ShapeGPT
1.0.0

Página del proyecto • Documento Arxiv • Demostración • Preguntas frecuentes • Cita
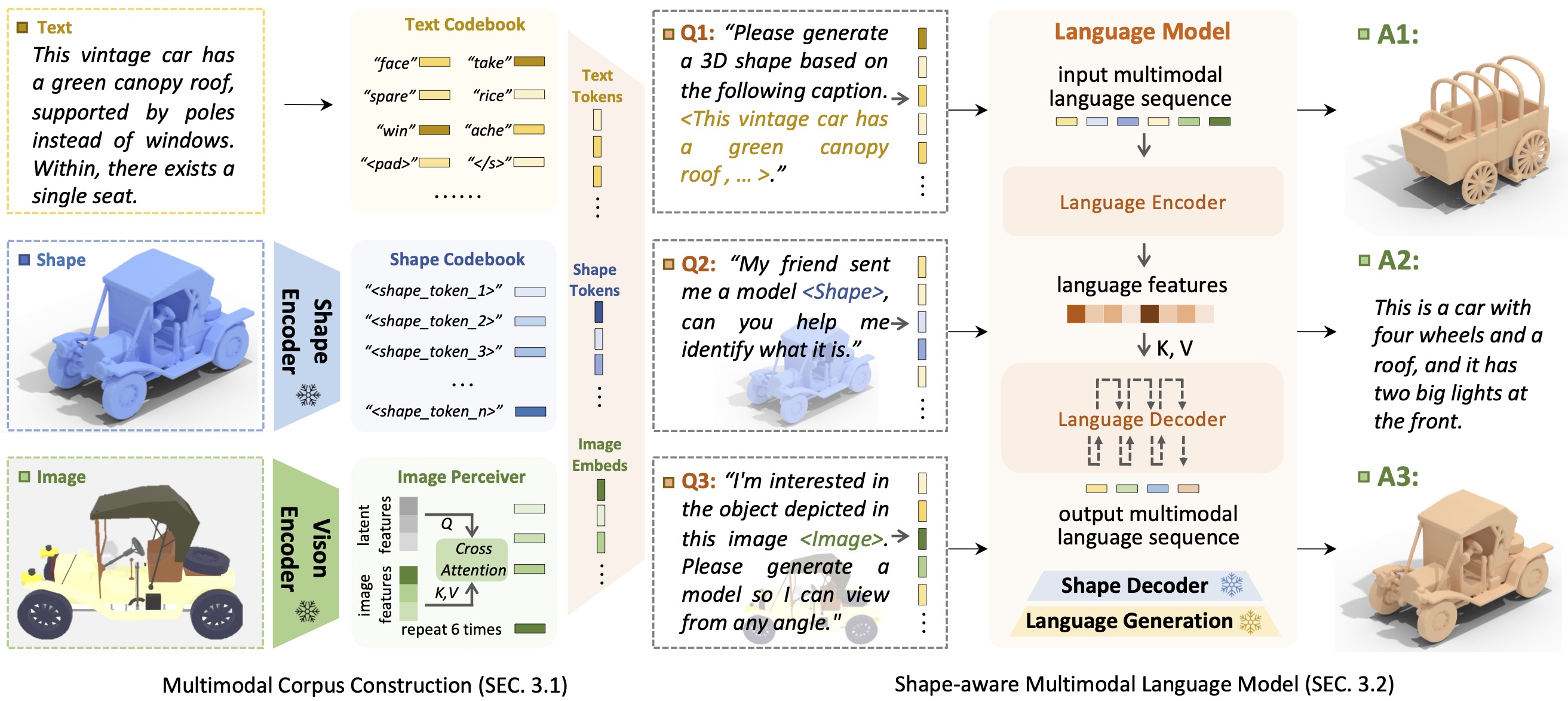
Introducción a ShapeGPTShapeGPT es un modelo de lenguaje multimodal centrado en formas unificado y fácil de usar para establecer un corpus multimodal y desarrollar modelos de lenguaje conscientes de formas en múltiples tareas de formas .
La llegada de grandes modelos de lenguaje, que permiten flexibilidad a través de enfoques basados en instrucciones, ha revolucionado muchas tareas generativas tradicionales, pero los modelos grandes para datos 3D, particularmente en el manejo integral de formas 3D con otras modalidades, aún están poco explorados. Al lograr generaciones de formas basadas en instrucciones, los modelos de formas generativas multimodales versátiles pueden beneficiar significativamente varios campos como la construcción virtual 3D y el diseño asistido por red. En este trabajo, presentamos ShapeGPT, un marco multimodal que incluye formas para aprovechar sólidos modelos de lenguaje previamente entrenados para abordar múltiples tareas relevantes para las formas. Específicamente, ShapeGPT emplea un marco de palabras, oraciones y párrafos para discretizar formas continuas en palabras con formas, ensambla aún más estas palabras para formar oraciones con formas y también integra la forma con el texto instructivo para párrafos multimodales. Para aprender este modelo de lenguaje de formas, utilizamos un esquema de entrenamiento de tres etapas, que incluye representación de formas, alineación multimodal y generación basada en instrucciones, para alinear los libros de códigos de lenguaje de formas y aprender las intrincadas correlaciones entre estas modalidades. Amplios experimentos demuestran que ShapeGPT logra un rendimiento comparable en tareas relevantes para formas, incluidas la conversión de texto a forma, de forma a texto, la finalización de formas y la edición de formas.
Si encuentra que nuestro código o nuestro documento le ayudan, considere citar:
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Gracias al modelo T5, Motion-GPT, Perceiver-IO y SDFusion, nuestro código toma prestado parcialmente de ellos. Nuestro enfoque está inspirado en Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox y 3DShape2VecSet.
Este código se distribuye bajo una LICENCIA MIT.
Tenga en cuenta que nuestro código depende de otras bibliotecas, incluidas PyTorch3D y PyTorch Lightning, y utiliza conjuntos de datos, cada uno de los cuales tiene sus propias licencias respectivas que también deben seguirse.


