datalens
1.0.0
Este es un experimento personal que utiliza LLM para clasificar datos laborales no estructurados según criterios definidos por el usuario. Las plataformas tradicionales de búsqueda de empleo se basan en sistemas de filtrado rígidos, pero muchos usuarios carecen de criterios tan concretos. Datalens le permite definir sus preferencias de una manera más natural y luego califica cada oferta de trabajo según su relevancia.
Algunos criterios pueden ser más importantes que otros, por lo que los "criterios obligatorios" tienen el doble peso que los normales.
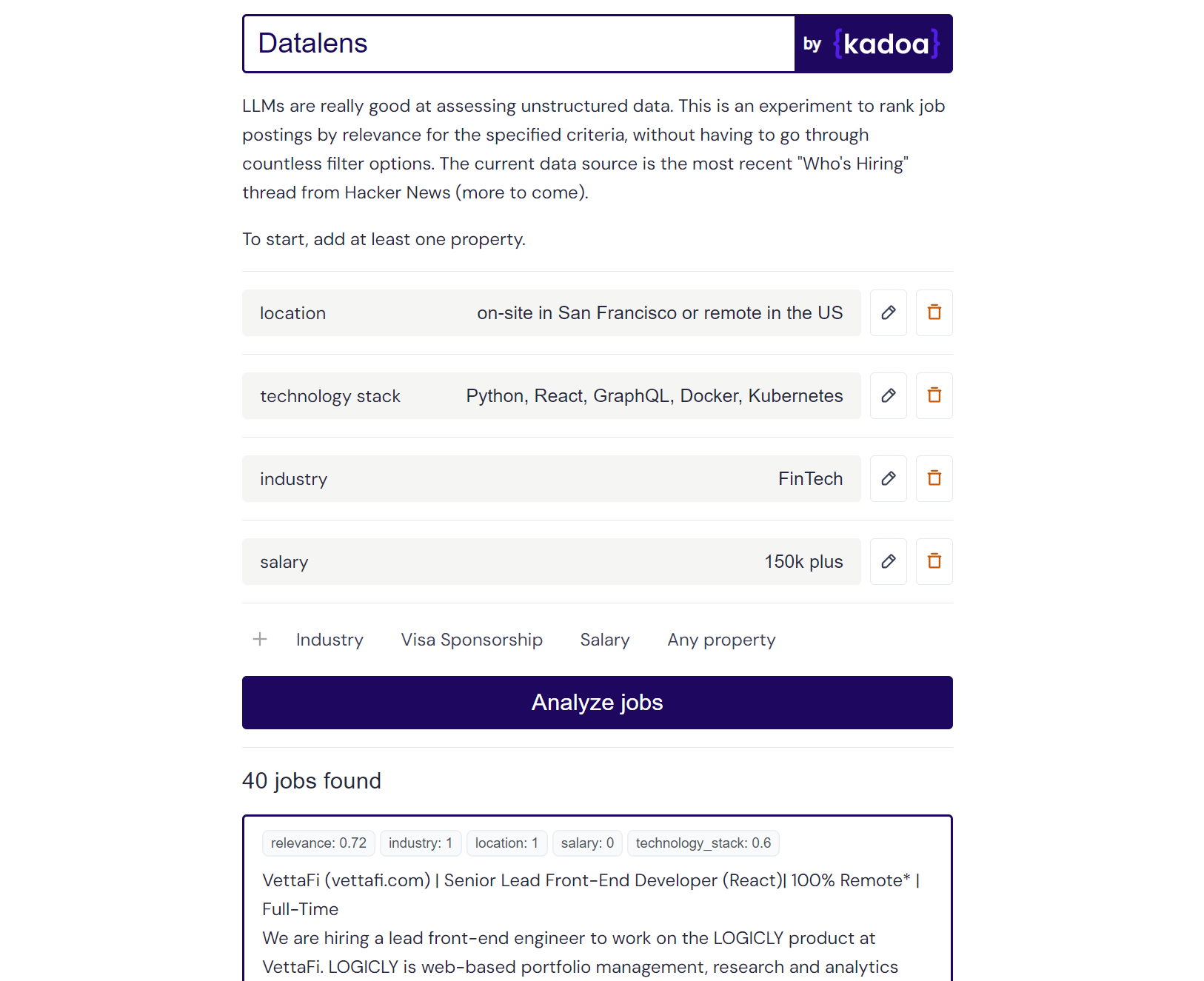
Resultado del ejemplo de Claude-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Puede agregar cualquier fuente de datos de trabajo que desee. Lo he preconfigurado con el hilo más reciente "Quién está contratando" de Hacker News, pero puedes agregar tus propias fuentes.
Agregue nuevas fuentes de trabajo actualizando sources_config.json. Ejemplo:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
He utilizado mi propia herramienta Kadoa para recuperar los datos del trabajo de las páginas de la empresa, pero puedes utilizar cualquier otro método de extracción tradicional.
A continuación se muestran algunos puntos finales públicos ya preparados para obtener todas las ofertas de trabajo de estas empresas (actualizadas diariamente):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Avíseme si debería agregar otras empresas. Además, me complace brindarle acceso de prueba a Kadoa.
La puntuación de relevancia funciona mejor con gpt-4-0613 , que devuelve puntuaciones granulares entre 0 y 1. claude-2 también funciona bastante bien si tienes acceso a él. Se puede utilizar gpt-3.5-turbo-0613 , pero a menudo devuelve puntuaciones binarias de 0 o 1 para los criterios, sin los matices necesarios para distinguir entre coincidencias parciales y completas.
El modelo predeterminado es gpt-3.5-turbo-0613 por motivos de coste. Puedes cambiar de GPT a Claude reemplazando use_claude con use_openai .
La ejecución continua de este script puede generar un uso elevado de API, así que utilícelo de manera responsable. Estoy registrando el costo de cada llamada GPT.
Para ejecutar la aplicación, necesita:
Copie el archivo .env.example y complételo.
Ejecute el servidor Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Navegue hasta el directorio del cliente e instale las dependencias del nodo:
cd client
npm install
Ejecute el cliente Next.js:
cd client
npm run dev


