Indian LawyerGPT
1.0.0
Bienvenido a nuestro apasionante proyecto en el que estamos adaptando dos modelos de lenguaje de vanguardia, Falcon-7B y LLAMA 2, para dominar la legislación india.
Nuestra aventura comenzó con unas modestas 150 preguntas y respuestas sobre la legislación india. ¡Ahora estamos avanzando con un impresionante conjunto de datos de 3300 instrucciones! Este proyecto legal de IA combina:

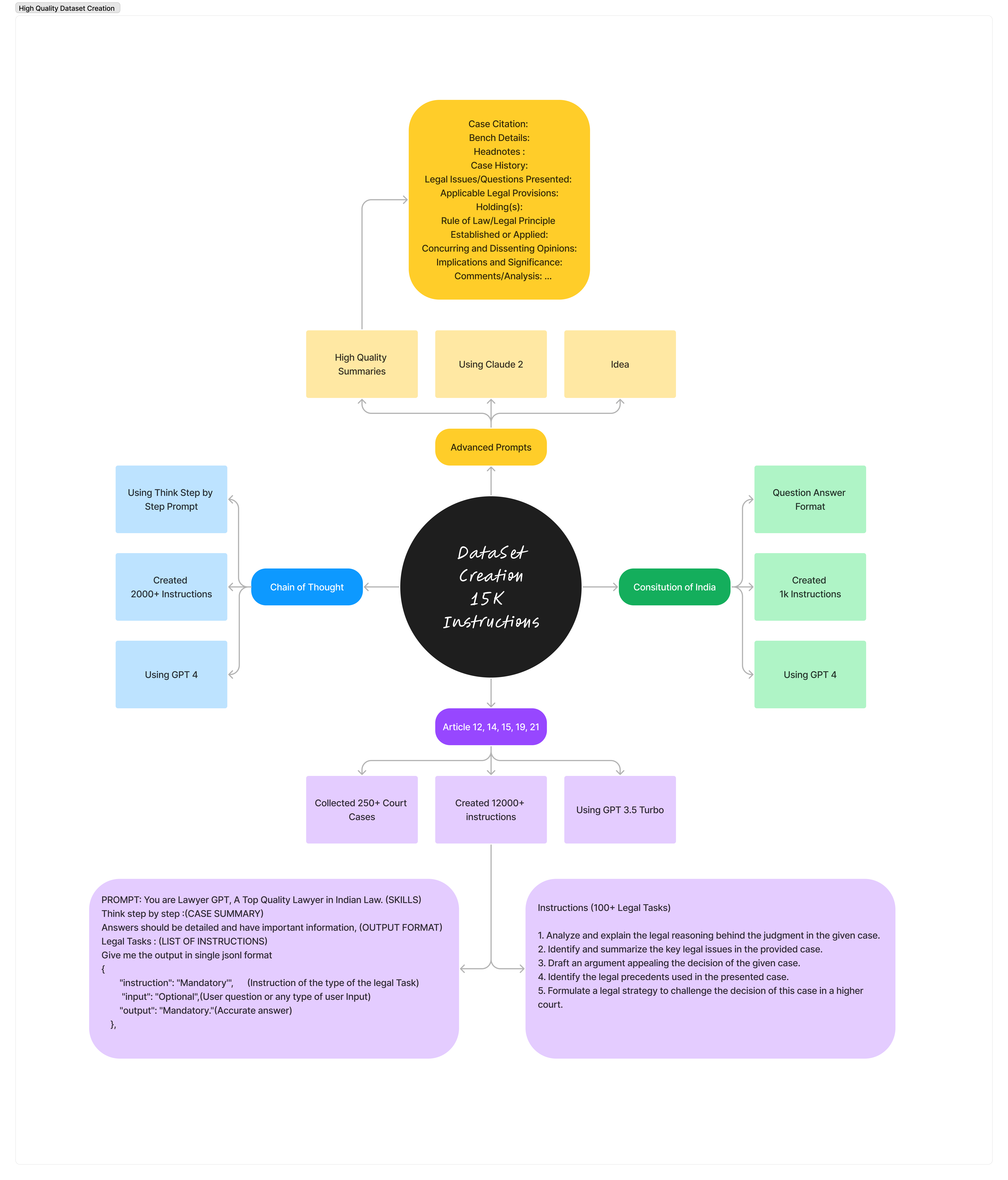
Nuestro conjunto de datos está diseñado con cuatro características clave: instruction , input , output y prompt . ¡Diseñado para convertir nuestros modelos en expertos en leyes de IA! Conjunto de datos sobre Hugging Face: https://huggingface.co/datasets/nisaar/Constitution_Of_India_Instruction_Set https://huggingface.co/datasets/nisaar/Articles_Constitution_3300_Instruction_Set https://huggingface.co/datasets/nisaar/LLAMA2_Legal_Dataset_4.4k_Instructions
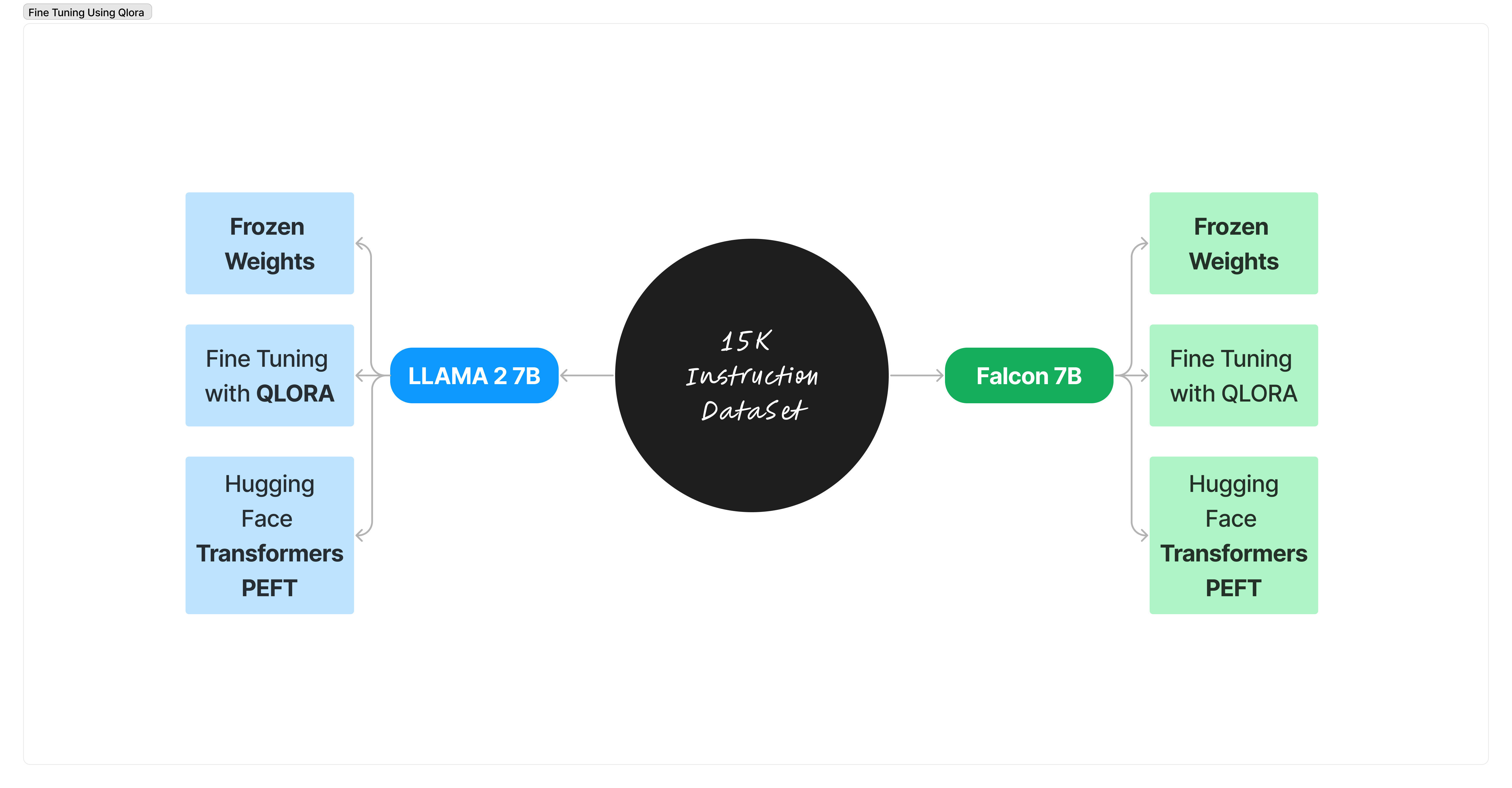
Obtenga un asiento en primera fila para ver el progreso del entrenamiento con TensorBoard. Inícielo, navegue hasta el enlace de localhost proporcionado y observe cómo aprenden los modelos:


