DreamerGPT
1.0.0
 DreamerGPT: ajuste fino de las instrucciones del modelo en idioma chino
DreamerGPT: ajuste fino de las instrucciones del modelo en idioma chinoDreamerGPT es un proyecto de ajuste fino de instrucción de modelos de lenguaje grande chino iniciado por Xu Hao, Chi Huixuan, Bei Yuanchen y Liu Danyang.
Leer en versión inglesa .

 1. Introducción del proyecto
1. Introducción del proyectoEl objetivo de este proyecto es promover la aplicación de modelos de lenguaje grande chino en escenarios de campo más verticales.
Nuestro objetivo es hacer los modelos grandes más pequeños y ayudar a todos a formar y tener un asistente experto personalizado en su propio campo vertical. Puede ser un consejero psicológico, un asistente de código, un asistente personal o es su propio tutor de idiomas, lo que significa que. DreamerGPT es un modelo de idioma que tiene los mejores resultados posibles, el menor costo de capacitación y está más optimizado para el chino. El proyecto DreamerGPT continuará abriendo el entrenamiento de inicio en caliente del modelo de lenguaje iterativo (incluidos LLaMa, BLOOM), entrenamiento de comandos, aprendizaje de refuerzo, ajuste de campo vertical y continuará iterando datos de entrenamiento confiables y objetivos de evaluación. Debido al personal y los recursos limitados del proyecto, la versión V0.1 actual está optimizada para LLaMa chino para LLaMa-7B y LLaMa-13B, agregando características chinas, alineación de idiomas y otras capacidades. Actualmente, todavía existen deficiencias en las capacidades de diálogo largo y razonamiento lógico. Consulte la próxima versión de la actualización para conocer más planes de iteración.
La siguiente es una demostración de cuantificación basada en 8b (el video no está acelerado). Actualmente, también se están iterando la aceleración de inferencia y la optimización del rendimiento:
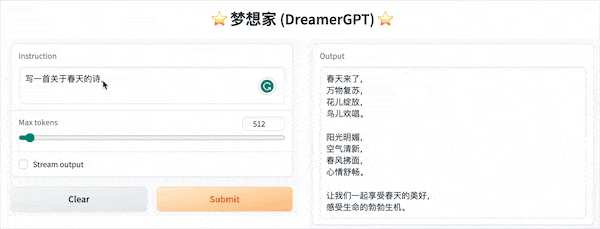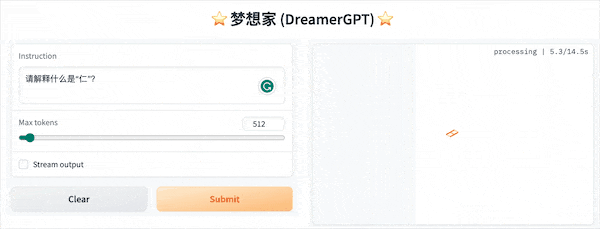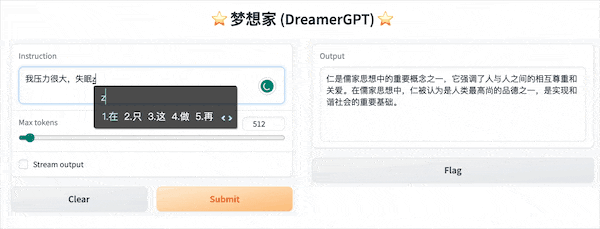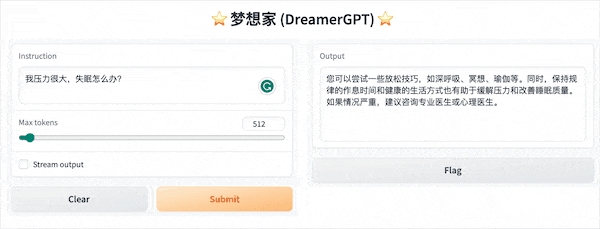
Más pantallas de demostración:
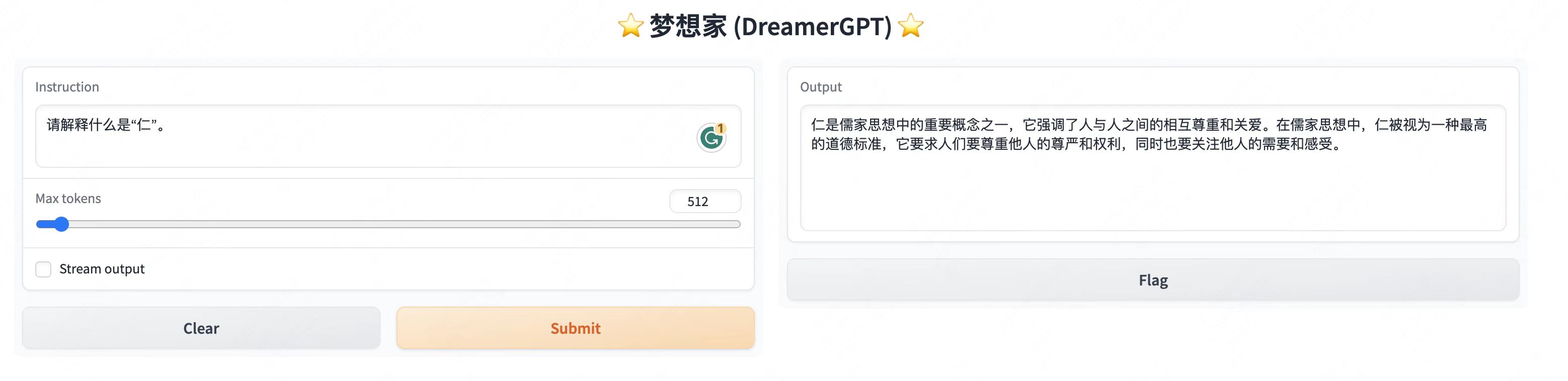

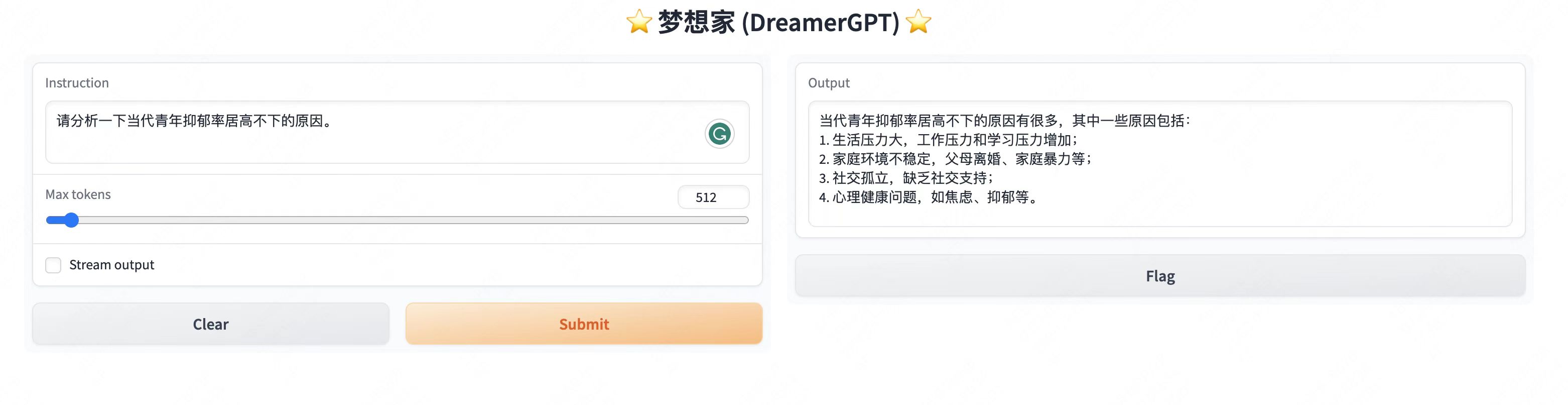
 2. Última actualización
2. Última actualización  [17/06/2023] Actualización de la versión V0.2: versión de entrenamiento incremental de LLaMa firefly, versión BLOOM-LoRA (
[17/06/2023] Actualización de la versión V0.2: versión de entrenamiento incremental de LLaMa firefly, versión BLOOM-LoRA ( finetune_bloom.py , generate_bloom.py ).
[23/04/2023] Comando chino de código abierto oficialmente que ajusta el modelo grande Dreamer (DreamerGPT) , que actualmente proporciona la experiencia de descarga de la versión V0.1
Modelos existentes (entrenamiento incremental continuo, más modelos por actualizar):
| Nombre del modelo | datos de entrenamiento = | Descarga de peso |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + tren-luciérnaga-1 | [Cara abrazada] |
| D7b-5-1 | D7b-4-1 + tren-luciérnaga-1 | [Cara abrazada] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chino-alpaca-lora-13b-hot start + COIG-parte1, COIG-traducir + PsyQA-5 | [Google Drive] [Cara de abrazo] |
| D13b-2-2-2 | Chino-alpaca-lora-13b-arranque en caliente + firefly-train-0 + COIG-parte1, COIG-traducir | [Google Drive] [Cara de abrazo] |
| D13b-2-3 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [Cara de abrazo] |
| D7b-4-1 | Alpaca-china-lora-7b-hotstart+tren-luciérnaga-0 | [Google Drive] [Cara de abrazo] |
Vista previa de la evaluación del modelo.
 3. Preparación de modelos y datos.
3. Preparación de modelos y datos.Descarga del peso del modelo:
Los datos se procesan uniformemente en el siguiente formato json:
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Script de descarga y preprocesamiento de datos:
| datos | tipo |
|---|---|
| Alpaca-GPT4 | Inglés |
| Firefly (preprocesado en múltiples copias, alineación de formato) | Chino |
| COIG | Chino, código, chino e inglés. |
| PsyQA (preprocesado en múltiples copias, formato alineado) | Asesoramiento psicológico chino. |
| BELDAD | Chino |
| bayeta | conversación china |
| Coplas (preprocesadas en múltiples copias, formato alineado) | Chino |
Nota: Los datos provienen de la comunidad de código abierto y se puede acceder a ellos a través de enlaces.
 4. Códigos y guiones de formación
4. Códigos y guiones de formaciónIntroducción al código y al script:
finetune.py : Instrucciones para ajustar el código de inicio en caliente/entrenamiento incrementalgenerate.py : código de inferencia/pruebascripts/ : ejecutar scriptsscripts/rerun-2-alpaca-13b-2.sh , consulte scripts/README.md para obtener una explicación de cada parámetro.  5. Cómo utilizar
5. Cómo utilizarConsulte Alpaca-LoRA para obtener detalles y preguntas relacionadas.
pip install -r requirements.txtFusión de peso (tomando como ejemplo alpaca-lora-13b):
cd scripts/
bash merge-13b-alpaca.shSignificado del parámetro (modifique usted mismo la ruta relevante):
--base_model , llama peso original--lora_model , peso de llama china/alpaca-lora--output_dir , ruta para generar pesos de fusiónTome el siguiente proceso de capacitación como ejemplo para mostrar el script en ejecución.
| comenzar | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaca-lora-13b-hot start, número de experimento: 2 | Datos: firefly-train-0 | Datos: COIG-parte1, COIG-traducir | Datos: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shExplicación de parámetros importantes (modifique usted mismo las rutas relevantes):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 Si el conjunto de datos en sí es relativamente pequeño, se puede reducir adecuadamente, como 500, 200Tenga en cuenta que si desea descargar directamente los pesos ajustados para la inferencia, puede ignorar 5.3 y pasar directamente a 5.4.
Por ejemplo, quiero evaluar los resultados del ajuste fino rerun-2-alpaca-13b-2.sh :
1. Interacción con la versión web:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Inferencia por lotes y guardar resultados:
cd scripts/
bash save-generate-2-alpaca-13b-2.shExplicación de parámetros importantes (modifique usted mismo las rutas relevantes):
--is_ui False : si es una versión web, el valor predeterminado es Verdadero--test_input_path 'xxx.json' : ruta de instrucción de entradatest.json en el directorio de peso LoRA correspondiente de forma predeterminada.  6. Informe de evaluación
6. Informe de evaluación Actualmente hay 8 tipos de tareas de prueba en las muestras de evaluación (ética numérica y diálogo Duolun para evaluar), cada categoría tiene 10 muestras y la versión cuantificada de 8 bits se califica de acuerdo con la interfaz que llama a GPT-4/GPT 3.5 ( La versión no cuantificada tiene una puntuación más alta), cada muestra se puntúa en un rango de 0 a 10. Consulte test_data/ para ver ejemplos de evaluación.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Nota: La puntuación es solo como referencia (en comparación con GPT 3.5). La puntuación de GPT 4 es más precisa e informativa.
| Tareas de prueba | Ejemplo detallado | Número de muestras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Puntuación total de cada ítem | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivialidades | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| traducir | 02traducir.json | 10 | 77* | 77* | 77* | 64 | 86 |
| generación de texto | 03generar.json | 10 | 56 | 65* | 55 | 61 | 91 |
| análisis de sentimiento | 04analizar.json | 10 | 91 | 91 | 91 | 88* | 88* |
| comprensión lectora | 05comprensión.json | 10 | 74* | 74* | 74* | 76,5 | 96,5 |
| caracteristicas chinas | 06chino.json | 10 | 69* | 69* | 69* | 43 | 86 |
| generación de código | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Ética, negativa a responder | 08alineación.json | 10 | 87* | 87* | 87* | 71 | 95,5 |
| razonamiento matemático | (a evaluar) | -- | -- | -- | -- | -- | -- |
| Múltiples rondas de diálogo | (a evaluar) | -- | -- | -- | -- | -- | -- |
| Tareas de prueba | Ejemplo detallado | Número de muestras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Puntuación total de cada ítem | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivialidades | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| traducir | 02traducir.json | 10 | 79 | 81 | 82 | 89* | 91 |
| generación de texto | 03generar.json | 10 | 65 | 73* | 63 | 71 | 92 |
| análisis de sentimiento | 04analizar.json | 10 | 88* | 91 | 88* | 85 | 71 |
| comprensión lectora | 05comprensión.json | 10 | 75 | 77 | 76 | 85* | 91 |
| caracteristicas chinas | 06chino.json | 10 | 82* | 83 | 82* | 40 | 68 |
| generación de código | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Ética, negativa a responder | 08alineación.json | 10 | 71* | 70 | 67 | 71* | 94 |
| razonamiento matemático | (a evaluar) | -- | -- | -- | -- | -- | -- |
| Múltiples rondas de diálogo | (a evaluar) | -- | -- | -- | -- | -- | -- |
En general, el modelo tiene un buen rendimiento en traducción , análisis de sentimientos , comprensión lectora , etc.
Dos personas calificaron manualmente y luego promediaron.
| Tareas de prueba | Ejemplo detallado | Número de muestras | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Puntuación total de cada ítem | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivialidades | 01qa.json | 10 | 83* | 82 | 82 | 69,75 | 96,25 |
| traducir | 02traducir.json | 10 | 76,5* | 76,5* | 76,5* | 62,5 | 84 |
| generación de texto | 03generar.json | 10 | 44 | 51,5* | 43 | 47 | 81,5 |
| análisis de sentimiento | 04analizar.json | 10 | 89* | 89* | 89* | 85,5 | 91 |
| comprensión lectora | 05comprensión.json | 10 | 69* | 69* | 69* | 75,75 | 96 |
| caracteristicas chinas | 06chino.json | 10 | 55* | 55* | 55* | 37,5 | 87,5 |
| generación de código | 07code.json | 10 | 61,5* | 61,5* | 61,5* | 57 | 88,5 |
| Ética, negativa a responder | 08alineación.json | 10 | 84* | 84* | 84* | 70 | 95,5 |
| ética numérica | (a evaluar) | -- | -- | -- | -- | -- | -- |
| Múltiples rondas de diálogo | (a evaluar) | -- | -- | -- | -- | -- | -- |
 7. Contenido de actualización de la próxima versión
7. Contenido de actualización de la próxima versiónLista de tareas pendientes:
 Limitaciones, restricciones de uso y exenciones de responsabilidad
Limitaciones, restricciones de uso y exenciones de responsabilidadEl modelo SFT entrenado en base a datos actuales y modelos básicos todavía tiene los siguientes problemas en términos de efectividad:
Las instrucciones objetivas pueden dar lugar a respuestas incorrectas que vayan en contra de los hechos.
Las instrucciones dañinas no pueden identificarse adecuadamente, lo que puede dar lugar a comentarios discriminatorios, dañinos y poco éticos.
Las capacidades del modelo aún deben mejorarse en algunos escenarios que involucran razonamiento, codificación, múltiples rondas de diálogo, etc.
Con base en las limitaciones del modelo anterior, requerimos que el contenido de este proyecto y los derivados posteriores generados por este proyecto solo puedan usarse con fines de investigación académica y no con fines comerciales o usos que causen daño a la sociedad. El desarrollador del proyecto no asume ningún daño, pérdida o responsabilidad legal causada por el uso de este proyecto (incluidos, entre otros, datos, modelos, códigos, etc.).
 Cita
CitaSi utiliza el código, los datos o los modelos de este proyecto, cite este proyecto.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Contáctenos
ContáctenosTodavía hay muchas deficiencias en este proyecto. Deje sus sugerencias y preguntas y haremos todo lo posible para mejorar este proyecto.
Correo electrónico: [email protected]


