadas que permiten el razonamiento iterativo en transformadores para tareas de cadena de pensamiento (CoT). • Análisis de los mecanismos de atención, seguimiento de la aparición de CoT y prueba de la transferibilidad de habilidades de CoT entre tareas. • Los cabezales de iteración respaldan eficazmente el razonamiento CoT, mejorando la interpretabilidad del modelo y el desempeño de las tareas. | |||
| 2024-06-03 | LoFiT: ajuste localizado en representaciones de LLM | ||
| • Introduce el ajuste localizado de representaciones LLM (LoFiT), un marco de dos pasos para identificar importantes cabezas de atención de una tarea determinada y aprender vectores de compensación específicos de la tarea para intervenir en las representaciones de las cabezas identificadas. • Se identificaron conjuntos dispersos de cabezas de atención importantes para mejorar la precisión posterior en la veracidad y el razonamiento. • LoFiT superó a otros métodos de intervención de representación y logró un rendimiento comparable a los métodos PEFT en TruthfulQA, CLUTRR y MQuAKE, a pesar de intervenir solo en el 10% del total de cabezas de atención en LLM. | |||
| 2024-05-28 | Circuitos de conocimiento en transformadores preentrenados | ||
| • Se introdujeron "circuitos de conocimiento" en los transformadores, que revelaron cómo se codifica el conocimiento específico a través de la interacción entre las cabezas de atención, las cabezas de relación y los MLP. • Análisis de GPT-2 y TinyLLAMA para identificar circuitos de conocimiento; Se evaluaron técnicas de edición de conocimientos. • Demostró cómo los circuitos de conocimiento contribuyen a modelar comportamientos como alucinaciones y aprendizaje en contexto. | |||
| 2024-05-23 | Vincular el aprendizaje en contexto en Transformers con la memoria episódica humana | ||
| • Vincula el aprendizaje en contexto en los modelos Transformer con la memoria episódica humana, destacando las similitudes entre los cabezales de inducción y el modelo de mantenimiento y recuperación contextual (CMR). • Análisis de LLM basados en Transformer para demostrar un comportamiento similar a CMR en cabezas de atención. • Cabezas tipo CMR emergen en capas intermedias, reflejando los sesgos de la memoria humana. | |||
| 2024-05-07 | ¿Cómo predice GPT-2 las siglas? Extracción y comprensión de un circuito mediante interpretabilidad mecanística | ||
| • Primer estudio de interpretabilidad mecanicista en GPT-2 para predecir acrónimos multitoken usando cabezas de atención. • Identifiqué e interpreté un circuito de 8 cabezas de atención responsables de la predicción de siglas. • Se demostró que estos 8 cabezales (~5% del total) concentran la funcionalidad de predicción de acrónimos. | |||
| 2024-05-02 | Interpretación y mejora de modelos de lenguaje grandes en cálculo aritmético | ||
| • Introduce una investigación detallada de los mecanismos internos de los LLM a través de tareas matemáticas, siguiendo el proceso de 'identificar-analizar-afinar'. • Analizó la capacidad del modelo para realizar tareas aritméticas que involucran dos operandos, como suma, resta, multiplicación y división. • Se descubrió que los LLM frecuentemente involucran una pequeña fracción (< 5%) de cabezas de atención, que desempeñan un papel fundamental al centrarse en operandos y operadores durante los procesos de cálculo. | |||
| 2024-05-02 | ¿Qué debe funcionar correctamente en un cabezal de inducción? Un estudio mecanicista de los circuitos de aprendizaje en contexto y su formación. | ||
| • Introdujo un marco causal inspirado en la optogenética para estudiar la formación de cabezas de inducción (IH) en transformadores. • Analizó la aparición de IH en transformadores utilizando datos sintéticos e identificó tres subcircuitos subyacentes responsables de la formación de IH. • Descubrió que estos subcircuitos interactúan para impulsar la formación de IH, coincidiendo con un cambio de fase en la pérdida del modelo. | |||
| 2024-04-24 | El jefe de recuperación explica mecánicamente la factualidad del contexto largo | ||
| • Se identificaron "cabezales de recuperación" en modelos de transformadores responsables de recuperar información en contextos prolongados. • Investigación sistemática de cabezas de recuperación en varios modelos, incluido el análisis de su papel en el razonamiento de cadenas de pensamiento. • Podar las cabezas recuperables provoca alucinaciones, mientras que podar las cabezas no recuperables no afecta la capacidad de recuperación. | |||
| 2024-03-27 | Intervención de tiempo de inferencia no lineal: mejora de la veracidad del LLM | ||
| • Se introdujo la Intervención de tiempo de inferencia no lineal (NL-ITI), que mejora la veracidad del LLM mediante sondeo e intervención de múltiples tokens sin ajustes. • Se evaluó NL-ITI en conjuntos de datos de opción múltiple, incluido TruthfulQA. • Logró una mejora relativa del 16 % en la precisión de MC1 en TruthfulQA con respecto al ITI inicial. | |||
| 2024-02-28 | Cómo pensar paso a paso: una comprensión mecanicista del razonamiento en cadena de pensamientos | ||
| • Proporcionó un análisis en profundidad del razonamiento mediado por CoT en LLM en términos de los componentes funcionales neuronales. • Se diseccionó el razonamiento basado en CoT sobre razonamiento ficticio como una composición de un número fijo de subtareas que requieren toma de decisiones, copia y razonamiento inductivo, analizando su mecanismo por separado. • Se descubrió que las cabezas de atención realizan movimientos de información entre tokens relacionados ontológicamente (o relacionados negativamente), lo que resulta en representaciones claramente identificables para estos pares de tokens. | |||
| 2024-02-28 | Cortar la cabeza pone fin al conflicto: un mecanismo para interpretar y mitigar los conflictos de conocimiento en modelos lingüísticos | ||
| • Introduce el método PH3 para eliminar las cabezas de atención conflictivas, mitigando los conflictos de conocimiento en modelos de lenguaje sin actualizaciones de parámetros. • Se aplicó PH3 para controlar la dependencia de los LM de la memoria interna versus el contexto externo y se probó su efectividad en tareas de control de calidad de dominio abierto. • PH3 mejoró el uso de la memoria interna en un 44,0% y el uso del contexto externo en un 38,5%. | |||
| 2024-02-27 | Rutas de flujo de información: interpretación automática de modelos de lenguaje a escala | ||
| • Introduce "Rutas de flujo de información" que utilizan la atribución para la interpretación basada en gráficos de modelos de lenguaje, evitando parches de activación. • Experimentos con Llama 2, identificando cabezas de atención clave y patrones de comportamiento en diferentes dominios y tareas. • Componentes de modelo especializados descubiertos; identificó roles consistentes para las cabezas de atención, como el manejo de fichas de la misma parte del discurso. | |||
| 2024-02-20 | Identificación de cabezas de inducción semántica para comprender el aprendizaje en contexto | ||
| • Identifica y estudia "cabezas de inducción semántica" en modelos de lenguaje grandes (LLM) que se correlacionan con habilidades de aprendizaje en contexto. • Análisis de cabezas de atención para codificar dependencias sintácticas y relaciones de gráficos de conocimiento. • Ciertas cabezas de atención mejoran los logs de salida al recordar tokens relevantes, cruciales para comprender el aprendizaje en contexto en los LLM. | |||
| 2024-02-16 | La evolución de las cabezas de inducción estadística: cadenas de Markov de aprendizaje en contexto | ||
| • Introduce una tarea de modelado de secuencia de Cadena de Markov para analizar cómo las capacidades de aprendizaje en contexto (ICL) emergen en los transformadores, formando "cabezas de inducción estadística". • Investigación empírica y teórica del entrenamiento multifase en transformadores en tareas de Cadena de Markov. • Demuestra transiciones de fase de predicciones de unigrama a bigrama, influenciadas por las interacciones de la capa del transformador. | |||
| 2024-02-11 | Resumiendo los hechos: mecanismos aditivos detrás del recuerdo de hechos en los LLM | ||
| • Identifica y explica el "motivo aditivo" en el recuerdo de hechos, donde los LLM utilizan múltiples mecanismos independientes que interfieren constructivamente para recordar hechos. • Atribución logit directa extendida para analizar las cabezas de atención y analizar el comportamiento de las cabezas mixtas. • Demostró que el recuerdo de hechos en los LLM resulta de la suma de múltiples contribuciones independientes e insuficientes. | |||
| 2024-02-05 | ¿Cómo aprenden en contexto los modelos de lenguajes grandes? Las consultas y las matrices clave de los encabezados en contexto son dos torres para el aprendizaje métrico | ||
| • Introduce el concepto de que las matrices de consultas y claves en encabezados en contexto operan como "dos torres" para el aprendizaje métrico, facilitando el cálculo de similitud entre características de etiquetas. • Se analizaron los mecanismos de aprendizaje en contexto; identificó áreas de atención específicas cruciales para ICL. • Se redujo la precisión de ICL del 87,6% al 24,4% al intervenir solo en el 1% de estos cabezales. | |||
| 2024-01-23 | Aprendizaje de idiomas en contexto: arquitecturas y algoritmos | ||
| • Introducción de "cabezas de n-gramas", cabezas de atención Transformer especializadas, que mejoran el aprendizaje de idiomas en contexto (ICLL) a través de la predicción de tokens condicionales de entrada. • Evaluación de modelos neuronales en lenguajes regulares a partir de autómatas finitos aleatorios. • Los cabezales de n-gramas cableados mejoraron la perplejidad en un 6,7% en el conjunto de datos SlimPajama. | |||
| 2024-01-16 | La base mecanicista de la dependencia de datos y el aprendizaje abrupto en una tarea de clasificación en contexto | ||
| • El artículo modela la base mecanicista del aprendizaje en contexto (ICL) mediante la formación abrupta de cabezas de inducción en redes de atención únicamente. • Tareas ICL simuladas utilizando datos de entrada simplificados y una red basada en la atención de dos capas. • La formación del cabezal de inducción impulsa la transición abrupta a ICL, trazada a través de no linealidades anidadas. | |||
| 2024-01-16 | Reutilización de componentes de circuitos en tareas en modelos de lenguaje de transformadores | ||
| • El artículo demuestra que los circuitos específicos en GPT-2 pueden generalizarse en diferentes tareas, desafiando la noción de que dichos circuitos son específicos de una tarea. • Examina la reutilización de circuitos de la tarea de Identificación indirecta de objetos (IOI) en la tarea de Objetos de colores. • Ajustar cuatro cabezales de atención aumenta la precisión del 49,6% al 93,7% en la tarea Objetos de colores. | |||
| 2024-01-16 | Cabezas sucesoras: cabezas de atención recurrentes e interpretables en la naturaleza | ||
| • El artículo presenta "Cabezas sucesoras", cabezas de atención en LLM que incrementan los tokens con ordenamiento natural, como días o números. • Analiza la formación de cabezas sucesoras en varios tamaños de modelos y arquitecturas, como GPT-2 y Llama-2. • Las cabezas sucesoras se encuentran en modelos que van desde parámetros 31M a 12B, revelando representaciones numéricas abstractas y recurrentes. | |||
| 2024-01-16 | Vectores de funciones en modelos de lenguaje grandes | ||
| • El artículo presenta "Vectores de función (FV)", representaciones causales compactas de tareas dentro de modelos de transformadores autorregresivos. • Los FV se probaron en diversas tareas, modelos y capas de aprendizaje en contexto (ICL). • Los FV se pueden sumar para crear vectores que desencadenen tareas nuevas y complejas, lo que demuestra la composición interna de los vectores. | |||
| Fecha | Documento y resumen | Etiquetas | Campo de golf |
| 2023-12-23 | Investigación de hechos: intento de realizar ingeniería inversa para recordar hechos a nivel neuronal | ||
| • Se investigó cómo las primeras capas MLP en Pythia 2.8B codifican la recuperación de hechos utilizando circuitos distribuidos, centrándose en la superposición y la incrustación de múltiples tokens. • Se exploró la búsqueda de hechos en capas de MLP, se probaron hipótesis sobre mecanismos de detokenización y hash. • La recuperación de hechos funciona como una tabla de consulta distribuida sin mecanismos internos fácilmente interpretables. | |||
| 2023-11-07 | Hacia la continuación de una secuencia interpretable: análisis de circuitos compartidos en modelos de lenguaje grandes | ||
| • Demostró la existencia de circuitos compartidos para tareas similares de continuación de secuencias. • Analizaron y compararon circuitos para tareas de continuación de secuencias similares, que incluyen secuencias crecientes de números arábigos, palabras numéricas y meses. • Las secuencias semánticamente relacionadas se basan en subgrafos de circuitos compartidos con funciones análogas y en el hallazgo de subcircuitos similares en modelos con funcionalidad análoga. | |||
| 2023-10-23 | Representaciones lineales de sentimiento en modelos de lenguaje grandes | ||
| • El artículo identifica una dirección lineal en el espacio de activación que captura la representación de sentimientos en modelos de lenguaje grandes (LLM). • Aislaron esta dirección de sentimiento y la probaron en tareas que incluyen Stanford Sentiment Treebank. • La eliminación de esta dirección del sentimiento conduce a una reducción del 76% en la precisión de la clasificación, lo que resalta su importancia. | |||
| 2023-10-06 | Supresión de copias: comprensión integral de la cabeza de atención | ||
| • El artículo presenta el concepto de supresión de copia en un cabezal de atención pequeño GPT-2 (L10H7), que reduce la copia ingenua de tokens y mejora la calibración del modelo. • El artículo investiga y explica el mecanismo de supresión de copias y su papel en la autorreparación . • Se explica el 76,9% del impacto de L10H7 en GPT-2 Small, lo que la convierte en la descripción más completa del papel de un jefe de atención. | |||
| 2023-09-22 | Intervención en tiempo de inferencia: obtención de respuestas veraces a partir de un modelo de lenguaje | ||
| • Se introdujo la Intervención en tiempo de inferencia (ITI) para mejorar la veracidad del LLM ajustando las activaciones del modelo en cabezas de atención seleccionadas. • Se mejoró el rendimiento del modelo LLaMA en el punto de referencia TruthfulQA. • ITI incrementó la veracidad del modelo Alpaca de 32,5% a 65,1%. | |||
| 2023-09-22 | Nacimiento de un transformador: un punto de vista de la memoria | ||
| • El artículo presenta una perspectiva basada en la memoria sobre los transformadores, destacando las memorias asociativas en matrices de peso y su aprendizaje impulsado por gradientes. • Análisis empírico de la dinámica de entrenamiento sobre un modelo de transformador simplificado con datos sintéticos. • Descubrimiento de un rápido aprendizaje global de bigramas y la aparición más lenta de una "cabeza de inducción" para bigramas en contexto. | |||
| 2023-09-13 | Caídas repentinas de las pérdidas: adquisición de sintaxis, transiciones de fase y sesgo de simplicidad en los MLM | ||
| • Identifica la estructura de atención sintáctica (SAS) como una propiedad que emerge naturalmente en los modelos de lenguaje enmascarado (MLM) y su papel en la adquisición de sintaxis. • Analiza SAS durante el entrenamiento y lo manipula para estudiar su efecto causal en las capacidades gramaticales. • SAS es necesario para el desarrollo de la gramática, pero suprimirlo brevemente mejora el rendimiento del modelo. | |||
| 2023-07-18 | ¿Se escala la interpretabilidad del análisis de circuitos? Evidencia de capacidades de opción múltiple en Chinchilla | ||
| • Análisis de circuitos escalables aplicados a un modelo de lenguaje Chinchilla 70B para comprender la respuesta a preguntas de opción múltiple. • Atribución logit, visualización de patrones de atención y parches de activación para identificar y categorizar cabezas de atención clave. • Se identificó la característica "Enésimo elemento en una enumeración" en los encabezados de atención, aunque es sólo una explicación parcial. | |||
| 2023-02-02 | Interpretabilidad en la naturaleza: un circuito para la identificación indirecta de objetos en GPT-2 pequeño | ||
| • El artículo presenta una explicación detallada de cómo GPT-2 pequeño realiza la identificación indirecta de objetos (IOI) utilizando un circuito grande que involucra 28 cabezas de atención agrupadas en 7 clases. • Realizaron ingeniería inversa de la tarea IOI en GPT-2 pequeño utilizando intervenciones y proyecciones causales. • El estudio demuestra que la interpretabilidad mecanicista de grandes modelos lingüísticos es factible. | |||
| Fecha | Documento y resumen | Etiquetas | Campo de golf |
| 2022-03-08 | Jefes de inducción y aprendizaje en contexto | ||
| • El artículo identifica "cabezas de inducción" en modelos Transformer, que permiten el aprendizaje en contexto reconociendo y copiando patrones en secuencias. • Analiza patrones de atención y cabezales de inducción en varias capas en diferentes modelos de Transformer. • Se descubrió que los cabezales de inducción son cruciales para permitir que los Transformers generalicen y realicen tareas de aprendizaje en contexto de manera efectiva. | |||
| 2021-12-22 | Un marco matemático para circuitos de transformadores | ||
| • Introduce un marco matemático para aplicar ingeniería inversa a pequeños transformadores de atención únicamente, centrándose en comprender las cabezas de atención como componentes independientes y aditivos. • Se analizaron transformadores de cero, una y dos capas para identificar el papel de las cabezas de atención en el movimiento y la composición de la información. • Se descubrieron "cabezas de inducción", cruciales para el aprendizaje en contexto en transformadores de dos capas. | |||
| 2021-05-18 | La hipótesis de las cabezas: un enfoque estadístico unificador para comprender la atención de múltiples cabezas en BERT | ||
| • El artículo propone un método novedoso llamado "Atención dispersa" que reduce la complejidad computacional de los mecanismos de atención al centrarse selectivamente en elementos importantes. • El método fue evaluado en tareas de traducción automática y clasificación de textos. • El modelo de atención dispersa logra una precisión comparable a la de la atención densa y, al mismo tiempo, reduce significativamente el costo computacional. | |||
| 2021-04-01 | ¿Los jefes de atención en BERT han aprendido la gramática de los distritos electorales? | ||
| • El estudio introduce un método de distancia sintáctica para analizar la gramática de circunscripción en cabezas de atención BERT y RoBERTa. • Se extrajo y analizó la gramática de los distritos electorales antes y después del ajuste de las tareas de SMS y NLI. • Las tareas NLI aumentan la capacidad de inducir la gramática de los electores, mientras que las tareas SMS la disminuyen en las capas superiores. | |||
| 2019-11-27 | ¿Los cabezales de atención en BERT rastrean las dependencias sintácticas? | ||
| • El artículo investiga si las cabezas de atención individuales en BERT capturan dependencias sintácticas, utilizando ponderaciones de atención para extraer relaciones de dependencia. • Analicé las cabezas de atención de BERT utilizando pesos de atención máximos y árboles de expansión máxima, comparándolos con árboles de dependencia universal. • Algunas cabezas de atención rastrean dependencias sintácticas específicas mejor que las líneas base, pero ninguna cabeza realiza un análisis holístico significativamente mejor. | |||
| 2019-11-01 | Transformadores adaptativamente dispersos | ||
| • Introdujo el transformador disperso adaptativamente usando alfa-entrax para permitir la escasez flexible dependiente del contexto en las cabezas de atención. • Se aplicó a los conjuntos de datos de traducción automática para evaluar la interpretabilidad y la diversidad de la cabeza. • logró diversas distribuciones de atención y una mejor interpretabilidad sin comprometer la precisión. | |||
| 2019-08-01 | ¿Qué mira Bert? Un análisis de la atención de Bert | ||
| • El documento introduce métodos para analizar los mecanismos de atención de Bert, revelando patrones que se alinean con estructuras lingüísticas como la sintaxis y la coreferencia. • Análisis de cabezas de atención, identificación de patrones sintácticos y coreferenciales, y el desarrollo de un clasificador de sondeo basado en la atención. • Los cabezales de atención de Bert capturan información sintáctica sustancial, particularmente en tareas como identificar objetos directos y coreferencia. | |||
| 2019-07-01 | Análisis de autoatención múltiple: las cabezas especializadas hacen el trabajo pesado, el resto se puede podar | ||
| • El documento introduce un nuevo método de poda para la autoatención de múltiples cabezas que elimina selectivamente cabezas menos importantes sin una gran pérdida de rendimiento. • Análisis de cabezas de atención individuales, identificación de sus roles especializados y la aplicación de un método de poda en el modelo de transformador. • La poda 38 de 48 cabezas en el codificador condujo a solo una caída de puntaje de 0.15 BLEU. | |||
| 2018-11-01 | Un análisis de representaciones de codificadores en la traducción automática basada en transformadores | ||
| • Este documento analiza las representaciones internas de las capas del codificador del transformador, centrándose en la información sintáctica y semántica aprendida por los jefes de autoatición. • Tareas de sondeo, extracción de relaciones de dependencia y un escenario de aprendizaje de transferencia. • Las capas inferiores capturan la sintaxis, mientras que las capas más altas codifican más información semántica. | |||
| 2016-03-21 | Incorporando el mecanismo de copia en el aprendizaje de secuencia a secuencia | ||
| • Introduce un mecanismo de copia en modelos de secuencia a secuencia para permitir la copia directa de los tokens de entrada, mejorando el manejo de palabras raras. • Aplicado a las tareas de traducción y resumen de la máquina. • logró mejoras sustanciales en la precisión de la traducción, especialmente en la traducción de palabras raras, en comparación con los modelos de secuencia a secuencia estándar. | |||
Plantilla de emisión:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


