multimedia gpt
1.0.0
Multimedia GPT conecta su OpenAI GPT con visión y audio. Ahora puede enviar imágenes, grabaciones de audio y documentos pdf utilizando su clave API de OpenAI y obtener una respuesta en formato de texto e imagen. Actualmente estamos agregando soporte para videos. Todo es posible gracias a un administrador rápido inspirado y construido sobre Microsoft Visual ChatGPT.
Además de todos los modelos básicos de visión mencionados en Microsoft Visual ChatGPT, Multimedia GPT es compatible con OpenAI Whisper y OpenAI DALLE. Esto significa que ya no necesitarás tus propias GPU para el reconocimiento de voz y la generación de imágenes (¡aunque todavía puedes hacerlo!)
El modelo de chat base se puede configurar como cualquier OpenAI LLM , incluidos ChatGPT y GPT-4. Por defecto utilizamos text-davinci-003 .
Le invitamos a bifurcar este proyecto y agregar modelos que sean adecuados para su propio caso de uso. Una forma sencilla de hacerlo es a través de llama_index. Tendrá que crear una nueva clase para su modelo en model.py y agregar un método de ejecución run_<model_name> en multimedia_gpt.py . Consulte run_pdf para ver un ejemplo.
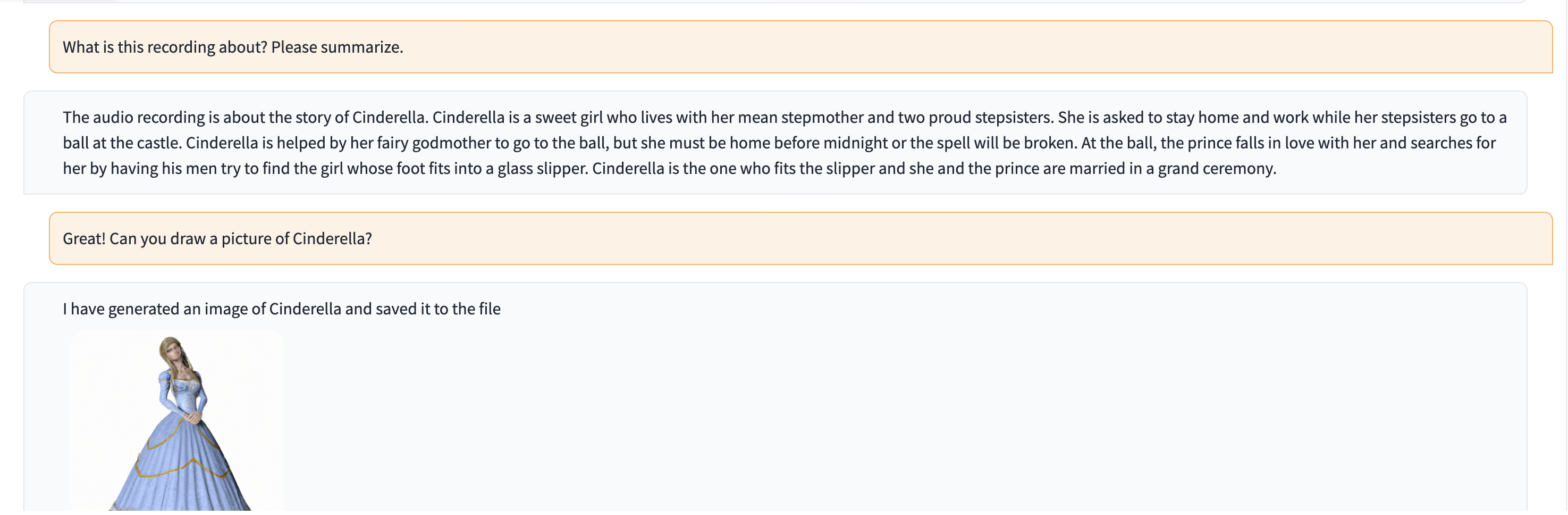
En esta demostración, ChatGPT se alimenta con una grabación de una persona contando la historia de Cenicienta.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Este proyecto es un trabajo experimental y no se implementará en un entorno de producción. Nuestro objetivo es explorar el poder de las indicaciones.


