Darwin
1.0.0
Organización: Universidad de Nueva Gales del Sur (UNSW) AI4Science & GreenDynamics AI
Darwin es un proyecto de código abierto dedicado a entrenar previamente y ajustar el modelo LLaMA en literatura científica y conjuntos de datos. Diseñado específicamente para el ámbito científico con énfasis en ciencia de materiales, química y física, Darwin integra conocimiento científico estructurado y no estructurado para mejorar la eficacia de los modelos de lenguaje en la investigación científica.
Avisos de uso y licencia : Darwin tiene licencia y está destinado únicamente para uso en investigación. El conjunto de datos tiene licencia CC BY NC 4.0, lo que permite su uso no comercial. Los modelos entrenados con este conjunto de datos no deben usarse fuera de fines de investigación. La diferencia de peso también está bajo licencia CC BY NC 4.0.
[2024.11.20]
Logros clave
Información sobre el rendimiento del modelo
Estrategias de datos y conocimientos
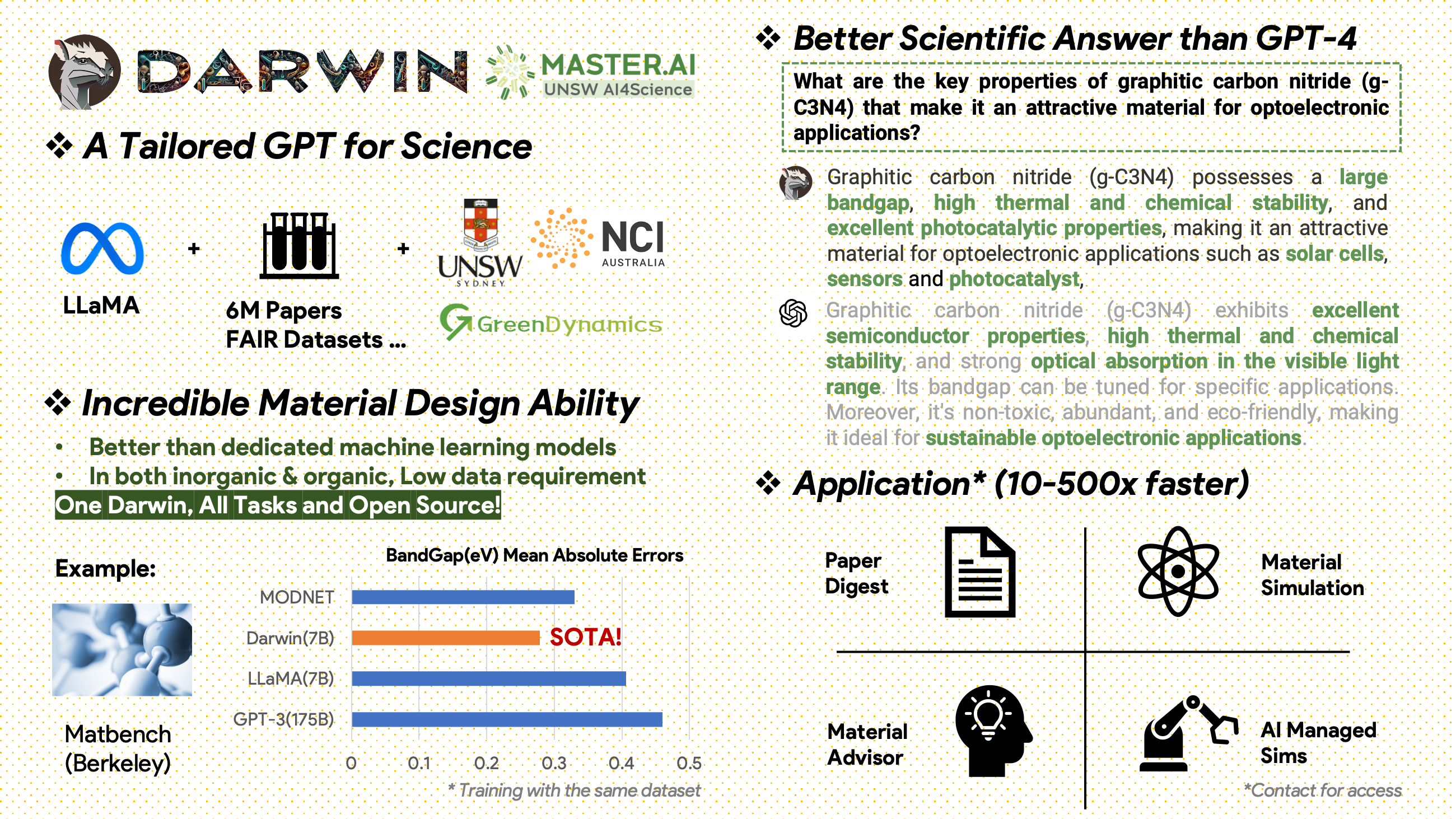
[2024.02.15] SOTA en MatBench de Material Projects: DARWIN es el modelo SOTA en tareas experimentales de predicción de banda prohibida y tareas de clasificación metálica, mejor que el GPT3.5 ajustado y los modelos ML dedicados. https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Versión de Google Colab disponible: Pruebe nuestro DARWIN con Google Colab: inference.ipynb
Darwin, basado en el modelo 7B LLaMA, está entrenado en más de 100.000 puntos de datos de seguimiento de instrucciones generados por el Generador de Instrucción Científica (SIG) de Darwin a partir de varios conjuntos de datos científicos FAIR y un corpus de literatura. Al centrarse en la exactitud fáctica de las respuestas del modelo, Darwin representa un paso significativo hacia el aprovechamiento de los modelos de lenguajes grandes (LLM) para el descubrimiento científico. Las evaluaciones humanas preliminares indican que Darwin 7B supera al GPT-4 en preguntas y respuestas científicas y al GPT-3 afinado en la resolución de problemas químicos (como gptChem).
Estamos desarrollando activamente a Darwin para experimentos de dominio científico más avanzados y también estamos integrando Darwin con LangChain para resolver tareas científicas más complejas (como un asistente de investigación privado para computadoras personales).
Tenga en cuenta que Darwin aún está en desarrollo y es necesario abordar muchas limitaciones. Lo más importante es que todavía tenemos que ajustar Darwin para lograr la máxima seguridad. Alentamos a los usuarios a informar cualquier comportamiento preocupante para ayudar a mejorar las consideraciones éticas y de seguridad del modelo.
ENLACE DE DEMOSTRACIÓN
Primero instale los requisitos:
pip install -r requirements.txtDescarga los puntos de control de las Pesas Darwin-7B desde onedrive. Una vez que hayas descargado el modelo, puedes probar nuestra demostración:
python inference.py < your path to darwin-7b >Tenga en cuenta que la inferencia requiere al menos 10 GB de memoria GPU para Darwin 7B.
Para perfeccionar aún más nuestro Darwin-7b con diferentes conjuntos de datos, a continuación se muestra un comando que funciona en una máquina con 4 GPU A100 80G.
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path < your path to darwin-7b >
--data_path < your path to dataset >
--bf16 True
--output_dir < your output dir >
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 FalseNuestros datos provienen de dos fuentes principales:
Después de 2000 se publicó un corpus de literatura sin editar que contiene 6,0 millones de artículos sobre ciencia de materiales, química y física. Los editores incluyen ACS, RSC, Springer Nature, Wiley y Elsevier. Les agradecemos su apoyo.
Conjuntos de datos FAIR: hemos recopilado datos de 16 conjuntos de datos FAIR.
Desarrollamos Darwin-SIG para generar instrucciones científicas. Puede memorizar textos extensos de textos literarios completos (promedio ~5000 palabras) y generar datos de preguntas y respuestas basados en palabras clave de literatura científica (de la API de web of science)
Nota: También puede utilizar GPT3.5 o GPT-4 para la generación, pero estas opciones pueden resultar costosas.
Tenga en cuenta que no podemos compartir el conjunto de datos de capacitación debido a acuerdos con los editores.
Este proyecto es un esfuerzo colaborativo de lo siguiente:
UNSW y GreenDynamics: Tong Xie, Shaozhou Wang
UNSW: Imran Razzak, Cody Huang
Centro USYD & DARE: Clara Grazian
Dinámica Verde: Yuwei Wan, Yixuan Liu
Bram Hoex y Wenjie Zhang de UNSW Engineering asesoraron a todos.
Si utiliza los datos o el código de este repositorio en su trabajo, cítelo en consecuencia.
Modelo fundamental de lenguaje grande de DAWRIN y ajuste fino de semiautoinstrucción
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GPT-3 y LLaMA ajustados para el descubrimiento de materiales (capacitación de tarea única)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
Este proyecto se ha referido a los siguientes proyectos de código abierto:
Un agradecimiento especial al NCI Australia por su apoyo a HPC.
Ampliamos continuamente el equipo de desarrollo de Darwin. ¡Únase a nosotros en este emocionante viaje para avanzar en la investigación científica con IA!
Para puestos de doctorado o posdoctorado, póngase en contacto con [email protected] o [email protected] para obtener más detalles.
Para otros puestos, visite www.greendynamics.com.au


