paxml
paxml release 1.4.0
Pax es un marco para configurar y ejecutar experimentos de aprendizaje automático sobre Jax.
Nos referimos a esta página para obtener documentación más exhaustiva sobre cómo iniciar un proyecto de Cloud TPU. El siguiente comando es suficiente para crear una VM Cloud TPU con 8 núcleos desde una máquina corporativa.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Si está utilizando segmentos de TPU Pod, consulte esta guía. Ejecute todos los comandos desde una máquina local usando gcloud con la opción --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "Las siguientes secciones de inicio rápido suponen que ejecuta en una TPU de un solo host, por lo que puede conectarse mediante ssh a la máquina virtual y ejecutar los comandos allí.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONEDespués de realizar ssh en la VM, puede instalar la versión estable de paxml desde PyPI o la versión de desarrollo desde github.
Para instalar la versión estable de PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Si tiene problemas con las dependencias transitivas y está utilizando el entorno nativo de Cloud TPU VM, navegue hasta la rama de versión correspondiente rX.YZ y descargue paxml/pip_package/requirements.txt . Este archivo incluye las versiones exactas de todas las dependencias transitivas necesarias en el entorno nativo de VM de Cloud TPU, en el que creamos/probamos la versión correspondiente.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtPara instalar la versión de desarrollo desde github y para facilitar la edición del código:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueVisite nuestra carpeta de documentos para obtener documentación y tutoriales de Jupyter Notebook. Consulte la siguiente sección para obtener instrucciones sobre cómo ejecutar Jupyter Notebooks en una VM de Cloud TPU.
Puede ejecutar los cuadernos de ejemplo en la máquina virtual de TPU en la que acaba de instalar paxml. ####Pasos para habilitar una notebook en una v4-8
ssh en VM de TPU con reenvío de puertos gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
instale jupyter notebook en la máquina virtual de TPU y baje la versión de markupsafe
pip install notebook
pip install markupsafe==2.0.1
exportar ruta jupyter export PATH=/home/$USER/.local/bin:$PATH
scp los cuadernos de ejemplo a su VM de TPU gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
Inicie jupyter notebook desde la máquina virtual de TPU y anote el token generado por jupyter notebook jupyter notebook --no-browser --port=8080
luego, en su navegador local, vaya a: http://localhost:8080/ e ingrese el token proporcionado
Nota: En caso de que necesite comenzar a usar una segunda computadora portátil mientras la primera todavía ocupa las TPU, puede ejecutar pkill -9 python3 para liberar las TPU.
Nota: NVIDIA ha lanzado una versión actualizada de Pax con compatibilidad con H100 FP8 y amplias mejoras en el rendimiento de la GPU. Visite el repositorio de NVIDIA Rosetta para obtener más detalles e instrucciones de uso.
El flujo de trabajo del Estimador de latencia guiado por perfiles (PGLE) mide el tiempo de ejecución real de la computación y los colectivos; la información del perfil se devuelve al compilador XLA para una mejor decisión de programación.
El Estimador de latencia guiado por perfiles se puede utilizar de forma manual o automática. En el modo automático, JAX recopilará información del perfil y recompilará un módulo en una sola ejecución. Mientras está en modo manual, necesita ejecutar una tarea dos veces, la primera para recopilar y guardar perfiles y la segunda para compilar y ejecutar con los datos proporcionados.
El PGLE automático se puede activar configurando las siguientes variables de entorno:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
O en JAX esto se puede configurar de la siguiente manera:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Puede controlar la cantidad de repeticiones utilizadas para recopilar datos de perfil cambiando JAX_PGLE_PROFILING_RUNS . Aumentar este parámetro conduciría a una mejor información del perfil, pero también aumentará la cantidad de pasos de entrenamiento no optimizados.
Los parámetros JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY permiten utilizar devoluciones de llamada del host con PGLE automático.
Disminuir el parámetro JAX_PGLE_AGGREGATION_PERCENTILE puede ayudar en caso de que el rendimiento entre pasos sea demasiado ruidoso para filtrar medidas no relevantes.
Atención: Auto PGLE no funciona con módulos precompilados. Dado que JAX necesita recompilar el módulo durante la ejecución, el PGLE automático no funcionará ni para AoT ni para el siguiente caso:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Si aún desea utilizar un estimador de latencia guiado por perfil manual, el flujo de trabajo en XLA/GPU es:
Podrías hacerlo configurando:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) Después de este paso, obtendrá un archivo profile.pb en el rundir impreso en el código.
Debe pasar el archivo profile.pb al indicador --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Para habilitar el inicio de sesión en XLA y verificar si el perfil es bueno, configure el nivel de registro para incluir INFO :
export TF_CPP_MIN_LOG_LEVEL=0Ejecute el flujo de trabajo real; si encontró estos registros en el registro en ejecución, significa que el generador de perfiles se usa en el programador de ocultación de latencia:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax se ejecuta en Jax, puede encontrar detalles sobre cómo ejecutar trabajos de Jax en Cloud TPU aquí, también puede encontrar detalles sobre cómo ejecutar trabajos de Jax en un pod de Cloud TPU aquí
Si encuentra errores de dependencia, consulte el archivo requirements.txt en la rama correspondiente a la versión estable que está instalando. Por ejemplo, para la versión estable 0.4.0 use la rama r0.4.0 y consulte el archivo require.txt para conocer las versiones exactas de las dependencias utilizadas para la versión estable.
A continuación se muestran algunos ejemplos de ejecuciones de convergencia en el conjunto de datos c4.
Puede ejecutar un modelo de parámetros 1B en el conjunto de datos c4 en TPU v4-8 usando la configuración C4Spmd1BAdam4Replicas de c4.py de la siguiente manera:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > Puede observar la curva de pérdidas y el gráfico log perplexity de la siguiente manera:
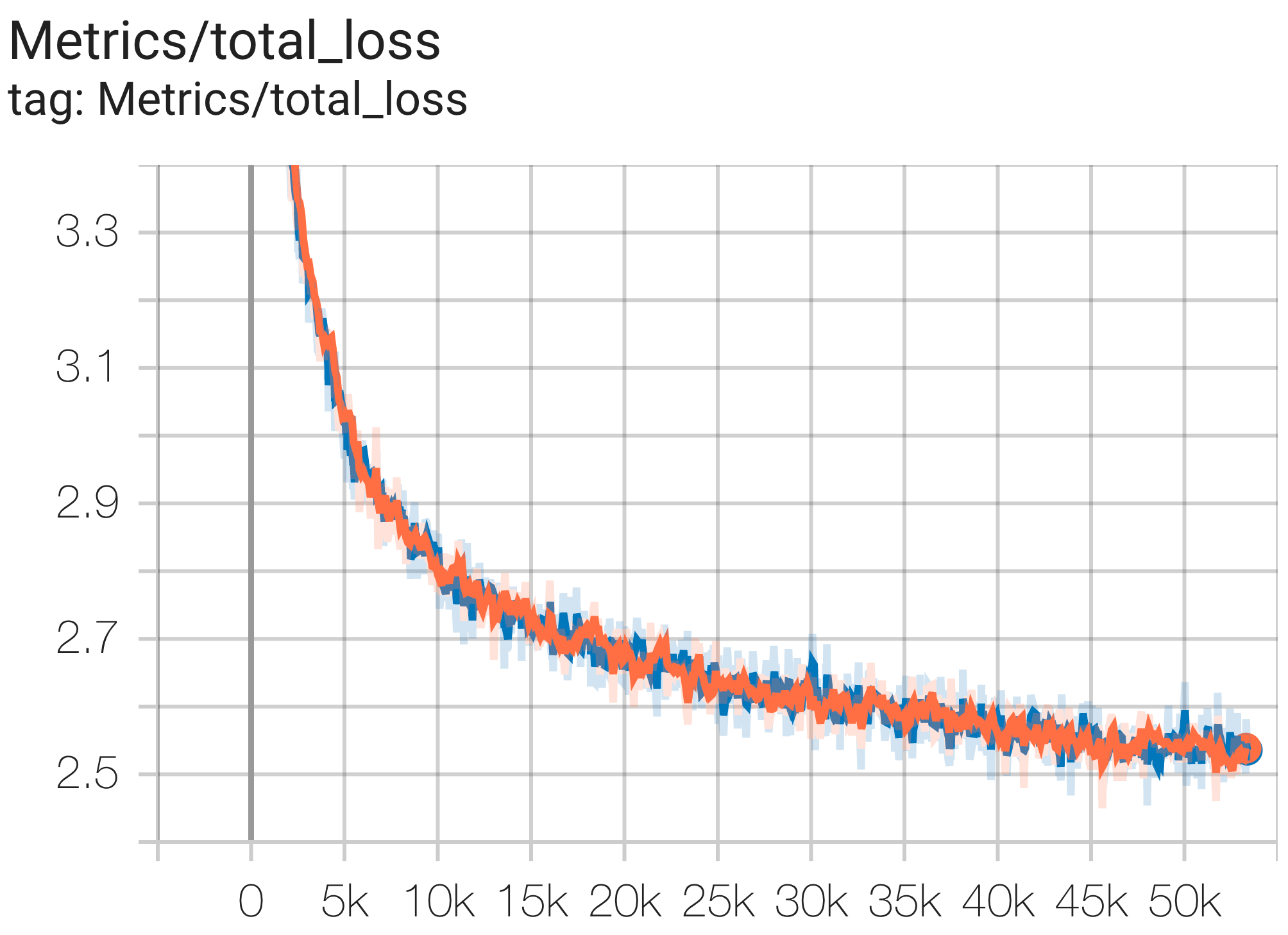
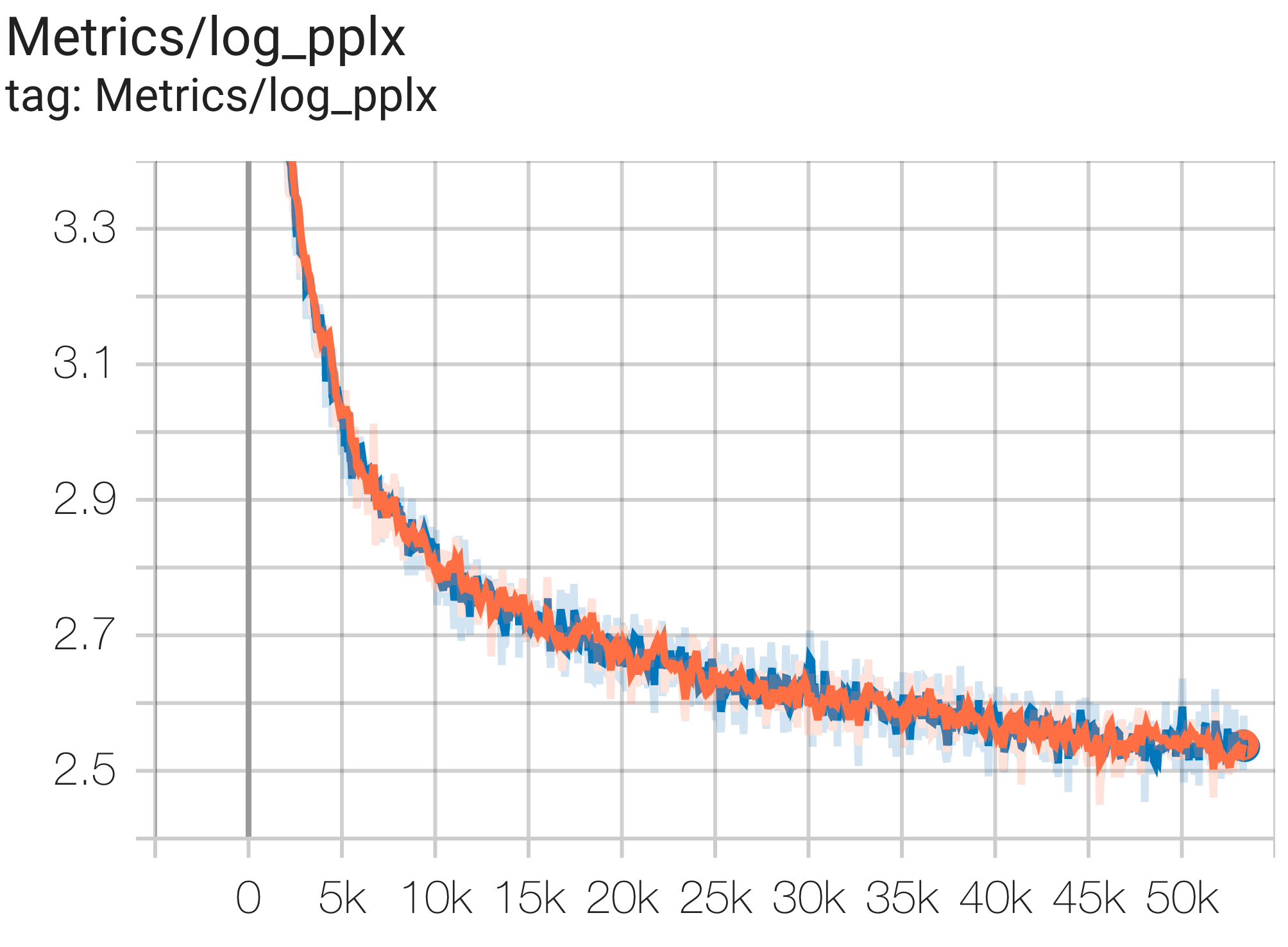
Puede ejecutar un modelo de parámetros 16B en el conjunto de datos c4 en TPU v4-64 usando la configuración C4Spmd16BAdam32Replicas de c4.py de la siguiente manera:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > Puede observar la curva de pérdidas y el gráfico log perplexity de la siguiente manera:
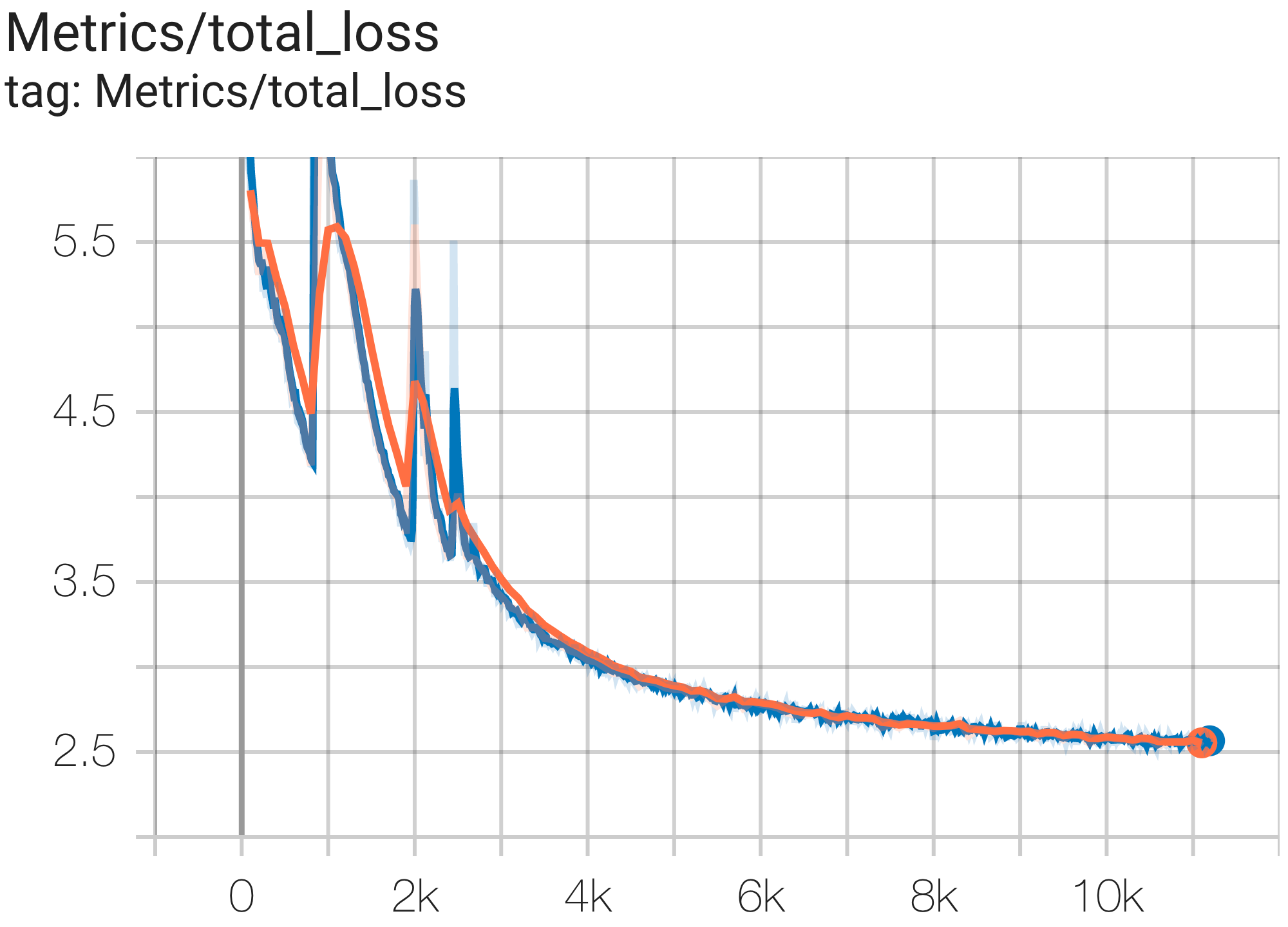
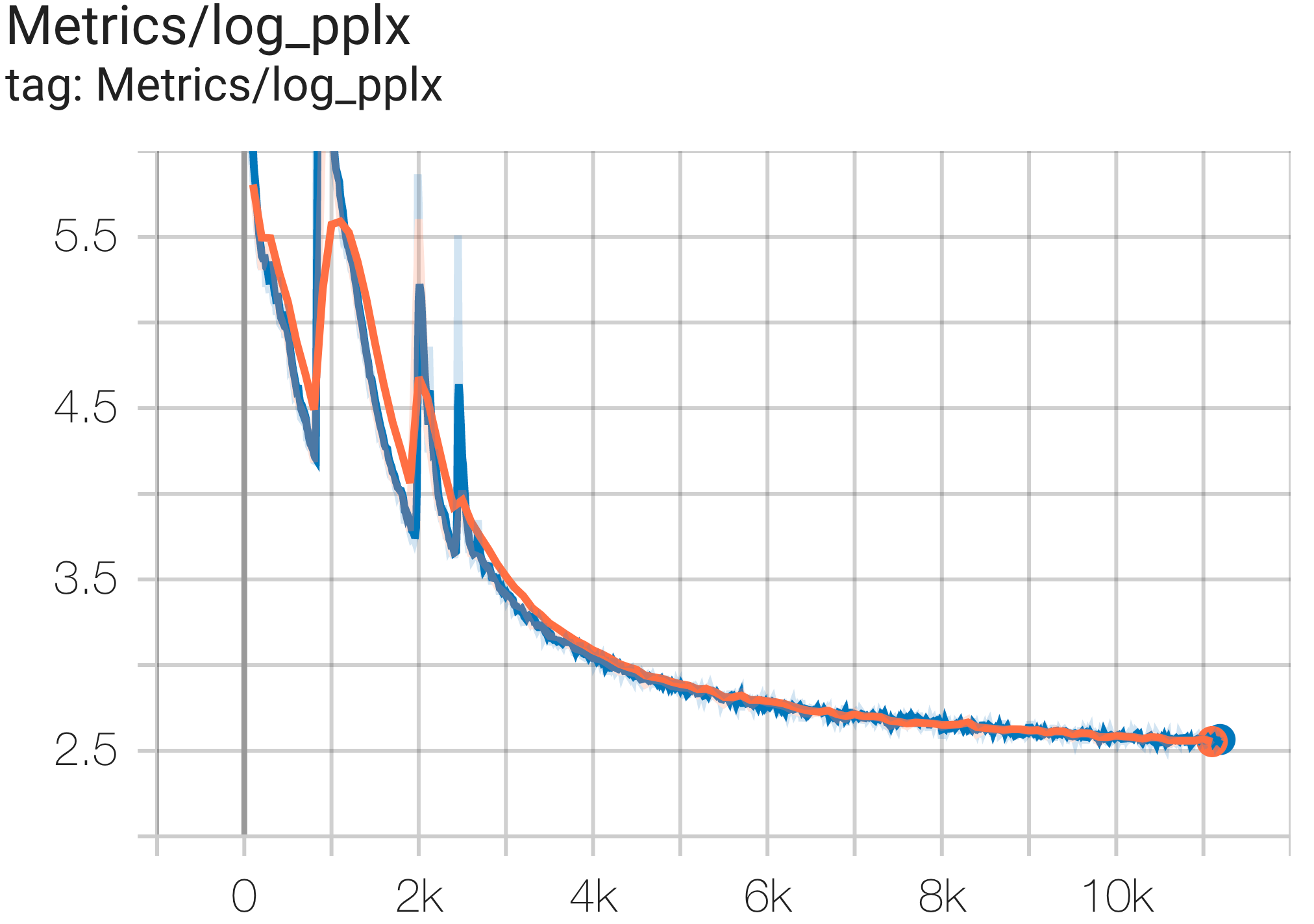
Puede ejecutar el modelo GPT3-XL en el conjunto de datos c4 en TPU v4-128 usando la configuración C4SpmdPipelineGpt3SmallAdam64Replicas de c4.py de la siguiente manera:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > Puede observar la curva de pérdidas y el gráfico log perplexity de la siguiente manera:
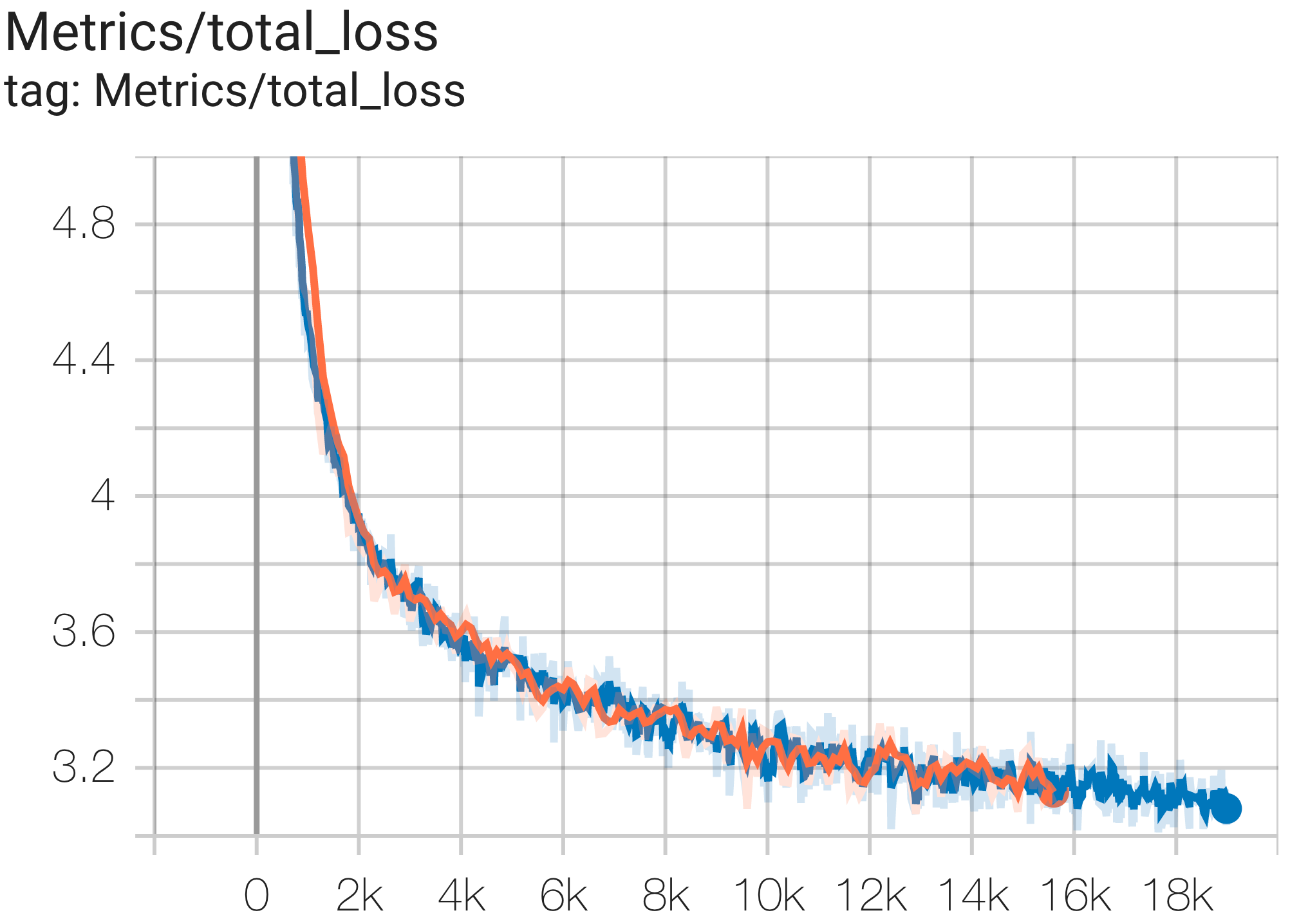
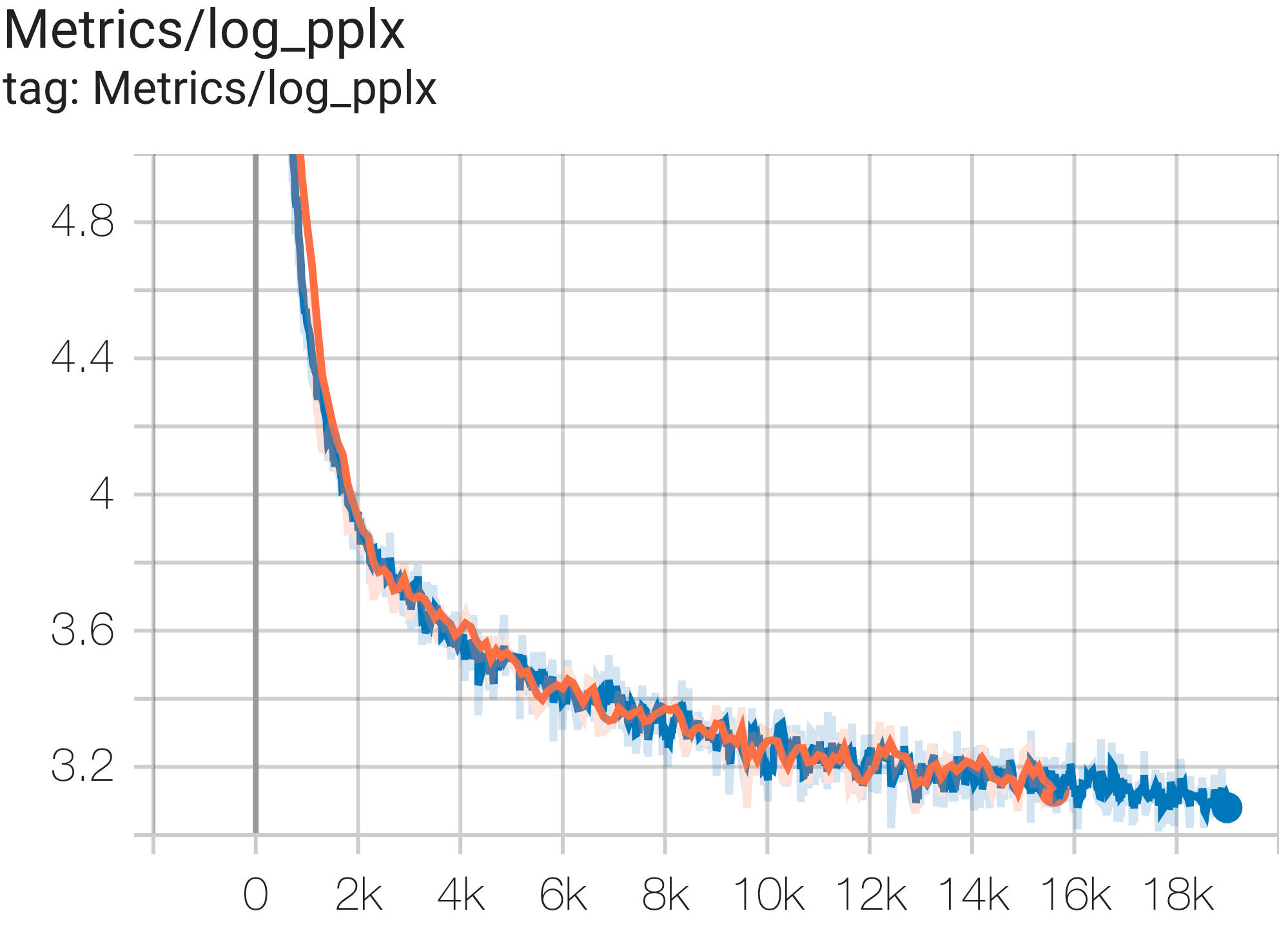
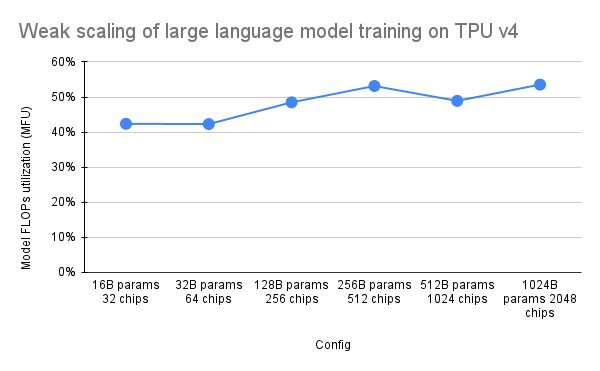
El documento de PaLM introdujo una métrica de eficiencia llamada Utilización de FLOP modelo (MFU). Esto se mide como la relación entre el rendimiento observado (en, por ejemplo, tokens por segundo para un modelo de lenguaje) y el rendimiento máximo teórico de un sistema que aprovecha el 100 % de los FLOP máximos. Se diferencia de otras formas de medir la utilización de la computación porque no incluye los FLOP gastados en la rematerialización de la activación durante el paso hacia atrás, lo que significa que la eficiencia medida por MFU se traduce directamente en velocidad de entrenamiento de un extremo a otro.
Para evaluar la MFU de una clase clave de cargas de trabajo en Pods TPU v4 con Pax, llevamos a cabo una campaña de referencia en profundidad en una serie de configuraciones del modelo de lenguaje Transformer (GPT) solo de decodificador que varían en tamaño desde miles de millones hasta billones de parámetros. en el conjunto de datos c4. El siguiente gráfico muestra la eficiencia del entrenamiento utilizando el patrón de "escala débil" donde aumentamos el tamaño del modelo en proporción a la cantidad de chips utilizados.
Las configuraciones de múltiples sectores en este repositorio se refieren a 1. Configuraciones de sectores individuales para sintaxis/arquitectura de modelo y 2. Repositorio MaxText para valores de configuración.
Proporcionamos ejecuciones de ejemplo en c4_multislice.py` como punto de partida para Pax en multislice.
Nos referimos a esta página para obtener documentación más exhaustiva sobre el uso de recursos en cola para un proyecto de Cloud TPU de múltiples segmentos. A continuación se muestran los pasos necesarios para configurar TPU para ejecutar configuraciones de ejemplo en este repositorio.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Digamos que, para ejecutar C4Spmd22BAdam2xv4_128 en 2 segmentos de v4-128, necesitaría configurar las TPU de la siguiente manera:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Los comandos de configuración descritos anteriormente deben ejecutarse en TODOS los trabajadores en TODOS los sectores. Puede 1) realizar ssh en cada trabajador y cada segmento individualmente; o 2) use el bucle for con el indicador --worker=all como el siguiente comando.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Para ejecutar las configuraciones multislice, abra la misma cantidad de terminales que su $NODE_COUNT. Para nuestros experimentos en 2 sectores ( C4Spmd22BAdam2xv4_128 ), abra dos terminales. Luego, ejecute cada uno de estos comandos individualmente desde cada terminal.
Desde la Terminal 0, ejecute el comando de entrenamiento para el segmento 0 de la siguiente manera:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Desde la Terminal 1, ejecute simultáneamente el comando de entrenamiento para el segmento 1 de la siguiente manera:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Esta tabla cubre detalles sobre cómo los nombres de las variables MaxText se han traducido a Pax.
Tenga en cuenta que MaxText tiene una "escala" que se multiplica por varios parámetros (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) para obtener los valores finales.
Otra cosa a mencionar es que mientras Pax cubre DCN e ICN MESH_SHAPE como una matriz, en MaxText hay variables separadas de data_parallelism, fsdp_parallelism y tensor_parallelism para DCN e ICI. Dado que estos valores están configurados en 1 de forma predeterminada, solo las variables con un valor mayor que 1 se registran en esta tabla de traducción.
Es decir, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] y DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Pax C4Spmd22BAdam2xv4_128 | Texto máximo 2xv4-128.sh | (después de aplicar la escala) | ||
|---|---|---|---|---|
| escala (aplicada a las siguientes 4 variables) | 3 | |||
| NUM_CAPAS | 48 | base_num_decoder_layers | 16 | 48 |
| MODELO_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODELO_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_CABEZAS | 24 | base_num_cabezas | 8 | 24 |
| DIMS_PER_HEAD | 256 | cabeza_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | por_dispositivo_lote_tamaño | 16 | |
| MAX_SEQ_LEN | 1024 | longitud_objetivo_max | 1024 | |
| VOCAB_SIZE | 32768 | tamaño_vocab | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | tipo d | bfloat16 | |
| USE_REPEATED_LAYER | VERDADERO | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_paralelismo | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_paralelismo | 2 |
La entrada es una instancia de la clase BaseInput para introducir datos en el modelo para entrenar/evaluar/decodificar.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Actúa como un iterador: get_next() devuelve un NestedMap , donde cada campo es una matriz numérica con el tamaño del lote como dimensión principal.
Cada entrada está configurada por una subclase de BaseInput.HParams . En esta página, usamos p para indicar una instancia de BaseInput.Params y crea una instancia para input .
En Pax, los datos siempre son multihost: cada proceso de Jax tendrá una input separada e independiente instanciada. Sus parámetros tendrán diferentes p.infeed_host_index , establecidos automáticamente por Pax.
Por lo tanto, el tamaño del lote local que se ve en cada host es p.batch_size y el tamaño del lote global es (p.batch_size * p.num_infeed_hosts) . A menudo se verá p.batch_size configurado en jax.local_device_count() * PERCORE_BATCH_SIZE .
Debido a esta naturaleza multihost, input se debe fragmentar correctamente.
Para el entrenamiento, cada input nunca debe emitir lotes idénticos y, para la evaluación en un conjunto de datos finito, cada input debe terminar después de la misma cantidad de lotes. La mejor solución es que la implementación de entrada fragmente adecuadamente los datos, de modo que cada input en diferentes hosts no se superponga. De lo contrario, también se pueden utilizar diferentes semillas aleatorias para evitar lotes duplicados durante el entrenamiento.
input.reset() nunca se llama para datos de entrenamiento, pero sí para evaluar (o decodificar) datos.
Para cada ejecución de evaluación (o decodificación), Pax recupera N lotes de input llamando input.get_next() N veces. El número de lotes utilizados, N , puede ser un número fijo especificado por el usuario, a través de p.eval_loop_num_batches ; o N puede ser dinámico ( p.eval_loop_num_batches=None ), es decir, llamamos input.get_next() hasta que agotamos todos sus datos (generando StopIteration o tf.errors.OutOfRange ).
Si p.reset_for_eval=True , se ignora p.eval_loop_num_batches y N se determina dinámicamente como el número de lotes para agotar los datos. En este caso, p.repeat debe establecerse en False, ya que de lo contrario se produciría una decodificación/evaluación infinita.
Si p.reset_for_eval=False , Pax buscará lotes de p.eval_loop_num_batches . Esto debe configurarse con p.repeat=True para que los datos no se agoten prematuramente.
Tenga en cuenta que las entradas de LingvoEvalAdaptor requieren p.reset_for_eval=True .
N : estático | N : dinámico | |
|---|---|---|
p.reset_for_eval=True | Cada ejecución de evaluación utiliza el | Una época por ejecución de evaluación. |
: : primeros N lotes. No: eval_loop_num_batches : | ||
| : : soportado todavía. : se ignora. La entrada debe: | ||
| : : : ser finito : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Cada ejecución de evaluación utiliza | No compatible. |
: : no superpuestos N : : | ||
| : : lotes en rollo : : | ||
| : : base, según : : | ||
: : eval_loop_num_batches : : | ||
| : : . La entrada debe repetirse: : | ||
| : : indefinidamente : : | ||
: : ( p.repeat=True ) o : : | ||
| : : de lo contrario puede aumentar : : | ||
| : : excepción : : |
Si ejecuta decode/eval exactamente en una época (es decir, cuando p.reset_for_eval=True ), la entrada debe manejar la fragmentación correctamente de modo que cada fragmento se eleve en el mismo paso después de que se produzca exactamente la misma cantidad de lotes. Esto generalmente significa que la entrada debe rellenar los datos de evaluación. Esto lo hacen automáticamente SeqIOInput y LingvoEvalAdaptor (ver más a continuación).
Para la mayoría de las entradas, solo llamamos get_next() para obtener lotes de datos. Un tipo de datos de evaluación es una excepción a esto, donde "cómo calcular métricas" también se define en el objeto de entrada.
Esto solo se admite con SeqIOInput que define algún punto de referencia de evaluación canónico. Específicamente, Pax usa predict_metric_fns y score_metric_fns() definidos en la tarea SeqIO para calcular métricas de evaluación (aunque Pax no depende directamente del evaluador SeqIO).
Cuando un modelo utiliza múltiples entradas, ya sea entre entrenamiento/evaluación o diferentes datos de entrenamiento entre preentrenamiento/ajuste fino, los usuarios deben asegurarse de que los tokenizadores utilizados por las entradas sean idénticos, especialmente al importar diferentes entradas implementadas por otros.
Los usuarios pueden verificar la cordura de los tokenizadores decodificando algunos identificadores con input.ids_to_strings() .
Siempre es una buena idea comprobar la cordura de los datos observando algunos lotes. Los usuarios pueden reproducir fácilmente el parámetro en una colab e inspeccionar los datos:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) Los datos de entrenamiento normalmente no deberían utilizar una semilla aleatoria fija. Esto se debe a que si se adelanta el trabajo de entrenamiento, los datos de entrenamiento comenzarán a repetirse. En particular, para las entradas de Lingvo, recomendamos configurar p.input.file_random_seed = 0 para los datos de entrenamiento.
Para probar si la fragmentación se maneja correctamente, los usuarios pueden establecer manualmente diferentes valores para p.num_infeed_hosts, p.infeed_host_index y ver si las entradas instanciadas emiten lotes diferentes.
Pax admite 3 tipos de entradas: SeqIO, Lingvo y personalizada.
SeqIOInput se puede utilizar para importar conjuntos de datos.
Las entradas SeqIO manejan automáticamente la fragmentación y el relleno correctos de los datos de evaluación.
LingvoInputAdaptor se puede utilizar para importar conjuntos de datos.
La entrada se delega completamente a la implementación de Lingvo, que puede o no manejar la fragmentación automáticamente.
Para la implementación de entrada Lingvo basada en GenericInput utilizando un packing_factor fijo, recomendamos usar LingvoInputAdaptorNewBatchSize para especificar un tamaño de lote más grande para la entrada Lingvo interna y colocar el tamaño de lote deseado (generalmente mucho más pequeño) en p.batch_size .
Para datos de evaluación, recomendamos usar LingvoEvalAdaptor para manejar la fragmentación y el relleno para ejecutar eval durante una época.
Subclase personalizada de BaseInput . Los usuarios implementan su propia subclase, normalmente con tf.data o SeqIO.
Los usuarios también pueden heredar una clase de entrada existente para personalizar únicamente el posprocesamiento de lotes. Por ejemplo:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchLos hiperparámetros son una parte importante de la definición de modelos y la configuración de experimentos.
Para integrarse mejor con las herramientas de Python, Pax/Praxis utiliza un estilo de configuración basado en clases de datos Python para hiperparámetros.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0También es posible anidar clases de datos HParams; en el siguiente ejemplo, el atributo linear_tpl es un Linear.HParams anidado.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Una capa representa una función arbitraria posiblemente con parámetros entrenables. Una Capa puede contener otras Capas como hijas. Las capas son los componentes básicos de los modelos. Las capas heredan del Flax nn.Module.
Normalmente las capas definen dos métodos:
Este método crea pesos entrenables y capas secundarias.
Este método define la función de propagación hacia adelante, calculando alguna salida en función de las entradas. Además, fprop podría agregar resúmenes o realizar un seguimiento de las pérdidas auxiliares.
Fiddle es una biblioteca de configuración de código abierto diseñada para aplicaciones de aprendizaje automático. Pax/Praxis admite la interoperabilidad con Fiddle Config/Partial(s) y algunas funciones avanzadas como la verificación de errores y los parámetros compartidos.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Con Fiddle, las capas se pueden configurar para que se compartan (por ejemplo, crear instancias solo una vez con pesos entrenables compartidos).
Un modelo define únicamente la red, normalmente una colección de capas, y define interfaces para interactuar con el modelo, como la decodificación, etc.
Algunos modelos base de ejemplo incluyen:
Una tarea contiene un modelo más y un alumno/optimizador más. La subclase de Tarea más simple es SingleTask que requiere los siguientes Hparams:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| Versión PyPI | Comprometerse |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


