AMRICA
1.0.0
AMRICA (AMR Inspector for Cross-language Alignments) es una herramienta sencilla para alinear y representar visualmente los AMR (Banarescu, 2013), tanto para contextos bilingües como para acuerdos monolingües entre anotadores. Se basa en el sistema Smatch (Cai, 2012) y lo amplía para identificar el acuerdo entre anotadores de AMR.
También es posible utilizar AMRICA para visualizar alineaciones manuales que haya editado o compilado usted mismo (consulte Banderas comunes).
Descargue la fuente de Python desde github.
Suponemos que tienes pip . Para instalar las dependencias (suponiendo que ya tenga las dependencias de Graphviz que se mencionan a continuación), simplemente ejecute:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz requiere que Graphviz funcione. En Linux, es posible que tengas que instalar graphviz libgraphviz-dev pkg-config . Además, para preparar datos de alineación bilingües necesitará GIZA++ y posiblemente JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
Este comando leerá los AMR en sample.amr (separados por líneas vacías) y colocará sus visualizaciones de Graphviz en archivos .png ubicados en sample_out_dir/ .
Para generar visualizaciones de alineaciones de Smatch, necesitamos un archivo de entrada AMR con cada campo ::tok o ::snt que contenga oraciones tokenizadas, campos ::id con un ID de oración y campos ::annotator o ::anno con un ID de anotador. Las anotaciones para una oración particular se enumeran secuencialmente y la primera anotación se considera el estándar de oro para fines de visualización.
Si solo desea visualizar la anotación única por oración sin acuerdo entre anotadores, puede usar un archivo AMR con un solo anotador. En este caso, los campos de anotador e ID de oración son opcionales. El gráfico resultante será todo negro.
Para alineaciones bilingües, comenzamos con dos archivos AMR, uno que contiene las anotaciones de destino y otro con las anotaciones de origen en el mismo orden, con los campos ::tok y ::id para cada anotación. Si queremos alineaciones JAMR para cualquier lado, las incluimos en un campo ::alignments .
Las alineaciones de oraciones deben tener la forma de dos archivos .NBEST de alineación GIZA++, uno de origen-destino y otro de destino-fuente. Para generarlos, use el indicador --nbestalignments en su archivo de configuración de GIZA++ configurado en su recuento nbest preferido.
Las banderas se pueden configurar en la línea de comando o en un archivo de configuración. La ubicación de un archivo de configuración se puede configurar con -c CONF_FILE en la línea de comando.
Además de --conf_file , hay varias otras opciones que se aplican tanto al texto monolingüe como al bilingüe. --outdir DIR es el único requerido y especifica el directorio en el que escribiremos los archivos de imagen.
Las banderas compartidas opcionales son:
--verbose para imprimir oraciones a medida que las alineamos.--no-verbose para anular una configuración predeterminada detallada.--json FILE.json para escribir los gráficos de alineación en un archivo .json.--num_restarts N para especificar el número de reinicios aleatorios que debe ejecutar Smatch.--align_out FILE.csv para escribir las alineaciones en el archivo.--align_in FILE.csv para leer las alineaciones del disco en lugar de ejecutar Smatch.--layout para modificar el parámetro de diseño a Graphviz.Los archivos .csv de alineación tienen un formato en el que cada conjunto de coincidencia de gráficos está separado por una línea vacía y cada línea dentro de un conjunto contiene un comentario o una línea que indica una alineación. Por ejemplo:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
Los campos separados por tabulaciones son el índice del nodo de prueba (procesado por Smatch), la etiqueta del nodo de prueba, el índice del nodo dorado y la etiqueta del nodo dorado.
La alineación monolingüe requiere un indicador adicional, --infile FILE.amr , con FILE.amr configurado en la ubicación del archivo AMR.
A continuación se muestra un archivo de configuración de ejemplo:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
En la alineación bilingüe, se requieren más banderas.
--src_amr FILE para el archivo AMR de anotación de origen.--tgt_amr FILE para el archivo AMR de anotación de destino.--align_tgt2src FILE.A3.NBEST para el archivo GIZA++ .NBEST que alinea el destino con el origen (con el destino como vcb1), generado con --nbestalignments N--align_src2tgt FILE.A3.NBEST para el archivo GIZA++ .NBEST que alinea el origen con el destino (con el origen como vcb1), generado con --nbestalignments N Ahora, si --nbestalignments N se configuró en >1, deberíamos especificarlo con --num_aligned_in_file . Si queremos contar sólo la parte superior --num_align_read .
--nbestalignments es un indicador complicado de usar, porque solo se generará en una ejecución de alineación final. Yo solo pude hacerlo funcionar con la configuración predeterminada de GIZA++.
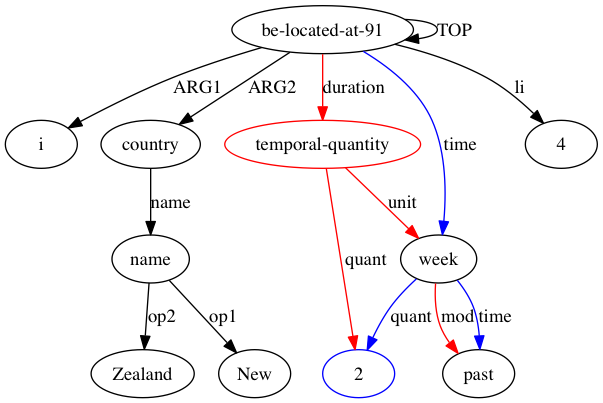
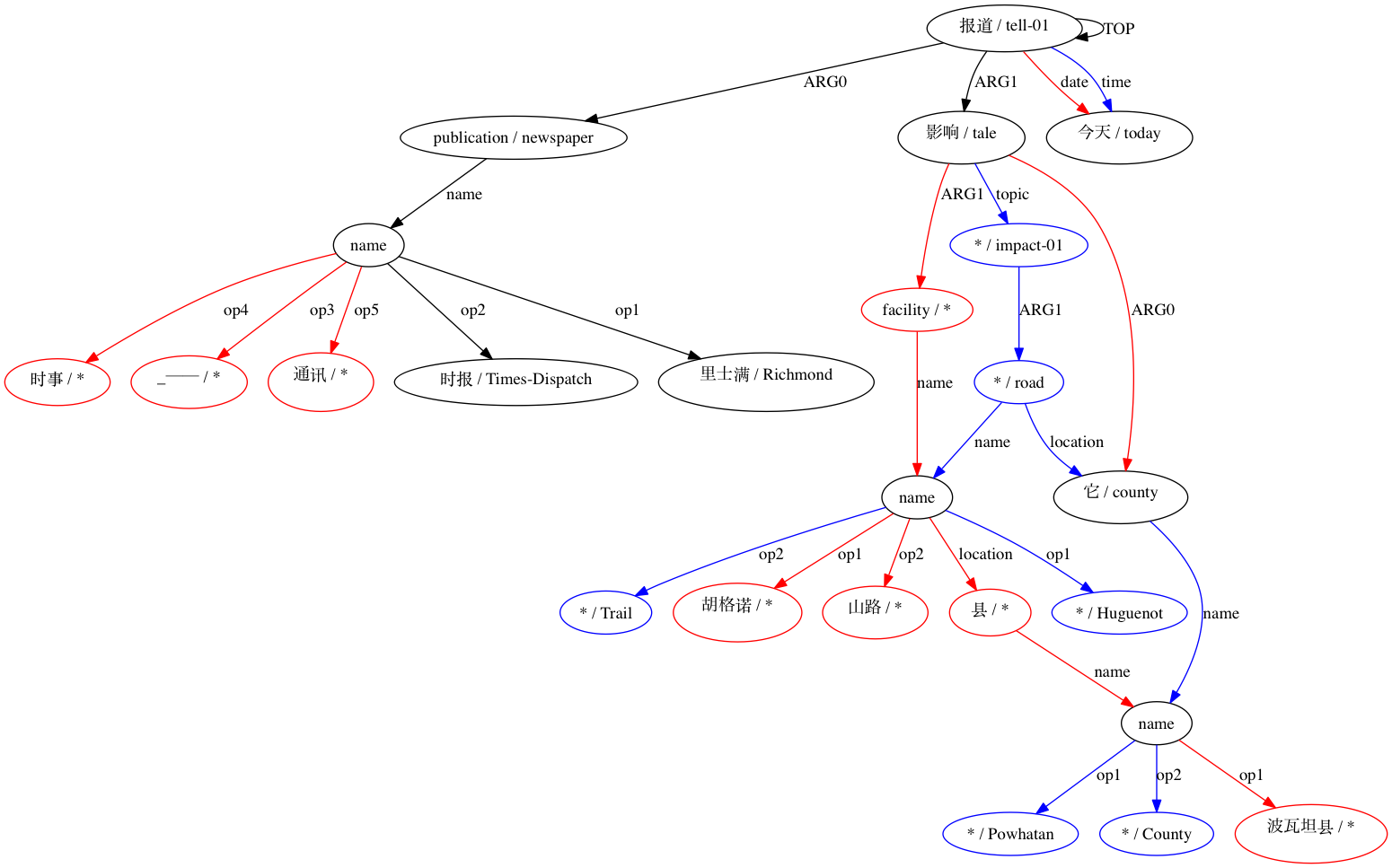
Dado que AMRICA es una variación de Smatch, uno debería comenzar por comprender Smatch. Smatch intenta identificar una coincidencia entre los nodos variables de dos representaciones AMR de la misma oración para medir el acuerdo entre anotadores. La coincidencia debe seleccionarse para maximizar la puntuación Smatch, que asigna un punto por cada borde que aparece en ambos gráficos, clasificándose en tres categorías. Cada categoría se ilustra en la siguiente anotación de "No tomó mucho tiempo".
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)Debido a que el problema de encontrar la coincidencia que maximiza la puntuación de Smatch es NP-completo, Smatch utiliza un algoritmo de escalada para aproximar la mejor solución. Se inicia haciendo coincidir cada nodo con un nodo que comparte su etiqueta, si es posible, y haciendo coincidir los nodos restantes en el gráfico más pequeño (en adelante, el objetivo) de forma aleatoria. Luego, Smatch realiza un paso al encontrar la acción que aumentará la puntuación al máximo, ya sea cambiando las coincidencias de dos nodos de destino o moviendo una coincidencia de su nodo de origen a un nodo de origen no coincidente. Se repite este paso hasta que ningún paso pueda aumentar inmediatamente la puntuación de Smatch.
Para evitar óptimos locales, Smatch generalmente se reinicia 5 veces.
Para obtener detalles técnicos sobre el funcionamiento interno de AMRICA, puede resultar más útil leer nuestro documento de demostración NAACL.
AMRICA comienza reemplazando todos los nodos constantes con nodos variables que son instancias de la etiqueta de la constante. Esto es necesario para que podamos alinear los nodos constantes y las variables. Por lo tanto, los únicos puntos agregados a la puntuación AMRICA provendrán de hacer coincidir los bordes de variable-variable y las etiquetas de instancia.
Mientras que Smatch intenta hacer coincidir cada nodo del gráfico más pequeño con algún nodo del gráfico más grande, AMRICA elimina las coincidencias que no aumentan la puntuación de Smatch modificada o puntuación AMRICA.
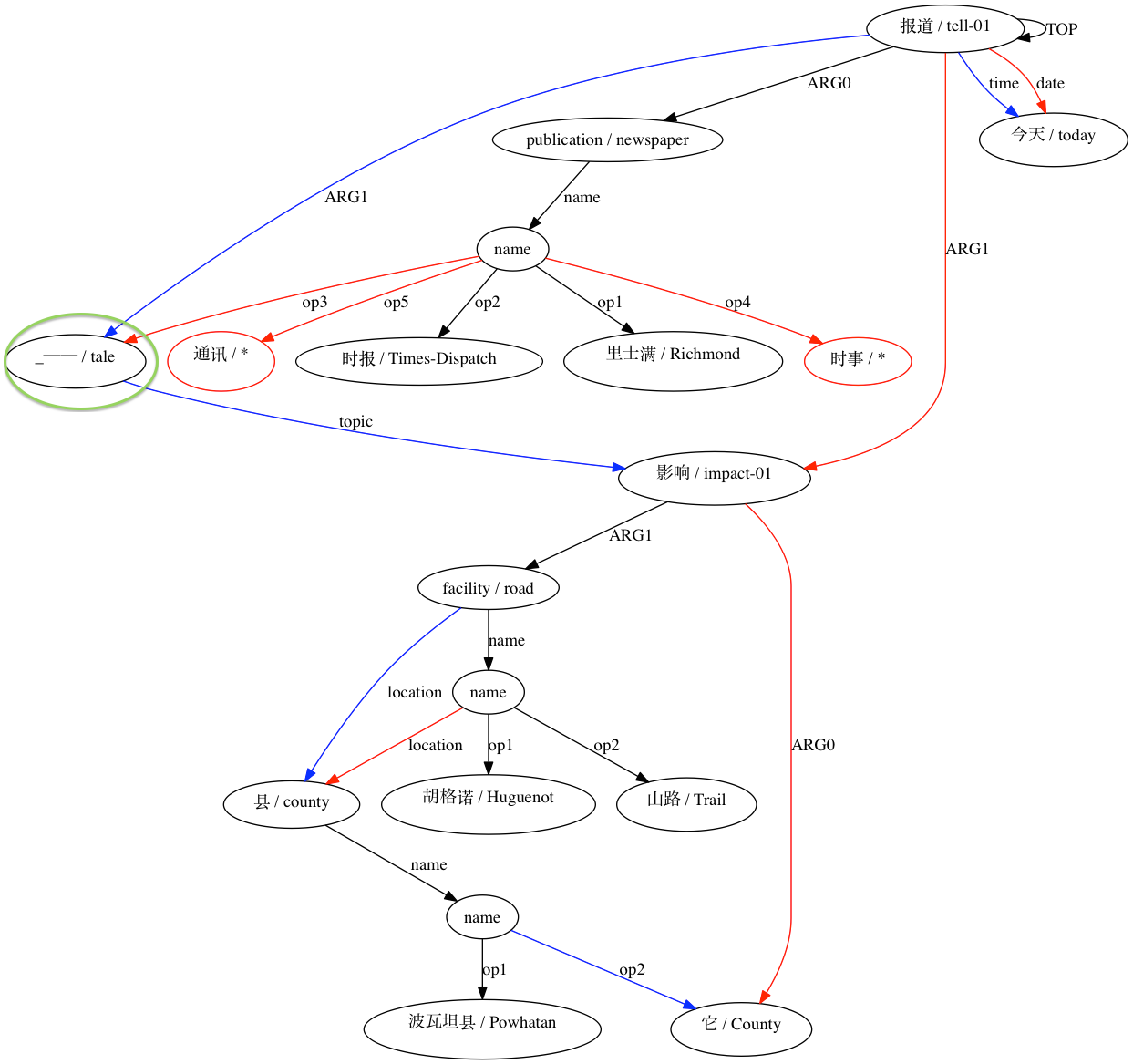
AMRICA luego genera archivos de imágenes a partir de gráficos Graphviz de las alineaciones. Si un nodo o borde aparece solo en los datos dorados, es rojo. Si ese nodo o borde aparece solo en los datos de prueba, es azul. Si el nodo o borde coincide en nuestra alineación final, es negro.
En AMRICA, en lugar de agregar un punto por cada etiqueta de instancia que coincida perfectamente, agregamos un punto basado en una puntuación de probabilidad de que esas etiquetas se alineen. La puntuación de probabilidad ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) con el conjunto de etiquetas de destino Lt, el conjunto de etiquetas de origen Ls, la oración de destino Wt, la oración de origen Ws y la alineación aLt,Ls[i] mapeo Lt[ i] en alguna etiqueta Ls[aLt,Ls[i]], se calcula a partir de una probabilidad definida por las siguientes reglas:
En general, AMRICA bilingüe parece requerir más reinicios aleatorios que AMRICA monolingüe para funcionar bien. Este recuento de reinicios se puede modificar con la bandera --num_restarts .
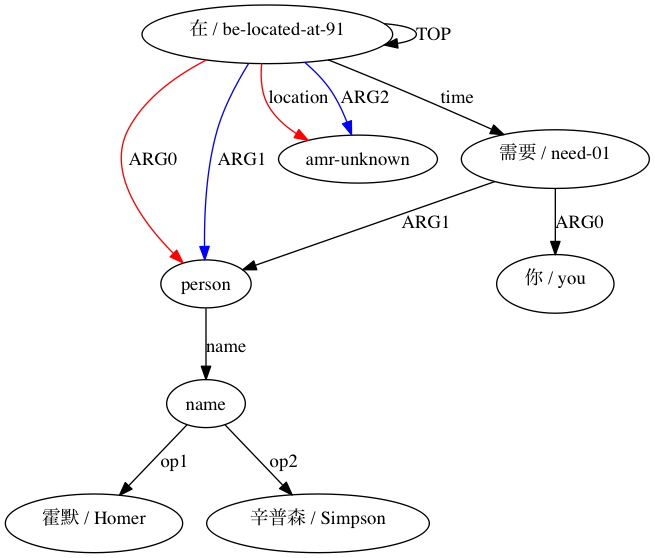
Podemos observar el grado en que el uso de aproximaciones tipo Smatch (aquí, con 20 inicializaciones aleatorias) mejora la precisión con respecto a la selección de posibles coincidencias a partir de datos de alineación sin procesar (inicialización inteligente). Para un binomio declarado estructuralmente compatible por (Xue 2014).
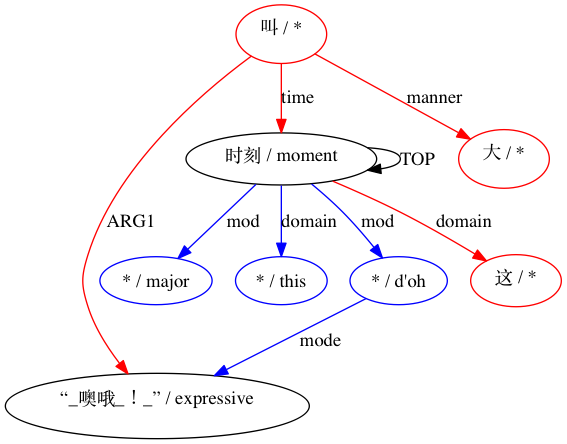
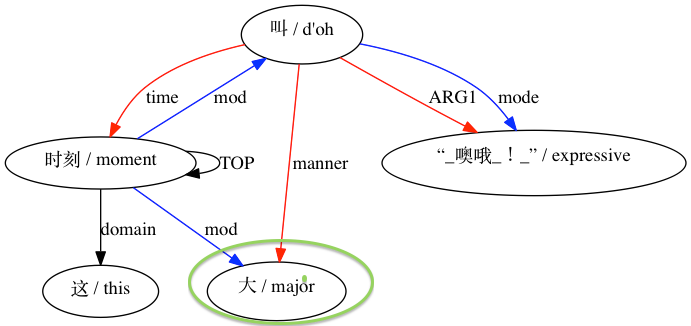
Para un emparejamiento considerado incompatible:
Este software se desarrolló en parte con el apoyo de la Fundación Nacional de Ciencias (EE. UU.) bajo los premios 1349902 y 0530118. La Universidad de Edimburgo es una organización benéfica, registrada en Escocia, con el número de registro SC005336.


