ContraCLM
1.0.0
Este repositorio contiene código para el artículo de ACL 2023, ContraCLM: Aprendizaje contrastivo para el modelo de lenguaje causal.
Trabajo realizado por: Nihal Jain*, Dejiao Zhang*, Wasi Uddin Ahmad*, Zijian Wang, Feng Nan, Xiaopeng Li, Ming Tan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Xiaofei Ma, Bing Xiang. (* indica contribución igual ).
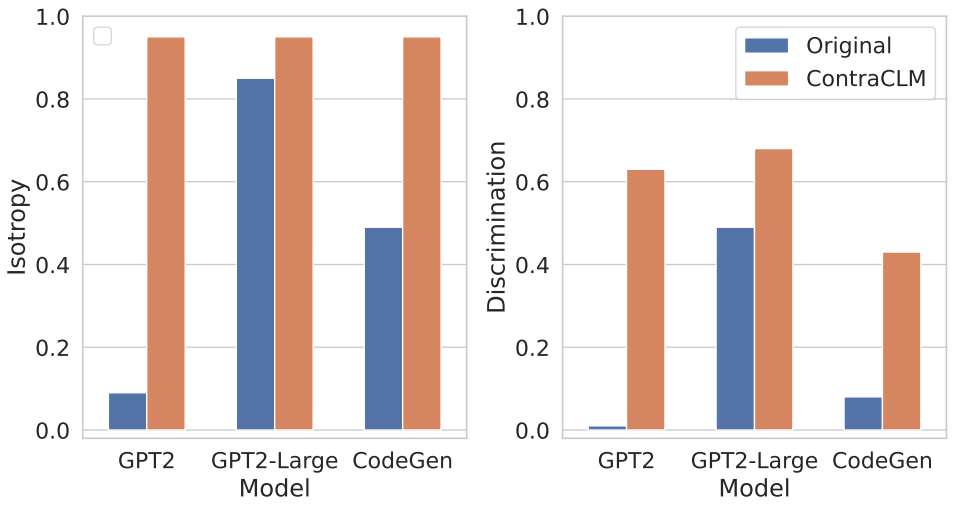
Presentamos ContraCLM, un novedoso marco de aprendizaje contrastivo que opera tanto a nivel de token como de secuencia. ContraCLM mejora la discriminación de representaciones de un modelo de lenguaje solo decodificador y cierra la brecha con los modelos solo codificador, haciendo que los modelos de lenguaje causal sean más adecuados para tareas más allá de la generación del lenguaje. Le recomendamos que consulte nuestro documento para obtener más detalles.
La configuración implica instalar las dependencias necesarias en un entorno y colocar los conjuntos de datos en el directorio requerido.
Ejecute estos comandos para crear un nuevo entorno conda e instalar los paquetes necesarios para este repositorio.
# create a new conda environment with python >= 3.8
conda create -n contraclm python=3.8.12
# install dependencies within the environment
conda activate contraclm
pip install -r requirements.txtVer aquí.
En esta sección, mostramos cómo utilizar este repositorio para preparar previamente (i) GPT2 en datos de lenguaje natural (NL) y (ii) CodeGen-350M-Mono en datos de lenguaje de programación (PL).
Esta sección asume que tiene los datos de entrenamiento y validación almacenados en TRAIN_DIR y VALID_DIR respectivamente, y que está dentro de un entorno con todas las dependencias anteriores instaladas (consulte Configuración).
Puede obtener una descripción general de todos los indicadores asociados con el entrenamiento previo ejecutando:
python pl_trainer.py --helpGPT2 en datos de NL bash runscripts/run_wikitext.sh
CL_Config=$(eval echo ${options[1]}) dentro del script.CodeGen-350M-Mono en datos PL Configure las variables en la parte superior de runscripts/run_code.sh . Hay muchas opciones, pero aquí solo se explican las opciones de abandono (otras se explican por sí solas):
dropout_p : El valor de probabilidad de abandono utilizado en torch.nn.Dropout
dropout_layers : Si > 0, esto activará los últimos dropout_layers con probabilidad dropout_p
functional_dropout : si se especifica, utilizará una capa de abandono funcional encima de las representaciones de token generadas por el modelo CodeGen.
Configure la variable CL según la configuración del modelo deseado. Asegúrese de que las rutas a TRAIN_DIR, VALID_DIR estén configuradas como se desea.
Ejecute el comando: bash runscripts/run_code.sh
Consulte los directorios específicos de tareas relevantes aquí.
Si utiliza nuestro código en su investigación, cite nuestro trabajo como:
@inproceedings{jain-etal-2023-contraclm,
title = "{C}ontra{CLM}: Contrastive Learning For Causal Language Model",
author = "Jain, Nihal and
Zhang, Dejiao and
Ahmad, Wasi Uddin and
Wang, Zijian and
Nan, Feng and
Li, Xiaopeng and
Tan, Ming and
Nallapati, Ramesh and
Ray, Baishakhi and
Bhatia, Parminder and
Ma, Xiaofei and
Xiang, Bing",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.355",
pages = "6436--6459"
}
Consulte CONTRIBUCIÓN para obtener más información.
Este proyecto está bajo la licencia Apache-2.0.


