todo-ai
¿Su asistente de chatbot local, totalmente competente y con tecnología de inteligencia artificial?
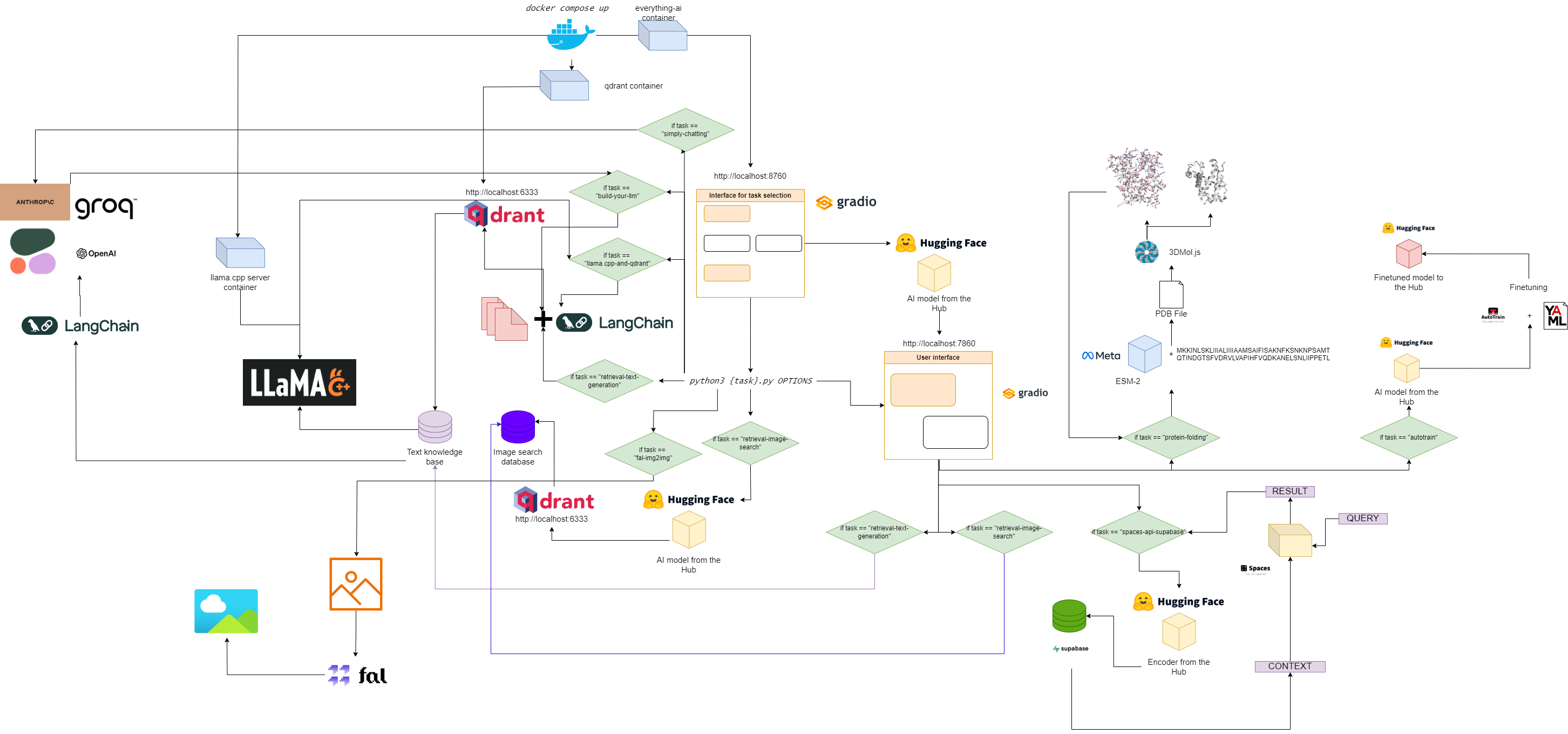
Diagrama de flujo para todo-ai
Inicio rápido
1. Clonar este repositorio
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Configure su archivo .env
Modificar:
- Variable
VOLUME en el archivo .env para que pueda montar su sistema de archivos local en el contenedor Docker. -
MODELS_PATH en el archivo .env para que pueda indicarle a llama.cpp dónde almacenó los modelos GGUF que descargó. - Variable
MODEL en el archivo .env para que pueda indicarle a llama.cpp qué modelo usar (use el nombre real del archivo gguf y no olvide la extensión .gguf). - Variable
MAX_TOKENS en el archivo .env para que pueda indicarle a llama.cpp cuántos tokens nuevos puede generar como salida.
Un ejemplo de un archivo .env podría ser:
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Esto significa que ahora todo lo que está bajo "c:/Users/User/" en su máquina local está bajo "/User/" en su contenedor Docker, ese llama.cpp sabe dónde buscar modelos y qué modelo buscar. junto con el máximo de tokens nuevos para su producción.
3. Extrae las imágenes necesarias.
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Ejecute la aplicación de contenedores múltiples
5. Vaya a localhost:8670 y elija su asistente.
Verás algo como esto:
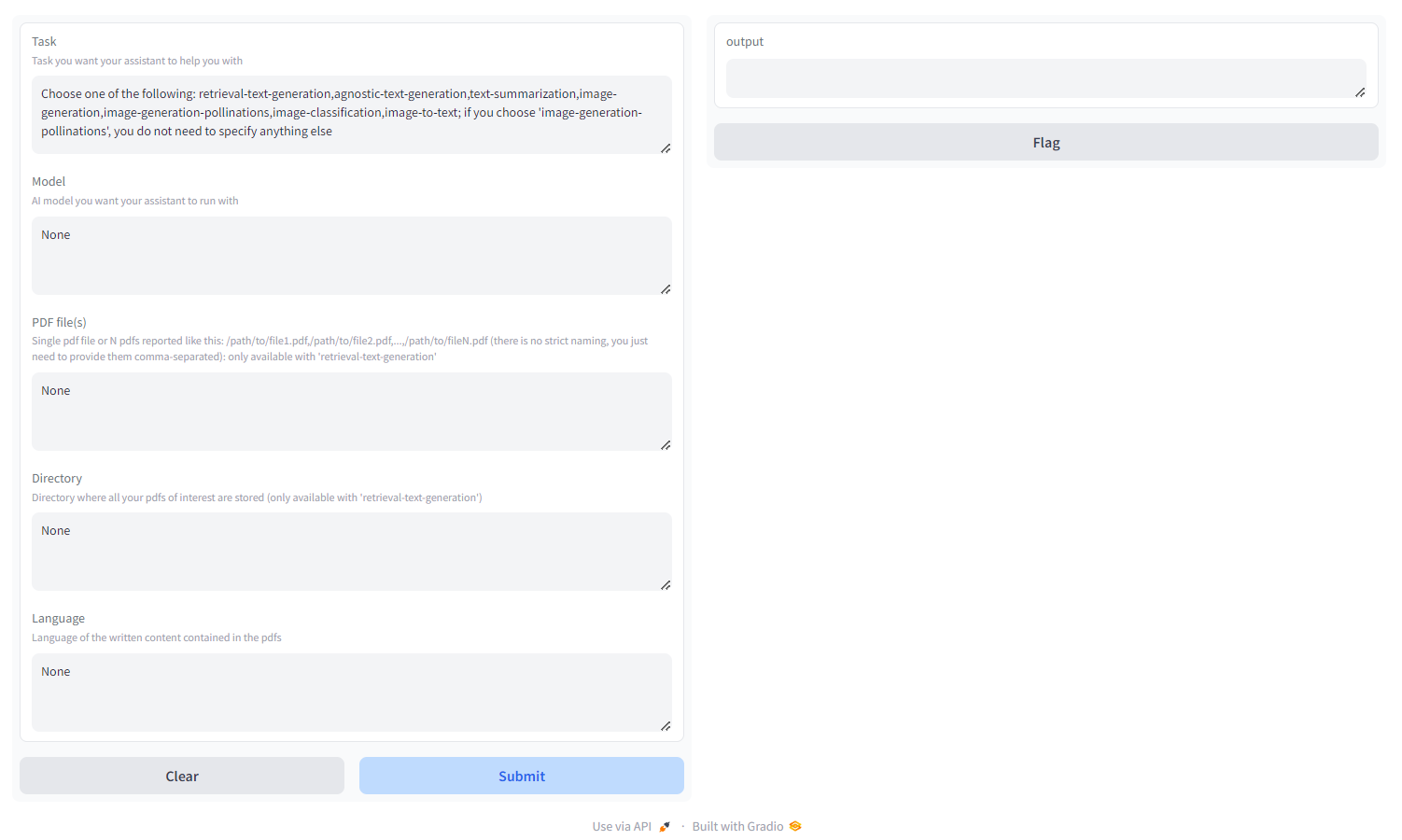
Elige la tarea entre:
- recuperación-generación de texto : utilice el backend
qdrant para crear una base de conocimientos fácil de recuperar, en la que puede consultar y ajustar la respuesta de su modelo. Debe pasar un pdf/un grupo de pdf especificados como rutas separadas por comas o un directorio donde se almacenan todos los pdf de interés ( NO proporcione ambos); también puedes especificar el idioma en el que está escrito el PDF, usando la nomenclatura ISO - MULTILINGÜE - generación de texto agnóstico : generación de texto similar a ChatGPT (sin arquitectura de recuperación), pero admite todos los modelos de generación de texto en HF Hub (¡siempre que su hardware lo admita!) - MULTILINGÜE
- resumen de texto : resume texto y archivos PDF, admite todos los modelos de resumen de texto en HF Hub - SOLO INGLÉS
- Generación de imágenes : difusión estable, admite todos los modelos de texto a imagen en HF Hub - MULTILINGÜE
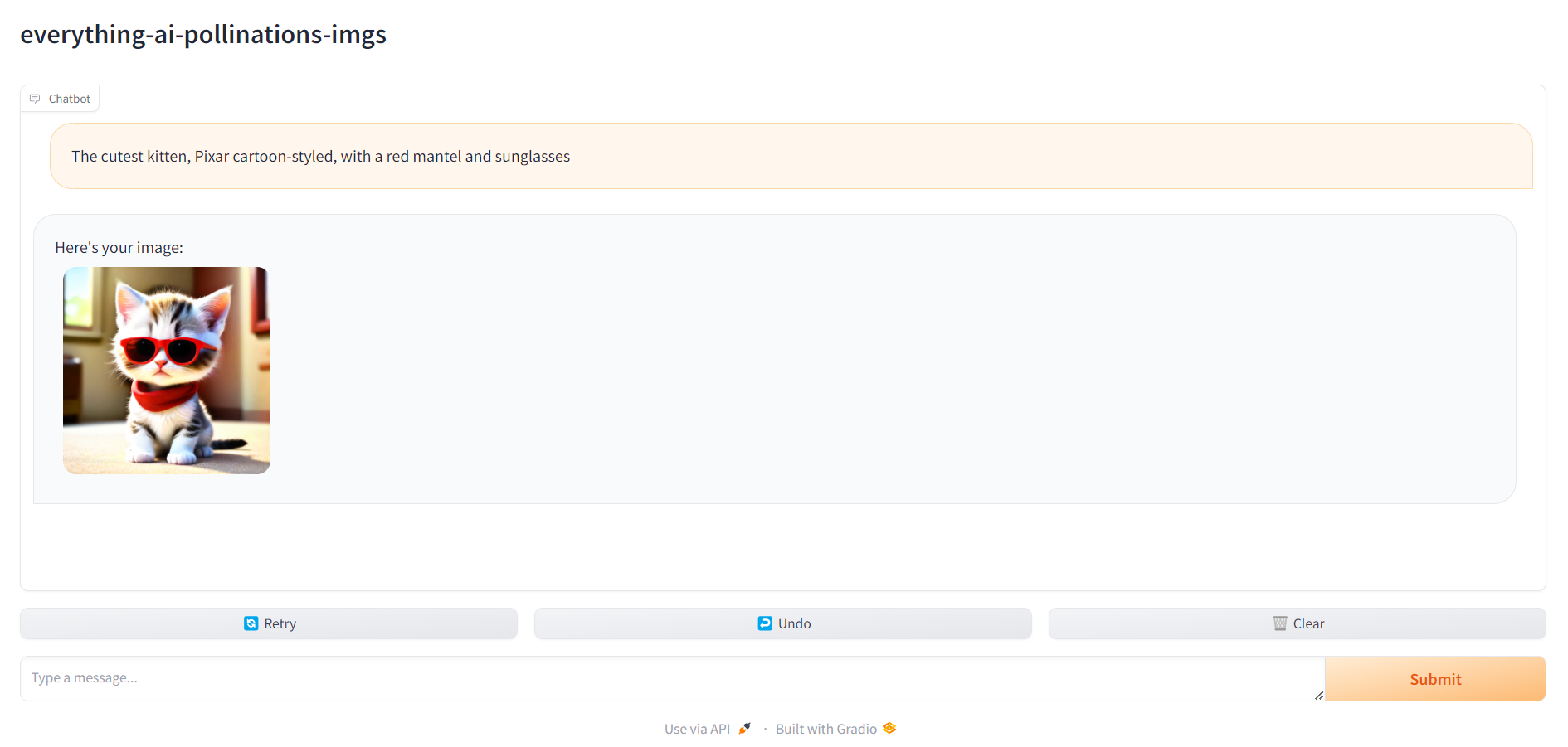
- polinizaciones de generación de imágenes : difusión estable, utilice la API de polinizaciones AI; Si elige 'polinizaciones-generación de imágenes', no necesita especificar nada más aparte de la tarea - MULTILINGÜE
- clasificación de imágenes : clasifica una imagen, admite todos los modelos de clasificación de imágenes en HF Hub - SOLO INGLÉS
- Imagen a texto : describe una imagen, admite todos los modelos de imagen a texto en HF Hub - SOLO INGLÉS
- clasificación de audio : clasifica archivos de audio o grabaciones de micrófono, admite modelos de clasificación de audio en el concentrador HF
- reconocimiento de voz : transcribe archivos de audio o grabaciones de micrófono, admite modelos de reconocimiento automático de voz en el concentrador HF.
- Generación de video : genera video cuando aparece un mensaje de texto, admite modelos de texto a video en el concentrador HF - SÓLO EN INGLÉS
- plegamiento de proteínas : obtenga la estructura 3D de una proteína a partir de su secuencia de aminoácidos, utilizando el modelo de columna vertebral ESM-2 - SOLO GPU
- autotrain : ajuste un modelo en una tarea posterior específica con autotrain-advanced, simplemente especificando su nombre de usuario HF, token de escritura HF y la ruta a un archivo de configuración yaml para el entrenamiento.
- espacios-api-supabase : use HF Spaces API en combinación con las bases de datos Supabase PostgreSQL para liberar LLM más potentes y bases de datos vectoriales orientadas a RAG más grandes - MULTILINGÜE
- llama.cpp-and-qdrant : igual que retrieval-text-spawn , pero usa llama.cpp como motor de inferencia, por lo que NO DEBE especificar un modelo - MULTILINGÜE
- build-your-llm : cree un LLM de chat personalizable que combine una base de datos Qdrant con sus archivos PDF y el poder de los modelos Anthropic, OpenAI, Cohere o Groq: ¡solo necesita una clave API! Para construir la base de datos Qdrant, debe pasar un pdf/un grupo de pdf especificados como rutas separadas por comas o un directorio donde se almacenan todos los pdf de interés ( NO proporcione ambos); también puede especificar el idioma en el que está escrito el PDF, utilizando la nomenclatura ISO - MULTILINGÜE , INTEGRACIÓN LANGFUSE
- simplemente chatear : cree un LLM de chat personalizable con el poder de los modelos Anthropic, OpenAI, Cohere o Groq (sin canalización RAG): ¡solo necesita una clave API! - INTEGRACIÓN MULTILINGÜE Y LANGFUSE
- fal-img2img : Utilice fal.ai ComfyUI API para generar imágenes a partir de sus imágenes PNG y JPEG: ¡solo necesita una clave API! También puedes personalizar la generación trabajando con indicaciones y semillas - SOLO INGLÉS
- búsqueda-recuperación de imágenes : busca en una base de datos de imágenes cargando una carpeta como entrada de la base de datos. La carpeta debe tener la siguiente estructura:
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Puede consultar la base de datos a partir de sus propias imágenes.
6. Vaya a localhost:7860 y comience a usar su asistente.
Una vez que todo esté listo, puedes dirigirte a localhost:7860 y comenzar a usar tu asistente: