SwiftInfer
1.0.0
Streaming-LLM es una técnica que admite una longitud de entrada infinita para la inferencia de LLM. Aprovecha Attention Sink para evitar que el modelo colapse cuando cambia la ventana de atención. El trabajo original se implementa en PyTorch, ofrecemos SwiftInfer , una implementación de TensorRT para hacer que StreamingLLM tenga más nivel de producción. Nuestra implementación se basó en el proyecto TensorRT-LLM lanzado recientemente.
Usamos la API en TensorRT-LLM para construir el modelo y ejecutar la inferencia. Como la API de TensorRT-LLM no es estable y cambia rápidamente, vinculamos nuestra implementación con la confirmación 42af740db51d6f11442fd5509ef745a4c043ce51 cuya versión es v0.6.0 . Es posible que actualicemos este repositorio a medida que las API de TensorRT-LLM se vuelvan más estables.
Si ha compilado TensorRT-LLM V0.6.0 , simplemente ejecute:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .De lo contrario, primero debes instalar TensorRT-LLM.
Si usa Docker, puede seguir la instalación de TensorRT-LLM para instalar TensorRT-LLM V0.6.0 .
Al usar Docker, puedes instalar SwiftInfer simplemente ejecutando:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Si no utiliza Docker, proporcionamos un script para instalar TensorRT-LLM automáticamente.
Requisitos previos
Asegúrese de haber instalado los siguientes paquetes:
Asegúrese de que la versión de TensorRT >= 9.1.0 y el kit de herramientas CUDA >= 12.2.
Para instalar tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Para descargar nccl, siga la página de descarga de NCCL.
Para descargar cudnn, siga la página de descarga de cuDNN.
Comandos
Antes de ejecutar los siguientes comandos, asegúrese de haber configurado nvcc correctamente. Para comprobarlo, ejecute:
nvcc --versionPara instalar TensorRT-LLM y SwiftInfer, ejecute:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Para ejecutar el ejemplo de Llama, primero debe clonar el repositorio de Hugging Face para el modelo meta-llama/Llama-2-7b-chat-hf u otras variantes basadas en Llama como lmsys/vicuna-7b-v1.3. Luego, puede ejecutar el siguiente comando para construir el motor TensorRT. Debes reemplazar <model-dir> con la ruta real al modelo Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1A continuación, debe descargar los datos de MT-Bench proporcionados por LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlFinalmente, está listo para ejecutar el ejemplo de Llama con el siguiente comando.
❗️❗️❗️ Antes de eso, tenga en cuenta que:
only_n_first se utiliza para controlar la cantidad de muestras que se evaluarán. Si desea evaluar todas las muestras, elimine este argumento. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Debería esperar ver a la generación de la siguiente manera:
Hemos comparado nuestras implementaciones de Streaming-LLM con la versión original de PyTorch. El comando de referencia para nuestra implementación se proporciona en la sección Ejecutar ejemplo de Llama, mientras que el de la implementación original de PyTorch se proporciona en la carpeta torch_streamingllm. El hardware utilizado se enumera a continuación:
Los resultados (20 rondas de conversaciones) son:
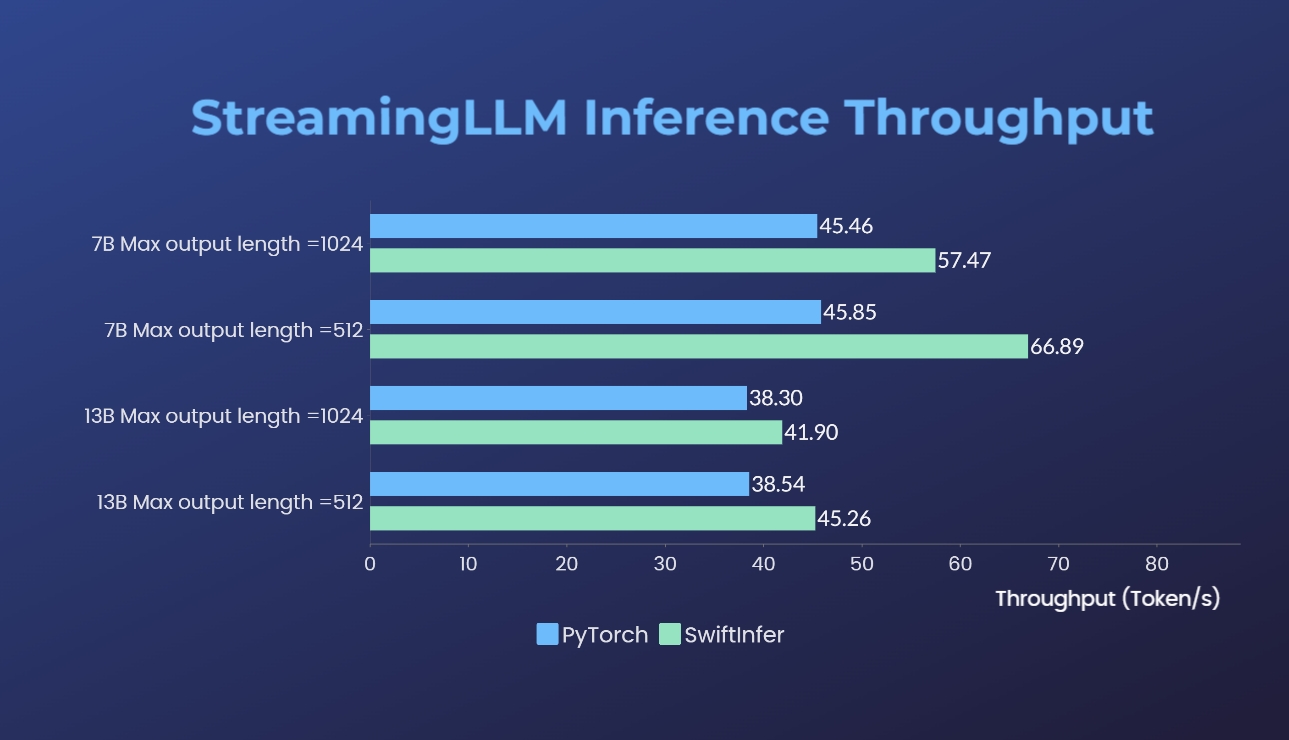
Todavía estamos trabajando para mejorar aún más el rendimiento y adaptarnos a las API de TensorRT V0.7.1. También notamos que TensorRT-LLM ha integrado StreamingLLM en su ejemplo, pero parece que es más adecuado para la generación de un solo texto en lugar de conversaciones de varias rondas.
Este trabajo está inspirado en Streaming-LLM para que sea utilizable para producción. A lo largo del desarrollo, hemos hecho referencia a los siguientes materiales y deseamos reconocer sus esfuerzos y contribuciones a la comunidad y el mundo académico de código abierto.
Si encuentra útil StreamingLLM y nuestra implementación de TensorRT, cite amablemente nuestro repositorio y el trabajo original propuesto por Xiao et al. del laboratorio Han del MIT.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

