llmjudge
1.0.0
Evaluar los LLM en un escenario abierto es difícil, existe un consenso cada vez mayor de que faltan puntos de referencia existentes y los profesionales experimentados prefieren verificar los modelos ellos mismos. He recurrido a valoraciones anecdóticas de desarrolladores e investigadores de mi confianza, siendo Chatbot Arena un excelente complemento. La motivación detrás de este repositorio es el método cada vez más popular de utilizar LLM sólidos como jueces de modelos. Este método existe desde hace unos meses, con modelos como JudgeLM y, más recientemente, MT-Bench.
Puede que hayas visto o no este hilo. Según los autores del tweet de Arize AI, el uso de LLM como juez justifica la precaución del servidor, específicamente en lo que respecta al uso de evaluaciones de puntuación numéricas. Parece que los LLM son muy pobres en el manejo de rangos continuos, lo que se vuelve evidente cuando se les pide que evalúen X del 1 al 10. Este repositorio es un documento vivo de experimentos que intentan comprender y capturar la frontera irregular de este problema. Un trabajo reciente ha establecido una fuerte correlación entre MT-Bench y Human Judgment (Arena Elo) , lo que significa que los LLM son capaces de ser jueces, entonces, ¿qué está pasando aquí?
A continuación se muestran todos los detalles y resultados.
Debido a limitaciones de costos, inicialmente me centraré en la tarea de ortografía/errores de ortografía descrita en los tweets. Me preocupa un poco que la X cuantitativa de esta tarea contamine los conocimientos de este experimento, pero ya veremos. Doy la bienvenida a un análisis más completo de este fenómeno; mis resultados deben tomarse con cautela dada la limitación del experimento.
He generado un conjunto de datos de ortografía o errores ortográficos, sin estar seguro de qué nombre es más apropiado, a partir de los ensayos de Paul Graham. Esta elección fue principalmente por conveniencia, ya que he usado el conjunto de datos antes al probar las ventanas de contexto. Extraje un contexto de 3000 palabras de los ensayos e inserté errores ortográficos en palabras aleatorias según la proporción de errores ortográficos deseada. En pseudocódigo:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
El código completo está disponible como un cuaderno.
Dado el conjunto de datos generado, solicitamos a los LLM que evalúen la cantidad de palabras mal escritas en un contexto utilizando diferentes plantillas de puntuación. Estamos utilizando las siguientes API
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
a temperatura = 0.
Prueba 1. Confirmemos que los LLM tienen dificultades para manejar rangos numéricos en una configuración de tiro cero. Solicitamos a GPT-3.5 y GPT-4 una plantilla de puntuación numérica, que va desde la puntuación 0 hasta la puntuación 10.
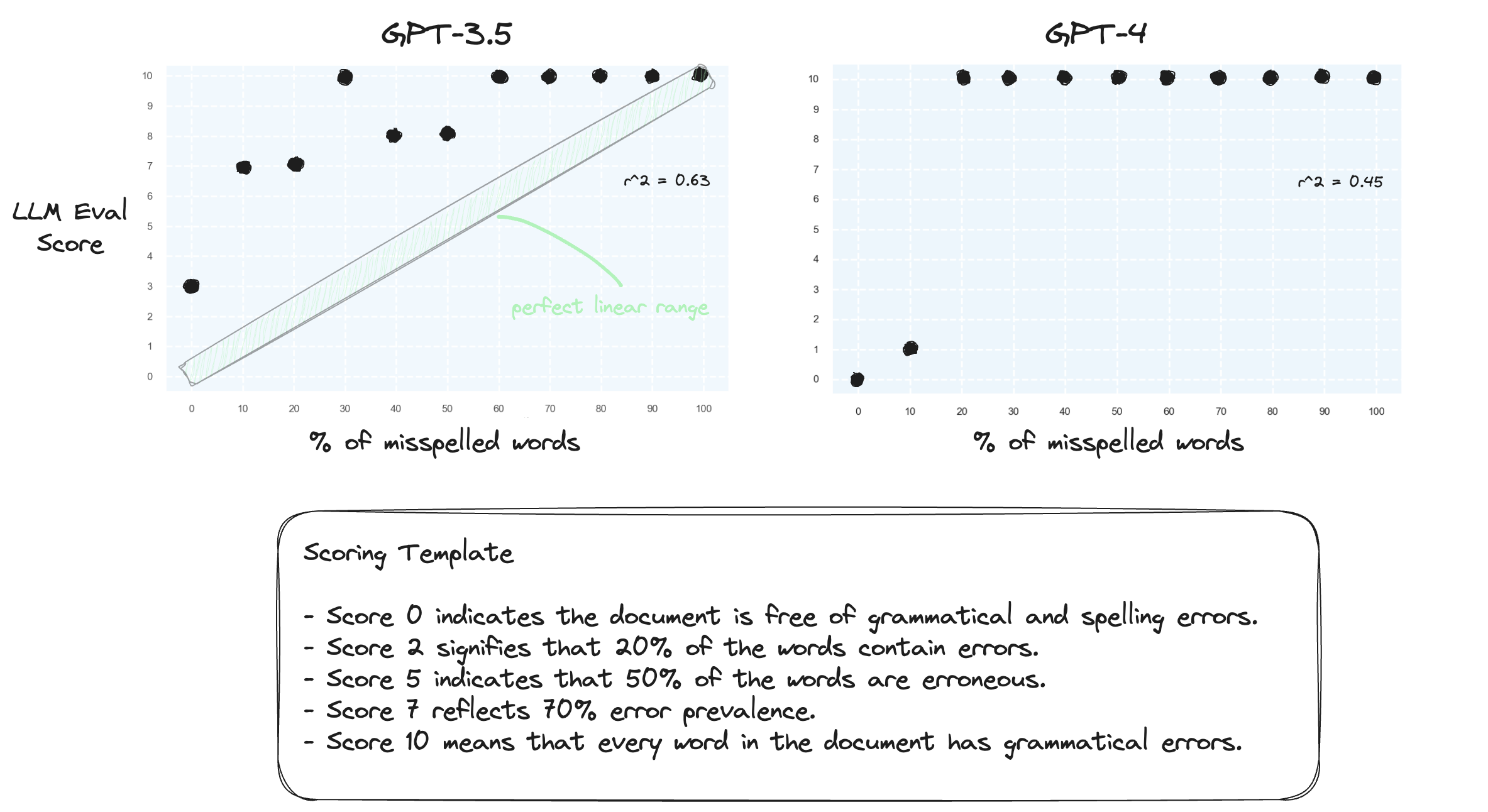
Como era de esperar, ambos juzgan gravemente mal.
Prueba 2. ¿Qué pasa si invertimos el rango de puntuación? Ahora bien, una puntuación de 10 representa un documento perfectamente escrito.
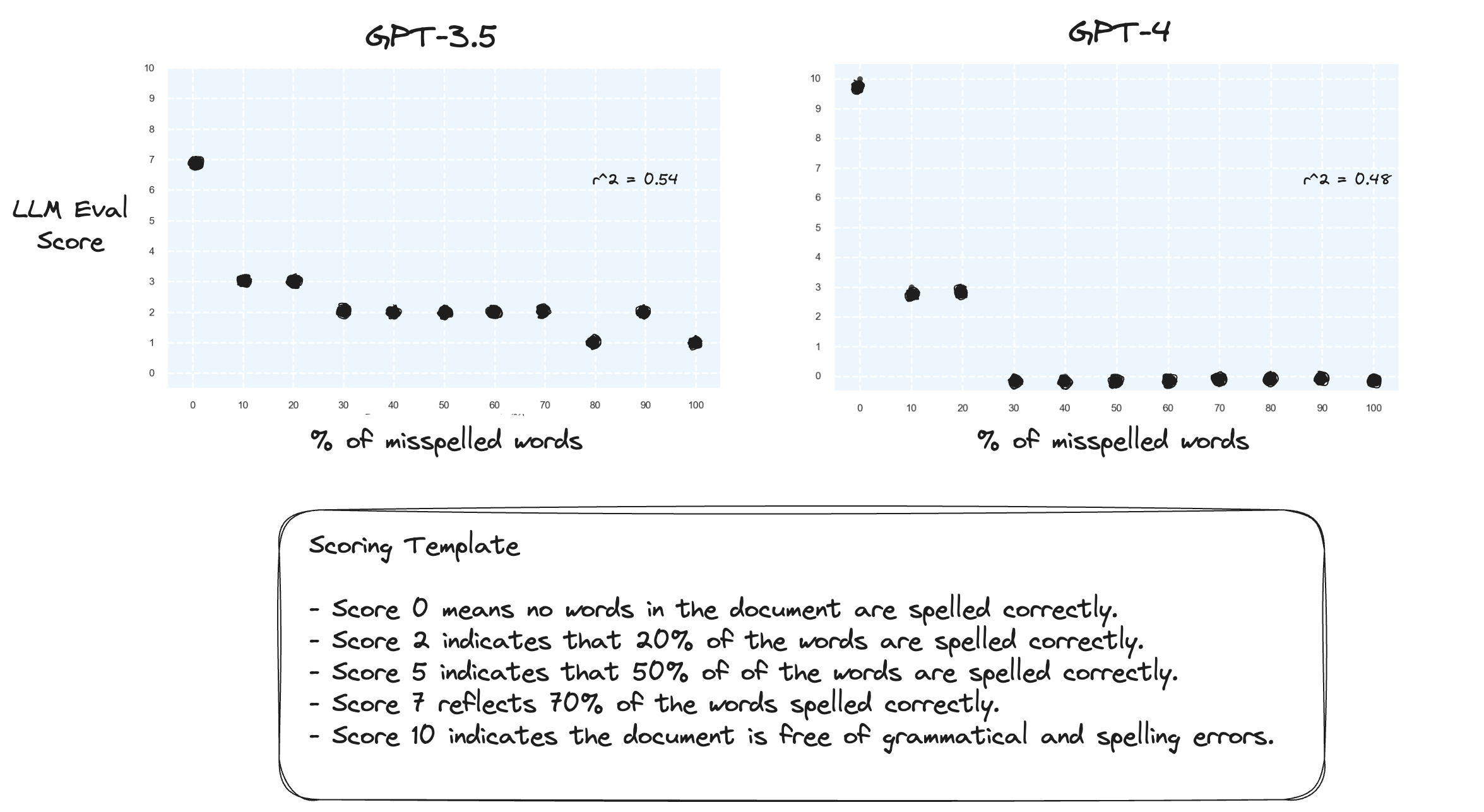
Esto no parece hacer mucha diferencia.
Prueba 3. Si creyéramos en la hipótesis de Arize, podríamos ver mejoras si evitamos una rúbrica de puntuación y en su lugar utilizamos 'calificaciones etiquetadas'. En este caso decidí bajar a una escala de calificación de 5 puntos.
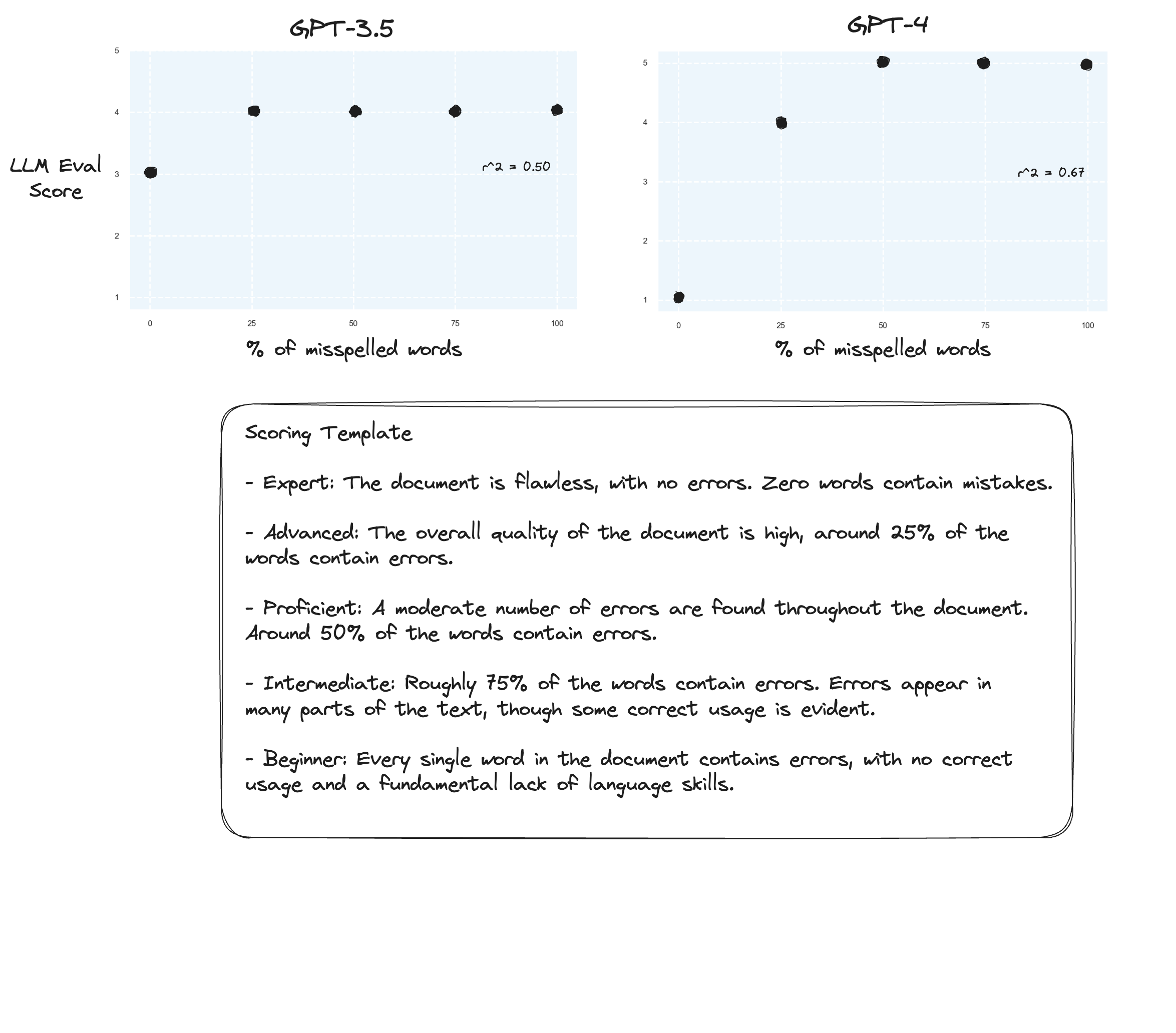
¿Quizás ligeras mejoras? Es difícil decirlo honestamente. No estoy impresionado.
Prueba 4. ¿Qué pasa con la cadena de pensamiento de disparo cero?

gpt-3.5 se convirtió en un galimatías en dos de las indicaciones. Como era de esperar, gpt-4 ve una mejora cuando se le pide que piense en voz alta. Observe cómo se vuelve muy reacio a asignar una puntuación de 10.
Prueba 5. Según lo sugerido por el autor de Prometeo; asignar cada puntaje con su propia explicación probablemente mejore la capacidad del LLM para calificar en todo el rango numérico. Esto, combinado con CoT, da como resultado:

Mejoras continuas para gpt-4. Todavía es muy reacio a asignar puntuaciones de límites 0 y 10.
Prueba 6. Después de leer más sobre MT Bench, decidí probar un enfoque alternativo, utilizando comparaciones por pares en lugar de puntuaciones aisladas. Ahora, normalmente esto requeriría comparaciones O(n * log N), pero como ya conocemos el orden, pensé que simplemente probaríamos los casos más difíciles: comparar 0% de errores ortográficos con 10% de errores ortográficos, 10% con 20%, etc. para un total de 10 comparaciones. Tenga en cuenta que también utilicé CoT de disparo cero.
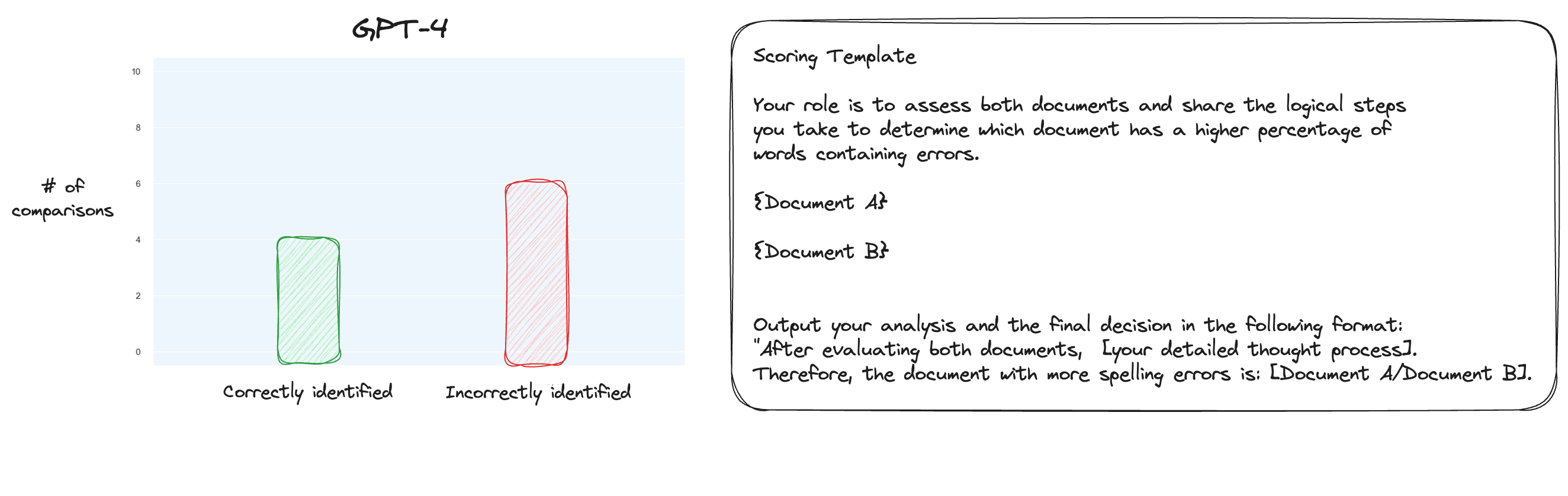
Mi hipótesis era que GPT-4 habría sobresalido en un escenario en el que pudiera comparar dos textos dentro de su ventana contextual, pero estaba equivocado. Para mi sorpresa, esto realmente no mejoró las cosas en absoluto. Claro, esta es la comparación más difícil de todas las posibles, pero en general sigue siendo una tarea sencilla. Quizás los aspectos cuantitativos de esta tarea sean inherentemente muy difíciles para los LLM. Hmm, tal vez necesito encontrar una mejor tarea de proxy...
(31/1) He estado revisando los aspectos internos de MT-Bench y me sorprendió mucho descubrir que simplemente le piden a GPT-4 que califique los resultados en una escala del 1 al 10. Proporcionan opciones de calificación alternativas, como comparaciones por pares con una línea de base, pero la opción recomendada es la numérica. El mensaje de juicio también es inesperadamente simple:
Actúe como juez imparcial y evalúe la calidad de la respuesta proporcionada por un asistente de IA a la pregunta del usuario que se muestra a continuación. Su evaluación debe considerar factores como la utilidad, relevancia, precisión, profundidad, creatividad y nivel de detalle de la respuesta. Comience su evaluación brindando una breve explicación. Sea lo más objetivo posible. Luego de brindar tu explicación, deberás calificar la respuesta en una escala del 1 al 10 siguiendo estrictamente este formato: [calificación], por ejemplo: "Calificación: 5". [Pregunta] {pregunta} [El comienzo de la respuesta del Asistente] {respuesta} [El final de la respuesta del Asistente]
Si uno cree que esto es todo lo que hay que hacer para juzgar en MT-Bench, entonces estoy empezando a cuestionar el uso de la tarea de errores ortográficos como tarea proxy...
(2/2) Me interesa que GPT-4 juzgue los textos mal escritos mediante una comparación por pares en lugar de una puntuación aislada. Este es uno de los métodos de evaluación alternativos para MT Bench (aunque recomiendan puntuación aislada) y sospecho que es más adecuado para esta tarea. Los resultados del mapeo completo de CoT + son definitivamente una mejora, pero sigo pensando que queda trabajo por hacer. El inconveniente de la puntuación por pares es, por supuesto, que necesitará muchas más llamadas API para establecer la clasificación completa (en la práctica).


