BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT es un proyecto exploratorio diseñado para construir incrementalmente un modelo de lenguaje similar a GPT. El proyecto comienza con un modelo Bigram simple y gradualmente incorpora conceptos avanzados de la arquitectura del modelo Transformer.
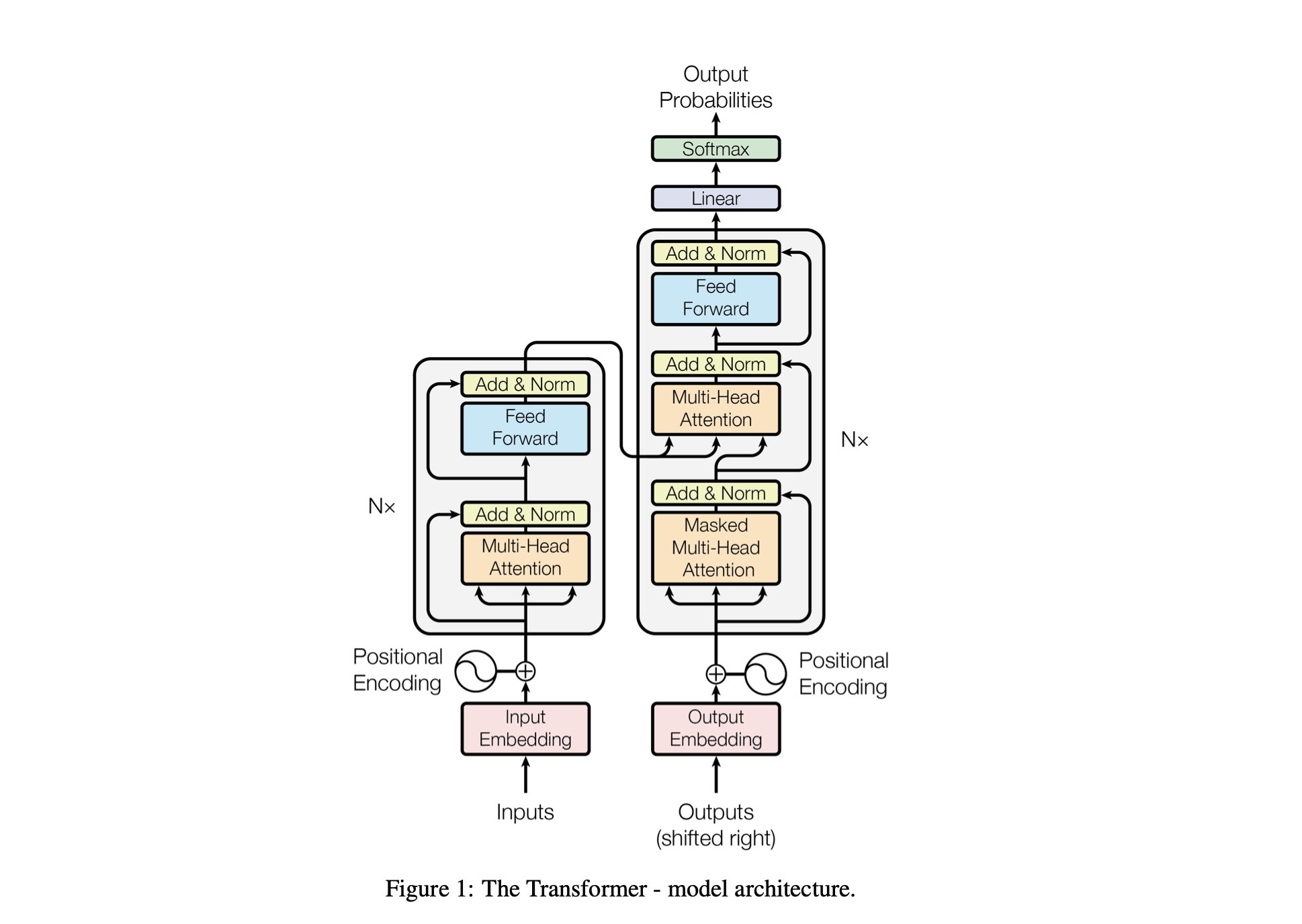
El rendimiento del modelo se ajusta mediante los siguientes hiperparámetros:
batch_size : el número de secuencias procesadas en paralelo durante el entrenamientoblock_size : La longitud de las secuencias que procesa el modelo.d_model : el número de características en el modelo (el tamaño de las incrustaciones)d_k : el número de funciones por cabeza de atención.num_iter : el número total de iteraciones de entrenamiento que ejecutará el modelo.Nx : el número de bloques o capas de transformadores en el modelo.eval_interval : el intervalo en el que se calcula y evalúa la pérdida del modelo.lr_rate : la tasa de aprendizaje del optimizador Adamdevice : se configura automáticamente en 'cuda' si hay una GPU compatible disponible; de lo contrario, el valor predeterminado es 'cpu' .eval_iters : el número de iteraciones sobre las cuales promediar la pérdida de evaluaciónh : El número de cabezas de atención en el mecanismo de atención de múltiples cabezas.dropout_rate : la tasa de abandono utilizada durante el entrenamiento para evitar el sobreajusteEstos hiperparámetros se eligieron cuidadosamente para equilibrar la capacidad del modelo para aprender de los datos sin sobreajuste y para gestionar los recursos computacionales de forma eficaz.
| Hiperparámetro | Modelo de procesador | Modelo de GPU |
|---|---|---|
device | 'UPC' | 'cuda' si está disponible, en caso contrario 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0,005 (5e-3) | 0,001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int e int_to_chars .encode y viceversa con la función decode .train_data ) y validación ( valid_data ).get_batch prepara datos en mini lotes para el entrenamiento.BigramLM .El mini lote es una técnica de aprendizaje automático en la que los datos de entrenamiento se dividen en pequeños lotes. Cada mini lote se procesa por separado durante el entrenamiento del modelo. Este enfoque ayuda en:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Factor | Tamaño de lote pequeño | Tamaño de lote grande |
|---|---|---|
| Ruido degradado | Mayor (más variación en las actualizaciones) | Inferior (actualizaciones más consistentes) |
| Convergencia | Tiende a explorar más soluciones, incluidos mínimos más planos | A menudo converge hacia mínimos más agudos. |
| Generalización | Potencialmente mejor (debido a mínimos más planos) | Potencialmente peor (debido a mínimos más agudos) |
| Inclinación | Menor (es menos probable que se sobreadapte a los patrones de datos de entrenamiento) | Mayor (puede sobreajustarse a los patrones de datos de entrenamiento) |
| Diferencia | Mayor (debido a una mayor exploración en el espacio de soluciones) | Menor (debido a una menor exploración en el espacio de la solución) |
| Costo computacional | Mayor por época (más actualizaciones) | Menor por época (menos actualizaciones) |
| Uso de la memoria | Más bajo | Más alto |
La función estimate_loss calcula la pérdida promedio del modelo durante un número específico de iteraciones (eval_iters). Se utiliza para evaluar el rendimiento del modelo sin afectar sus parámetros. El modelo está configurado en modo de evaluación para deshabilitar ciertas capas, como la deserción, para un cálculo de pérdida consistente. Después de calcular la pérdida promedio de los datos de entrenamiento y validación, el modelo vuelve al modo de entrenamiento. Esta función es esencial para monitorear el proceso de capacitación y realizar ajustes si es necesario.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Codificación posicional : agregar información posicional al modelo con positional_encodings_table en la clase BigramLM . Agregamos codificaciones posicionales a las incrustaciones de nuestros personajes como en la arquitectura del transformador.
Aquí configuramos y utilizamos el optimizador AdamW para entrenar un modelo de red neuronal en PyTorch. El optimizador Adam se prefiere en muchos escenarios de aprendizaje profundo porque combina las ventajas de otras dos extensiones de descenso de gradiente estocástico: AdaGrad y RMSProp. Adam calcula tasas de aprendizaje adaptativo para cada parámetro. Además de almacenar un promedio que decae exponencialmente de gradientes cuadrados pasados como RMSProp, Adam también mantiene un promedio que decae exponencialmente de gradientes pasados, similar al impulso. Esto permite al optimizador ajustar la tasa de aprendizaje para cada peso de la red neuronal, lo que puede conducir a un entrenamiento más eficaz en arquitecturas y conjuntos de datos complejos.
AdamW modifica la forma en que se incorpora la caída de peso en el proceso de optimización, solucionando un problema con el optimizador Adam original donde la caída de peso no está bien separada de las actualizaciones de gradiente, lo que lleva a una aplicación subóptima de la regularización. El uso de AdamW a veces puede dar como resultado un mejor rendimiento del entrenamiento y una generalización a datos invisibles. Elegimos AdamW por su capacidad para manejar la caída de peso de manera más efectiva que el optimizador Adam estándar, lo que podría conducir a un mejor entrenamiento y generalización del modelo.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()La autoatención es un mecanismo que permite al modelo sopesar la importancia de diferentes partes de los datos de entrada de manera diferente. Es un componente clave de la arquitectura Transformer, que permite que el modelo se centre en partes relevantes de la secuencia de entrada para realizar predicciones.
Atención de producto escalar : un mecanismo de atención simple que calcula una suma ponderada de valores en función del producto escalar entre consultas y claves.
Atención de productos escalados : una mejora con respecto a la atención de productos escalables que reduce los productos escalables según la dimensionalidad de las claves, evitando que los gradientes se vuelvan demasiado pequeños durante el entrenamiento.
OneHeadSelfAttention : Implementación de un mecanismo de autoatención de un solo cabezal que permite al modelo atender diferentes posiciones de la secuencia de entrada. La clase SelfAttention muestra la intuición detrás del mecanismo de atención y su versión escalada.
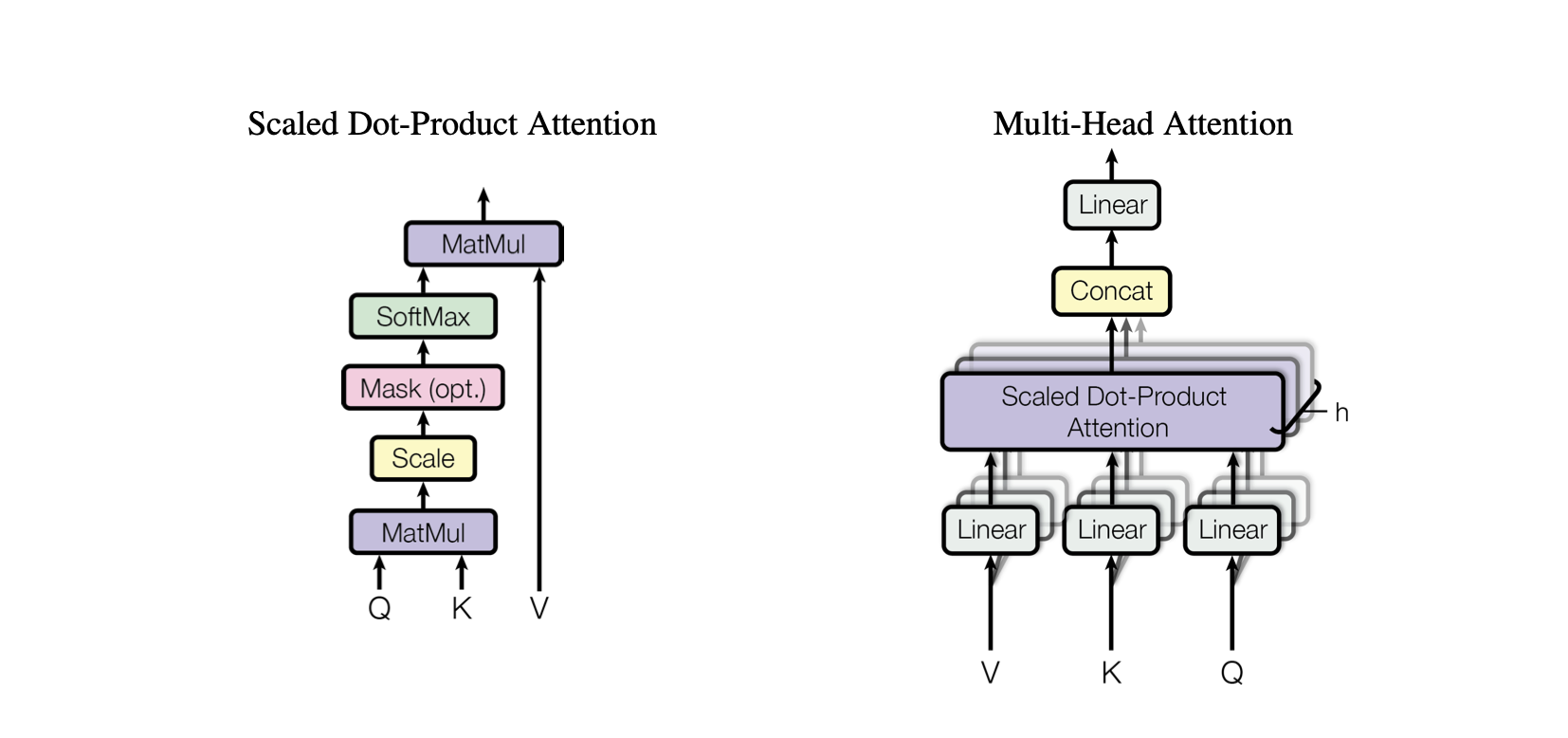
Cada modelo correspondiente en el proyecto Baby GPT se basa progresivamente en el anterior, comenzando con la intuición detrás del mecanismo de autoatención, seguido de implementaciones prácticas de atención de producto punto y producto punto escalado, y culminando con la integración de un modelo único. Módulo de autoatención del cabezal.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur La clase SelfAttention representa un componente fundamental del modelo Transformer, que encapsula el mecanismo de autoatención en un solo cabezal. A continuación se ofrece una visión de sus componentes y procesos:
Inicialización : el constructor __init__(self, d_k) inicializa las capas lineales para claves, consultas y valores, todo con la dimensionalidad d_k . Estas transformaciones lineales proyectan la entrada en diferentes subespacios para cálculos de atención posteriores.
Búfers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) registra una matriz triangular inferior como un búfer persistente que no se considera un parámetro del modelo. Esta matriz se utiliza para enmascarar el mecanismo de atención para evitar que se consideren posiciones futuras en cada paso de cálculo (útil en la autoatención del decodificador).
Pase hacia adelante : el método forward(self, X) define el cálculo realizado en cada llamada del módulo de autoatención.
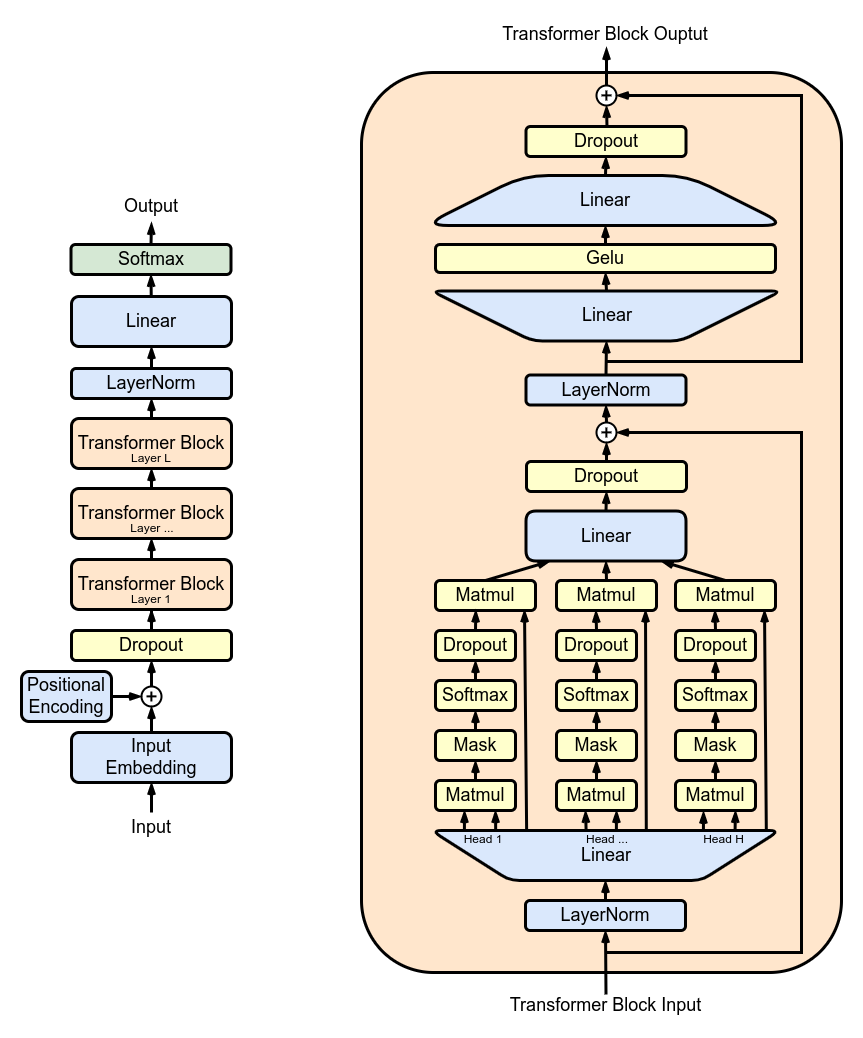
MultiHeadAttention : combina salidas de múltiples cabezales SelfAttention en la clase MultiHeadAttention . La clase MultiHeadAttention es una implementación extendida del mecanismo de autoatención con un cabezal del paso anterior, pero ahora múltiples cabezales de atención operan en paralelo, cada uno de los cuales se enfoca en diferentes partes de la entrada.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : Implementación de una red neuronal feed-forward con activación ReLU dentro de la clase FeedForward . Para agregar esta retroalimentación completamente conectada a nuestro modelo como en el modelo Transformer original.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : apila bloques de transformadores utilizando la clase Block para crear una arquitectura de red más profunda. Profundidad y complejidad: en las redes neuronales, la profundidad se refiere a la cantidad de capas a través de las cuales se procesan los datos. Cada capa adicional (o bloque, en el caso de Transformers) permite a la red capturar características más complejas y abstractas de los datos de entrada.
Procesamiento secuencial: cada bloque Transformer procesa la salida de su bloque anterior, construyendo gradualmente una comprensión más sofisticada de la entrada. Este procesamiento secuencial permite a la red desarrollar una representación profunda y en capas de los datos. Componentes de un bloque transformador
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : mejora de la clase Block para incluir conexiones residuales, mejorando la eficiencia del aprendizaje. Las conexiones residuales, también conocidas como conexiones de salto, son una innovación crítica en el diseño de redes neuronales profundas, particularmente en los modelos Transformer. Abordan uno de los principales desafíos en el entrenamiento de redes profundas: el problema del gradiente evanescente.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Agregar normalización de capas a nuestro Transformer. Normalizar las salidas de las capas con nn.LayerNorm(d_model) en la clase Block .
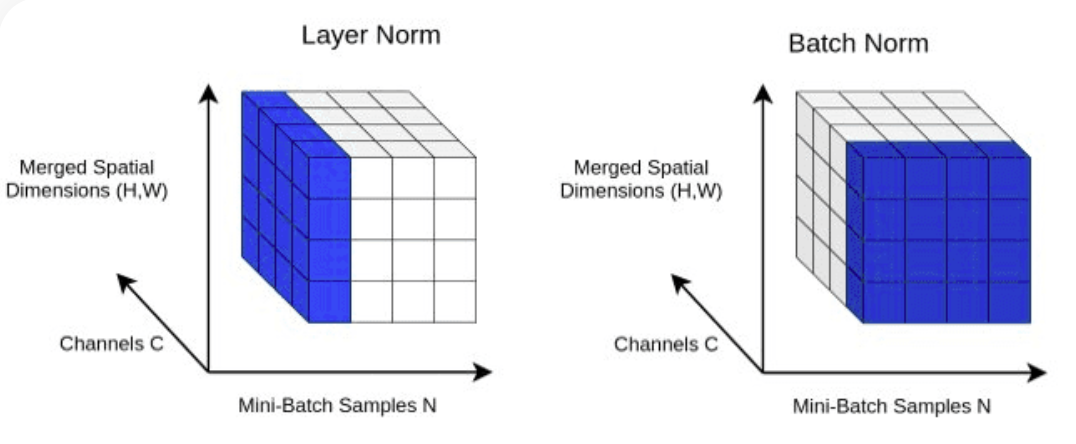
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Abandono : se agregará a las capas SelfAttention y FeedForward como método de regularización para evitar el sobreajuste. Agregamos abandono a:
ScaleUp : aumentar la complejidad del modelo expandiendo batch_size , block_size , d_model , d_k y Nx . Necesitará el kit de herramientas CUDA y una máquina con GPU NVIDIA para entrenar y probar este modelo más grande.
Si desea probar CUDA para la aceleración de GPU, asegúrese de tener instalada la versión adecuada de PyTorch que admita CUDA.
import torch
torch . cuda . is_available ()Puede hacer esto especificando la versión de CUDA en su comando de instalación de PyTorch, como en la línea de comando:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

