EcoAssistant
1.0.0
EcoAssistant: utilizar el asistente LLM de forma más asequible y precisa
¡Consulta nuestro blog en el sitio web de AutoGen!
Una versión simplificada con la última versión de AutoGen se encuentra en simplified_demo.py
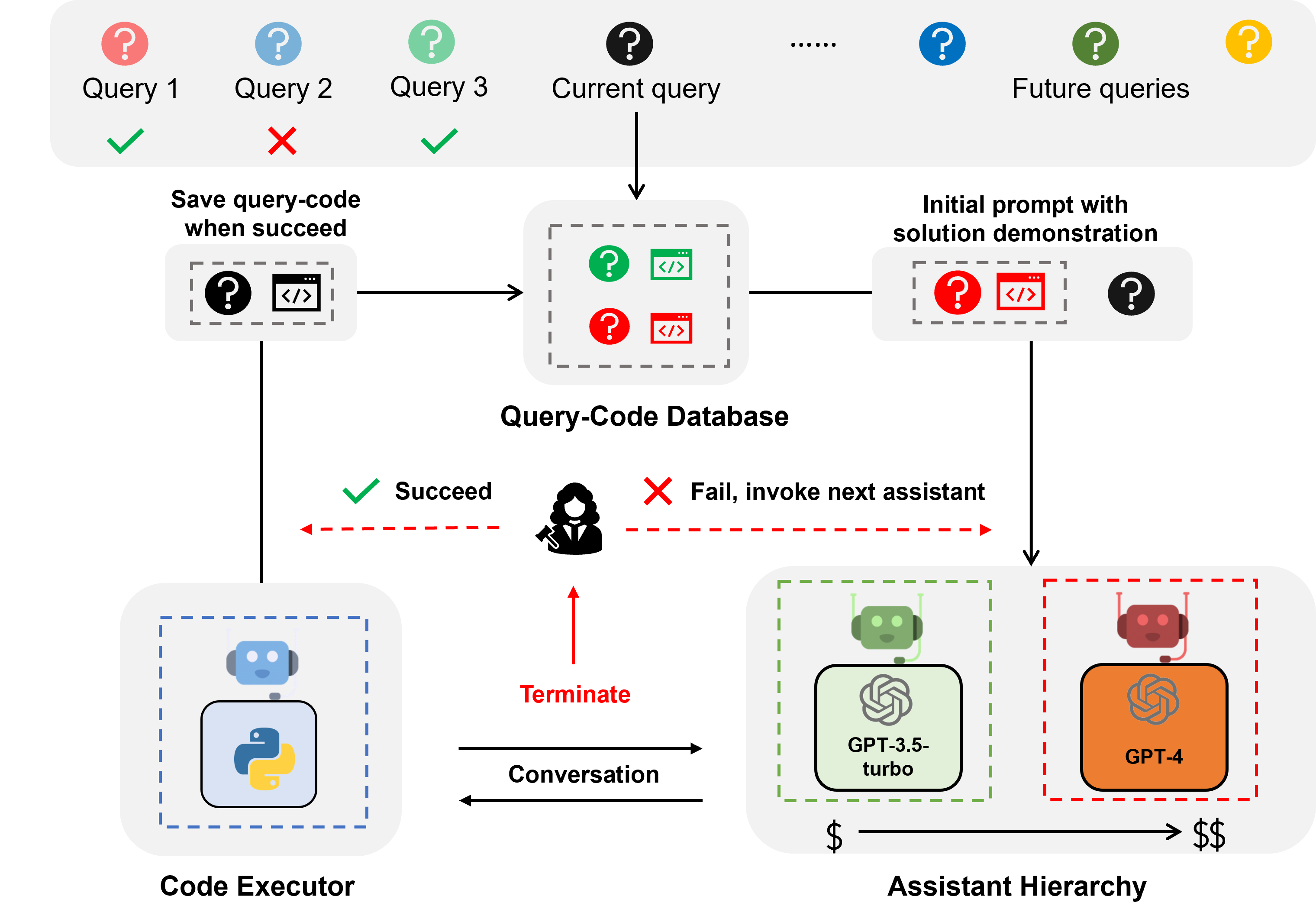
EcoAssistant es un marco que puede hacer que el asistente LLM sea más asequible y preciso para responder preguntas basadas en código. Se basa en la idea de jerarquía de asistentes y demostración de soluciones . Está construido sobre AutoGen.
El asistente LLM es un agente asistente respaldado por LLM conversacional como ChatGPT y GPT-4 y puede abordar las consultas del usuario en una conversación.
La respuesta a preguntas basada en código es una tarea que requiere que el asistente de LLM escriba código para llamar a API externas para responder la pregunta. Por ejemplo, dada la pregunta "¿Cuál será la temperatura promedio de la ciudad X en los próximos 5 días?", el asistente necesita escribir código para obtener información meteorológica a través de ciertas APIS y calcular la temperatura promedio de la ciudad X en los próximos 5 días. 5 días.
La respuesta a preguntas basada en código requiere codificación iterativa porque, al igual que los humanos, LLM difícilmente puede escribir el código correcto en el primer intento. Por lo tanto, el asistente necesita interactuar con el usuario para obtener comentarios y revisar el código de forma iterativa hasta que sea correcto. Construimos nuestro sistema en un marco de conversación de dos agentes , donde el asistente LLM se combina con un agente ejecutor de código que puede ejecutar automáticamente el código y devolver el resultado al asistente LLM.
La jerarquía de asistentes es una jerarquía de asistentes, donde los asistentes de LLM se clasifican según su costo (por ejemplo, GPT-3.5-turbo -> GPT-4). Al atender una consulta de un usuario, el EcoAssistant primero le pide al asistente más barato que responda la consulta. Sólo cuando falla invocamos al asistente más caro. Está diseñado para ahorrar costos al reducir el uso de asistentes costosos.
La demostración de la solución es una técnica que aprovecha el par de código de consulta exitoso del pasado para ayudar en consultas futuras. Cada vez que una consulta se aborda con éxito, guardamos el par de código de consulta en una base de datos. Cuando llega una nueva consulta, recuperamos la consulta más similar de la base de datos y luego usamos la consulta y su código asociado como demostración en contexto. Está diseñado para mejorar la precisión aprovechando los pares de código de consulta exitosos del pasado.
La combinación de jerarquía de asistentes y demostración de la solución amplifica los beneficios individuales porque la solución del modelo de alto rendimiento se aprovecharía naturalmente para guiar el modelo más débil sin diseños específicos.
Para consultas sobre el clima, existencias y lugares, EcoAssistant supera al asistente individual GPT-4 en 10 puntos de tasa de éxito con menos del 50% del costo de GPT-4. Se pueden encontrar más detalles en nuestro artículo.
Todos los datos están incluidos en este repositorio.
Solo necesita configurar sus claves API en keys.json
Instale las bibliotecas necesarias (recomendamos Python3.10):
pip3 install -r requirements.txtUsamos el conjunto de datos Mixed-100 como ejemplo. Para otro conjunto de datos, simplemente cambie el nombre del conjunto de datos a google_places/stock/weather/mixed_1/mixed_2/mixed_3 en los siguientes comandos.
Los resultados de salida se pueden encontrar en la carpeta de results .
Los siguientes comandos son para los sistemas autónomos sin retroalimentación humana descritos en la Sección 4.5.
Ejecute el asistente GPT-3.5-turbo
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo Ejecute el asistente turbo GPT-3.5 + Cadena de pensamiento
encender cot
python3 run.py --data mixed_100 --seed 0 --api --cot --model gpt-3.5-turbo Ejecute el asistente GPT-3.5-turbo + demostración de la solución
activar solution_demonstration
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo Ejecute la jerarquía de asistentes (GPT-3.5-turbo + GPT-4)
configurar model en gpt-3.5-turbo,gpt-4
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo,gpt-4Ejecute EcoAssistant: jerarquía de asistentes (GPT-3.5-turbo + GPT-4) + demostración de la solución
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4Habilitar la retroalimentación humana
Para sistemas con criterio humano, configure eval en human (que es llm por defecto) como en el siguiente comando de ejemplo.
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4 --eval humanEjecute el código dorado para Mixed-100 que recopilamos como se describe en la Sección 4.4
Este script imprimiría los resultados del código.
python3 run_gold_code_for_mix_100.pySi encuentra útil este repositorio, considere citar:
@article { zhang2023ecoassistant ,
title = { EcoAssistant: Using LLM Assistant More Affordably and Accurately } ,
author = { Zhang, Jieyu and Krishna, Ranjay and Awadallah, Ahmed H and Wang, Chi } ,
journal = { arXiv preprint arXiv:2310.03046 } ,
year = { 2023 }
}

