ke dialogue
1.0.0


Esta es la implementación del documento:
Aprendizaje de bases de conocimientos con parámetros para sistemas de diálogo orientados a tareas . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung Hallazgos de EMNLP 2020 [PDF]
Si utiliza algún código fuente o conjunto de datos incluidos en este kit de herramientas en su trabajo, cite el siguiente documento. El bibtex se enumera a continuación:
@artículo{madotto2020aprendizaje,
title={Aprendizaje de bases de conocimientos con parámetros para sistemas de diálogo orientados a tareas},
autor={Madotto, Andrea y Cahyawijaya, Samuel y Winata, Genta Indra y Xu, Yan y Liu, Zihan y Lin, Zhaojiang y Fung, Pascale},
diario={arXiv preimpresión arXiv:2009.13656},
año={2020}
}
Los sistemas de diálogo orientados a tareas están modularizados con seguimiento del estado del diálogo (DST) y pasos de gestión separados o se pueden entrenar de un extremo a otro. En cualquier caso, la base de conocimientos (KB) juega un papel esencial para satisfacer las solicitudes de los usuarios. Los sistemas modularizados dependen de DST para interactuar con la base de conocimiento, lo cual es costoso en términos de anotación y tiempo de inferencia. Los sistemas de un extremo a otro utilizan la KB directamente como entrada, pero no pueden escalar cuando la KB tiene más de unos pocos cientos de entradas. En este artículo, proponemos un método para incrustar la KB, de cualquier tamaño, directamente en los parámetros del modelo. El modelo resultante no requiere ningún DST o respuesta de plantilla, ni la KB como entrada, y puede actualizar dinámicamente su KB mediante un ajuste fino. Evaluamos nuestra solución en cinco conjuntos de datos de diálogo orientados a tareas con tamaños de KB pequeños, medianos y grandes. Nuestros experimentos muestran que los modelos de un extremo a otro pueden incorporar eficazmente bases de conocimiento en sus parámetros y lograr un rendimiento competitivo en todos los conjuntos de datos evaluados.
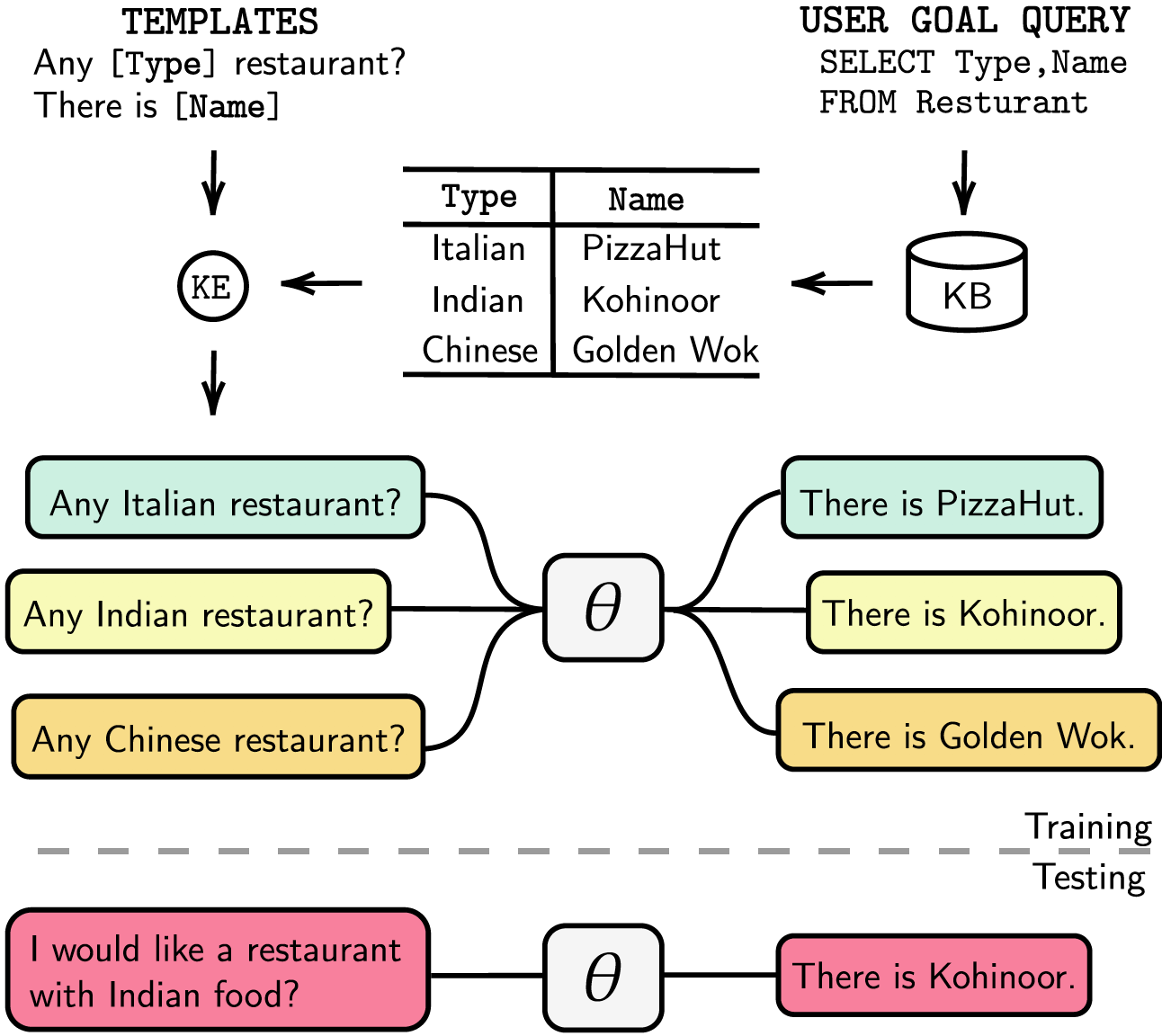
Enumeramos nuestras dependencias en requirements.txt , puede instalar las dependencias ejecutando
❱❱❱ pip install -r requirements.txt Además, nuestro código también incluye compatibilidad con fp16 con apex . Puede encontrar el paquete en https://github.com/NVIDIA/apex.
Conjunto de datos Descargue el conjunto de datos preprocesado y coloque el archivo zip dentro de la carpeta ./knowledge_embed/babi5 . Extraiga el archivo zip ejecutando
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipGenere los diálogos delexicalizados a partir del conjunto de datos bAbI-5 a través de
❱❱❱ python3 generate_delexicalization_babi.pyGenere los datos lexicalizados a partir del conjunto de datos bAbI-5 a través de
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Donde el máximo <num_augmented_knowledge> es 558 (recomendado) y <num_augmented_dialogues> es 264, ya que corresponde a la cantidad de conocimientos y la cantidad de diálogos en el conjunto de datos bAbI-5.
Afinar GPT-2
Proporcionamos el punto de control del modelo GPT-2 ajustado en el conjunto de entrenamiento bAbI. También puede optar por entrenar el modelo usted mismo utilizando el siguiente comando.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Observa que el valor de --kbpercentage es igual a <num_augmented_dialogues> el que proviene de la lexicalización. Este parámetro se utiliza para seleccionar el archivo de aumento para incrustarlo en el conjunto de datos del tren.
Puede evaluar el modelo ejecutando el siguiente script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Puntuación bAbI-5 Para ejecutar el modelo de tareas Scorer for bAbI-5, puede ejecutar el siguiente comando. Scorer leerá todo el result.json en la carpeta de runs generada a partir de evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Conjunto de datos
Descargue el conjunto de datos preprocesado y coloque el archivo zip en la carpeta ./knowledge_embed/camrest . Descomprima el archivo zip ejecutando
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipGenere los diálogos delexicalizados a partir del conjunto de datos CamRest a través de
❱❱❱ python3 generate_delexicalization_CAMREST.pyGenere los datos lexicalizados del conjunto de datos CamRest a través de
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Donde el máximo <num_augmented_knowledge> es 201 (recomendado) y <num_augmented_dialogues> es 156, bastante grande ya que corresponde a la cantidad de conocimientos y la cantidad de diálogos en el conjunto de datos de CamRest.
Afinar GPT-2
Proporcionamos el punto de control del modelo GPT-2 ajustado en el conjunto de entrenamiento CamRest. También puede optar por entrenar el modelo usted mismo utilizando el siguiente comando.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Observa que el valor de --kbpercentage es igual a <num_augmented_dialogues> el que proviene de la lexicalización. Este parámetro se utiliza para seleccionar el archivo de aumento para incrustarlo en el conjunto de datos del tren.
Puede evaluar el modelo ejecutando el siguiente script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Scoring CamRest Para ejecutar el goleador para el modelo de tareas bAbI 5, puede ejecutar el siguiente comando. Scorer leerá todo el result.json en la carpeta de runs generada a partir de evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Conjunto de datos
Descargue el conjunto de datos preprocesado y colóquelo en la carpeta ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipAfinar GPT-2
Proporcionamos el punto de control del modelo GPT-2 ajustado en el conjunto de entrenamiento SMD. Descargue el punto de control y colóquelo en la carpeta ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsTambién puede optar por entrenar el modelo usted mismo utilizando el siguiente comando.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Preparar diálogos integrados en conocimiento
En primer lugar, necesitamos crear bases de datos para consultas SQL.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Luego generamos diálogos basados en plantillas prediseñadas por dominios. El siguiente comando le permite generar diálogos en el dominio weather . Reemplace weather con navigate o schedule en dialogue_path y argumentos domain si desea generar diálogos en los otros dos dominios. También puede cambiar la cantidad de plantillas utilizadas en el proceso de relexicalización cambiando el argumento num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testAdapte el modelo GPT-2 ajustado al equipo de prueba
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""También puede acelerar el proceso de ajuste ejecutando experimentos en paralelo. Modifique la configuración de GPU en el n.° L14 del código.
❱❱❱ python runner_expe_SMD.py Conjunto de datos
Descargue el conjunto de datos preprocesado y colóquelo en la carpeta ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipPrepare diálogos integrados en conocimiento (puede omitir este paso si ha descargado el archivo zip anterior)
Puede preparar los conjuntos de datos ejecutando
❱❱❱ bash generate_MWOZ_all_data.shEl script de shell genera los diálogos delexicalizados a partir del conjunto de datos MWOZ llamando
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyAfinar GPT-2
Proporcionamos el punto de control del modelo GPT-2 ajustado en el conjunto de entrenamiento MWOZ. Descargue el punto de control y colóquelo en la carpeta ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsTambién puede optar por entrenar el modelo usted mismo utilizando el siguiente comando.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Primeros pasos Utilizamos la edición del servidor comunitario neo4j y la biblioteca apoc para procesar datos gráficos. apoc se usa para paralelizar la consulta en neo4j , de modo que podamos procesar gráficos a gran escala más rápido
Antes de continuar con la sección del conjunto de datos, debe asegurarse de tener instalados neo4j (https://neo4j.com/download-center/#community) y apoc (https://neo4j.com/developer/neo4j-apoc/). en su sistema.
Si no está familiarizado con las sintaxis CYPHER y apoc , puede seguir el tutorial en https://neo4j.com/developer/cypher/ y https://neo4j.com/blog/intro-user-defined-procedures-apoc/
Conjunto de datos Descargue el conjunto de datos original y coloque el archivo zip dentro de la carpeta ./knowledge_embed/opendialkg . Extraiga el archivo zip ejecutando
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipGenere los diálogos delexicalizados a partir del conjunto de datos opendialkg a través de ( ADVERTENCIA : esto requiere alrededor de 12 horas para ejecutarse)
❱❱❱ python3 generate_delexicalization_DIALKG.py Este script producirá ./opendialkg/dialogkg_train_meta.pt que se utilizará para generar el diálogo lexicalizado. Luego puede generar el diálogo lexicalizado a partir del conjunto de datos opendialkg a través de
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Este script producirá muestras de diálogos como máximo muestras batch_size * max_iter , pero en cada lote existe la posibilidad de que no haya un candidato válido y que se obtengan menos muestras. El número de generación está limitado por otro factor llamado stop_count que detendrá la generación si el número de muestras generadas es mayor que el stop_count especificado. El archivo producirá 4 archivos: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv y ./opendialkg/generation_iteration_{random_seed}.csv que se utilizan para comprobar el cambio de distribución del contar en la base de datos; y ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json que contiene las muestras generadas.
Notas :
neo4j dentro de generate_delexicalization_DIALKG.py y generate_dialogues_DIALKG.py manualmente.Afinar GPT-2
Proporcionamos el punto de control del modelo GPT-2 ajustado en el conjunto de entrenamiento opendialkg. También puede optar por entrenar el modelo usted mismo utilizando el siguiente comando.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Observa que el valor de --kbpercentage es igual a <random_seed> el que proviene de la lexicalización. Este parámetro se utiliza para seleccionar el archivo de aumento para incrustarlo en el conjunto de datos del tren.
Puede evaluar el modelo ejecutando el siguiente script
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Puntuación OpenDialKG Para ejecutar el marcador para el modelo de tareas bAbI-5, puede ejecutar el siguiente comando. Scorer leerá todo el result.json en la carpeta de runs generada a partir de evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Para obtener detalles sobre los experimentos, hiperparámetros y resultados de la evaluación, puede encontrarlos en el artículo principal y en los materiales complementarios de nuestro trabajo.


